
详谈:pNFS增强文件系统架构
点击上方“开源Linux”,选择“设为星标”
回复“学习”获取独家整理的学习资料!
通过 NFS(由服务器、客户机软件和两者之间的协议组成),一台计算机就可以和同一网络中的其他计算机共享物理文件系统。NFS 隐藏服务器的文件系统的实现和类型。对于在 NFS 客户机上运行的应用程序,共享的文件系统看起来和本地存储一样。
下图演示了在包含各种操作系统的网络中部署 NFS 的一般方法。这些操作系统包括支持 NFS 标准的 Linux、Mac OS X 和 Windows (NFS 是 Internet Engineering Task Force 惟一支持的文件系统)。
简单的NFS配置
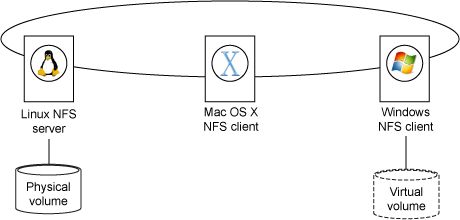
在图中,Linux 机器是 NFS 服务器,它共享或导出(用 NFS 的话讲)一个或多个物理附带文件系统。Mac OS X 和 Windows 机器是 NFS 客户机。它们分别使用或挂载 共享的文件系统。实际上,挂载 NFS 文件系统和挂载本地驱动分区的结果是一样的 — 在挂载时,应用程序仅根据访问控制读写文件,而不注意持久化数据所需的技巧。
对于通过 NFS 进行共享的文件系统,Read 和 Write 操作 — 由蓝色阴影表示 — 从客户机(这里是 Windows 机器)遍历到服务器。这个服务器最终执行获取或持久化数据的请求或修改文件元数据的请求,比如权限或最后的修改时间。
NFS 的功能非常强大,从广泛将它用作NAS就可以看出来。它可以在 TCP)和UDP上运行,并且相对容易管理。此外,NFS 的最新许可版本是 NFS v4,它提高了安全性、增强了 Windows 和类 UNIX® 系统之间的互操作性,并且通过锁租赁提供更好的排他性(NFSv4 于 2003 年首次获得批准)。NFS 的基础设施也不昂贵,因为它通常能在普通的 Ethernet 硬件上很好地运行。NFS 能够解决大部分的问题。
不过,NFS 处理高性能计算HPC一直不够理想。高性能计算涉及到的数据文件非常庞大,并且 NFS 客户机的数量可能达到几千台(想一想拥有数千个计算节点的计算集群或网格)。在这里,NFS 是一个负担,因为 NFS 服务器的局限性 — 比如带宽、存储容量和处理器速度 — 限制了总体计算性能。NFS 在这里成了瓶颈。或者,至少以前 是这样。
NFS 的下一个修改版是 v4.1,包括一个扩展 pNFS,它将普通 NFS 的优势和并行I/O的高传输率结合起来。使用 pNFS 时,客户机也像以前一样可以从服务器共享文件系统,但数据不经过 NFS 服务器。相反,客户机系统将与数据存储系统直接连接,为大型数据传输提供许多并行的高速数据路径。在简短的初始化和握手过程之后,pNFS 服务器开始退出 “舞台”,不再阻碍传输速率。
图 2 显示一个 pNFS 配置。顶部是计算集群的节点,比如大量便宜的、基于 Linux 的刀片服务器群。左边是 NFSv4.1 服务器(为了方便讨论,我们称之为 pNFS 服务器)。底部是一个大型的并行文件系统。
图 2. pNFS 的概念组织结构
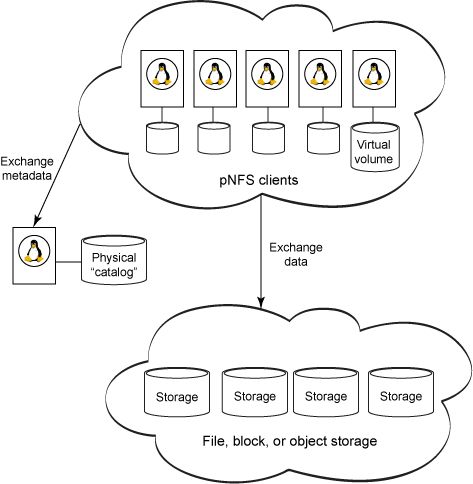
像NFS 一样,pNFS 服务器也导出文件系统,并且保留和维护数据仓库中描述每个文件的标准元数据。pNFS 客户机和 NFS 一样 — 在这里是集群中的一个节点 — 挂载服务器导出的文件系统。类似于 NFS,每个节点都将文件系统看作本地的物理附加文件系统。元数据的更改通过网络传回给 pNFS 服务器。然而,与 NFS 不同的是,pNFS 在 Read 或 Write 数据时是在节点和存储系统之间直接 操作的,如图 2 的底部所示。从数据事务中移除 pNFS 服务器为 pNFS 提供了明显的性能优势。
因此,pNFS 保留了 NFS 的所有优点,并且改善了性能和可伸缩性。扩展存储系统的容量几乎不会影响客户机配置,同时还可以增加客户机的数量以提高计算能力。您只需同步 pNFS 目录和存储系统。
pNFS 的具体细节
那么,它是如何工作的呢?如图 3 所示,pNFS 是由 3 个协议构成的。
图 3. pNFS 的 3 个协议
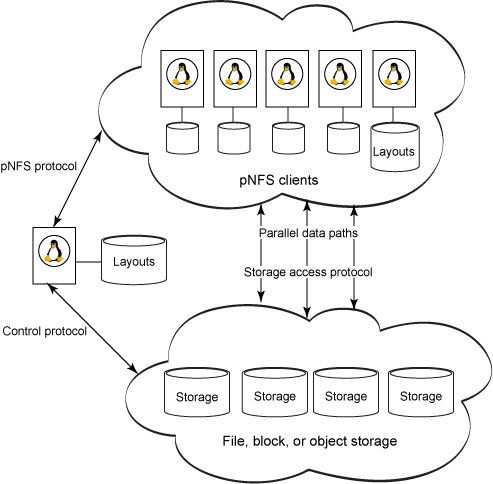
pNFS 协议在 pNFS 服务器和客户机节点之间传输文件元数据(正式名称是布局)。可以将布局想象成地图,它描述如何在数据仓库之间分配文件。另外,布局还包含许可和其他文件属性。布局捕捉到元数据并在 pNFS 服务器中持久化这些数据之后,存储系统仅需执行 I/O。
存储访问协议 指定客户机从数据仓库访问数据的方式。可以猜到,每个存储访问协议都定义自己的布局形式,因为访问协议和数据组织必须保持一致。
控制协议同步元数据服务器和数据服务器之间的状态。同步是对客户机隐藏的,比如重新组织介质上的文件。此外,NFSv4.1 并没有规定控制协议;因此它有多种形式,这在性能、成本和特性方面的竞争为供应商提供了灵活性。有了这些协议之后,您就可以实践以下客户机访问流程:
客户机为当前的文件请求一个布局。
客户机通过打开元数据服务器上的文件获得访问权。
客户机获得授权和布局之后,就可以直接从数据服务器访问信息。根据存储类型所需的存储访问协议,访问继续进行。(后面还对此进行论述)。
如果客户机更改了这个文件,则会相应地更改布局的客户机实例,并且将所有更改提交回到元数据服务器。
当客户机不再需要这个文件时,它将提交剩余的更改,并将布局副本返回给元数据服务器,然后关闭文件。
尤其需要注意的是,Read 操作是由一系列协议操作组成的:
客户机向 pNFS 服务器发送一个 LOOKUP+OPEN 请求。服务器会返回一个文件句柄和状态信息。
客户机通过 LAYOUTGET 命令请求从服务器获取一个布局。服务器将返回所需的文件布局。
客户机向存储设备发出一个 READ 请求,该请求同时初始化多个 Read 操作。
当客户机完成读操作时,它以 LAYOUTRETURN 表示操作结束。
如果与客户机共享的布局因为分离活动而过时,服务器将发出 CB_LAYOUTRECALL,表明该布局无效,必须清除和/或重新获取。
Write 操作类似于 Read 操作,不同的地方是客户机必须在 LAYOUTRETURN 将文件更改 “发布” 到 pNFS 服务器之前发出 LAYOUTCOMMIT。
布局可以缓存到每个客户机,这进一步提升了性能。如果一个客户机不再使用时,它会自动放弃从服务器获取布局。服务器还能限制 Write 布局的字节范围,以避免配额限制或减少分配开销等等。
为了避免缓存过期,元数据服务器将收回不准确的布局。收回发生之后,每个关联的客户机必须停止 I/O,并且必须重新获取布局或从普通的 NFS 访问文件。在服务器尝试管理文件(比如迁移或重新划分)之前必须执行回收过程。
如前所述,每个存储访问协议都定义一个布局类型,并且可以随意添加新的访问协议和布局。为了使 pNFS 可以独立使用,pNFS 的供应商和研究人员已经定义了 3 种存储技巧:文件、块 和对象 存储:
文件存储 通常是由传统的 NFS 服务器实现的,比如由 Network Appliance 生成的服务器。存储群是由一组 NFS 服务器组成的,并且每个文件都跨越所有服务器或服务器的子集,从而使客户机能够同时获取文件的各个部分。在这里,布局枚举持有文件片段的服务器、每个服务器上文件片段的大小,以及每个片段的 NFS 文件句柄。
块存储 通常是使用由许多磁盘或 RAID 阵列组成的存储区域网络(SAN)来实现的。许多供应商都提供 SAN 解决方案,包括 IBM 和 EMC。有了块存储之后,文件可以被划分为块并分布到不同的驱动器中。块存储布局将文件块映射到物理存储块。存储访问协议就是 SCSI 块命令集。
对象存储 类似于文件存储,但有一点不同,这里使用的是对象 ID 而不是文件句柄,并且文件分割功能更加复杂强大。发起 pNFS 开发的 Panasas 公司(pNFS 基于该公司的 DirectFLOW 架构)是 pNFS 对象实现的主要创造者。
不管布局的类型是什么,pNFS 都使用通用的模式来引用服务器。引用服务器时使用的是惟??的 ID,而不是主机名或卷名。这个 ID 被映射到特定于访问协议的服务器引用。
对于这些存储技术,哪个最好呢?答案是 “依情况而定”。应该采用哪种存储技术由预算、速度、伸缩性、简单性等因素共同决定。
我们来看看pNFS 的现状,截至 2008 年 11 月撰写此文为止,NFSv4.1 的 Request for Comments (RFC) 草案已经进入最后阶段。这个阶段有两个月的时间,主要任务是在发布 RFC 使其经受全行业的检验之前收集和评估意见。发布之后,RFC 的正式审核期是一年。
除了对公众公开以外,这个草案采用的 RFC 标准为实际产品开发打下坚实的基础。因为在将来的审核期只可以对这些标准进行小的改动,所以供应商现在就可以设计和构建可行的、有市场价值的解决方案。许多供应商的产品将于明年上市。
可以这样说,在几个月之内,您可以找到 pNFS 的开源实现。Panasas 和密歇根大学信息技术集成中心(CITI)是开发 NFSv4.1 和 pNFS for Linux 的领先者。当它们发布时,早期采用者可以通过构建简单的 pNFS 网络来探索该软件。
实际上,pNFS 的前身和基础技术已经投入使用,虽然受到限制但表现不俗。世界上最快的超级计算机(在Top 500调查中排名第一),同时也是第一台达到一个Petaflop 的计算机使用 Panasas 构建的并行文件系统,该系统是 pNFS 标准的核心。这个运行 Linux 的庞大系统位于 Los Alamos National Laboratory,拥有 12,960 个处理器,它被授予称号Roadrunner,并且是第一台使用不同类型处理器的超级计算机,AMD Opteron X64 处理器和 IBM 的 Cell Broadband Engine都提升了计算能力。
在 2006 年,使用 Panasas 早期并行文件系统的 Roadrunner 的传输速率峰值是 1.6 GB 每秒。在 2008 年,Roadrunner 并行存储系统能够维持数百 GB每秒的速率。相比之下,传统的 NFS 的峰值一般是几百兆字节每秒。
NFSv4.1标准和pNFS是NFS 标准的巨大改进,它是对一个拥有 20 多年历史的老技术的最大改动,该技术由 Sun Microsystems 的 Bill Joy 在 20 世纪 80 年代发明。经过 5 年的开发,NFSv4.1 和 pNFS 现在已经准备好为超级计算机提供超级存储速度。
关注「开源Linux」加星标,提升IT技能