
数据中心网络:详谈CLOS、Dragonfly、Torus架构如何演进?


据Hyperion Research 公司按照系统验收的时间估算,2021至2026年期间,全球将建成28~38台E级或接近 E 级的超级计算机。本文参考自“总线级数据中心网络技术白皮书”。
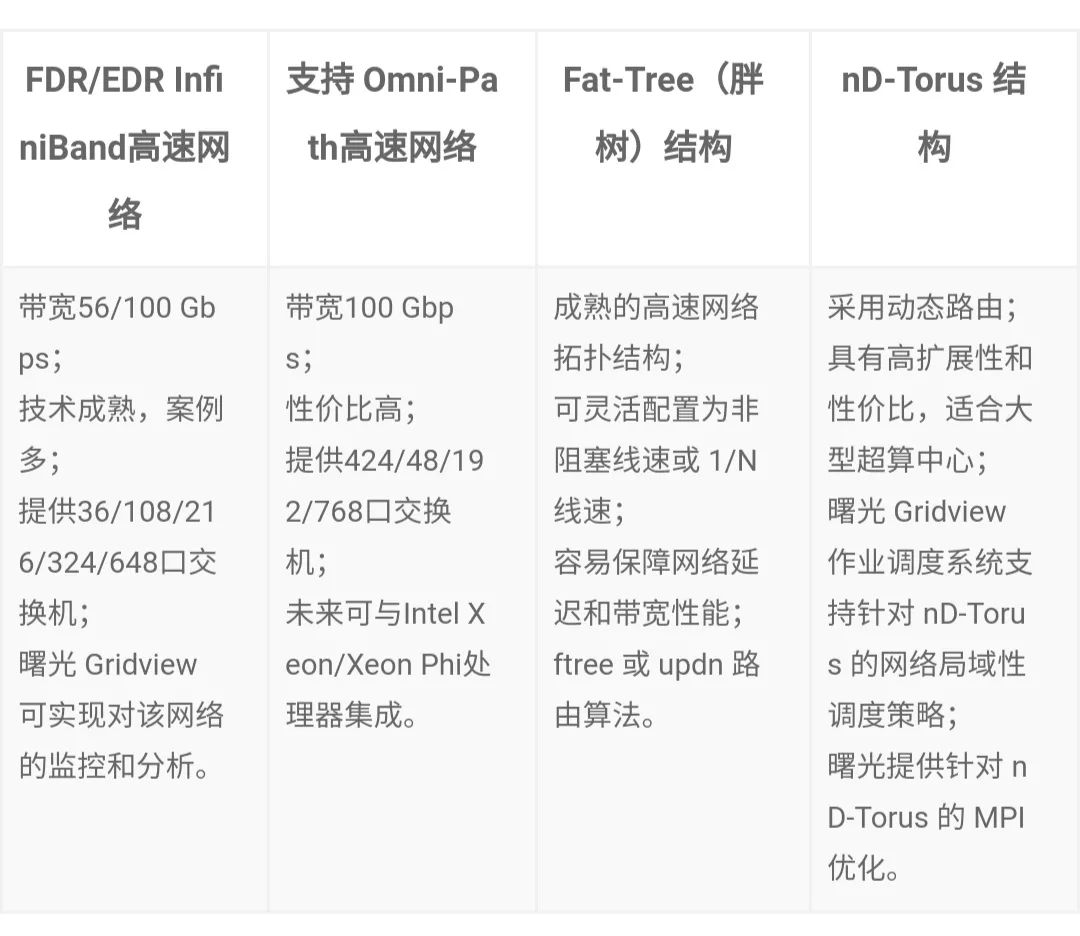
在原先传统数据中心内,计算存储性能未提升前,端到端的时延主要在端侧,即计算和存储所消耗的时延占比较大,而当计算存储器件性能大幅提升后,网络成为了数据中心内端到端的性能瓶颈。下图显示了计算存储性能提升前后,端到端时延的占比变化。
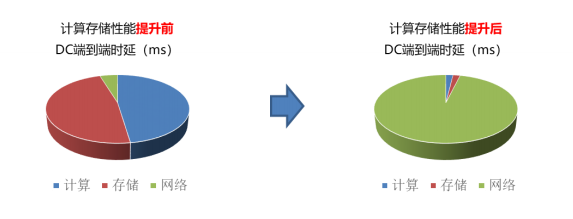
➢零拷贝(Zero-copy) - 应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。 ➢内核旁路(Kernel bypass) - 应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。 ➢不需要 CPU 干预(No CPU involvement) - 应用程序可以访问远程主机内存而不消耗远程主机中的任何 CPU。远程主机内存能够被读取而不需要远程主机上的进程(或 CPU)参与。远程主机的 CPU 的缓存(cache)不会被访问的内存内容所填充。 ➢消息基于事务(Message based transactions) - 数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。 ➢支持分散/聚合条目(Scatter/gather entries support) - RDMA 原生态支持分散/聚合。也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
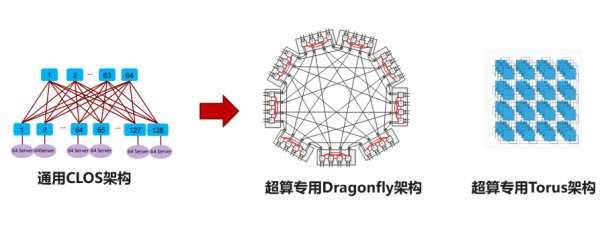
动态时延:主要由排队时延产生,受端口拥塞影响; 静态时延:主要包括网络转发(查表)时延和转发接口时延,一般为固定值,当前以太交换静态时延远高于超算专网; 网络跳数:指消息在网络中所经历的设备数; 入网次数:指消息进入网络的次数。总线级数据中心网络在动态时延、静态时延、网络跳数以及入网次数几个方面均作出了系统性的优化,大幅优化了网络性能,已满足高性能计算场景的实际诉求。
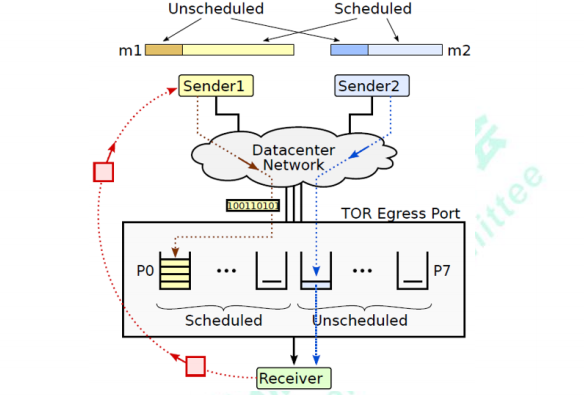
最大吞吐保证:仅优先发送部分报文,同样提供最大吞吐保证。 极低平均队列时延:通过接收端调度,严格控制网络注入流量,保证接近于0的平均队列时延。 极低最大队列时延:对于不由接收端调度的报文,通过窗口限制注入流量,不会出现大幅震荡,保证最大队列时延极低。
来源:全栈云技术架构
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言删除,谢谢。
温馨提示:
搜索关注“全栈云技术架构”微信公众号,“扫码”或点击“阅读原文”进入知识星球获取1000+份技术资料。

评论