
揭开KPI异常检测顶级AI模型面纱(3)
我是hitTeam,有幸在华为运营商BG全球技术服务部、华为NAIE产品部举办的2020GDE全球开发者大赛·KPI异常检测中获得二等奖,在这里跟大家分享本次比赛的方案和收获。
01
赛事简介
02
赛题分析
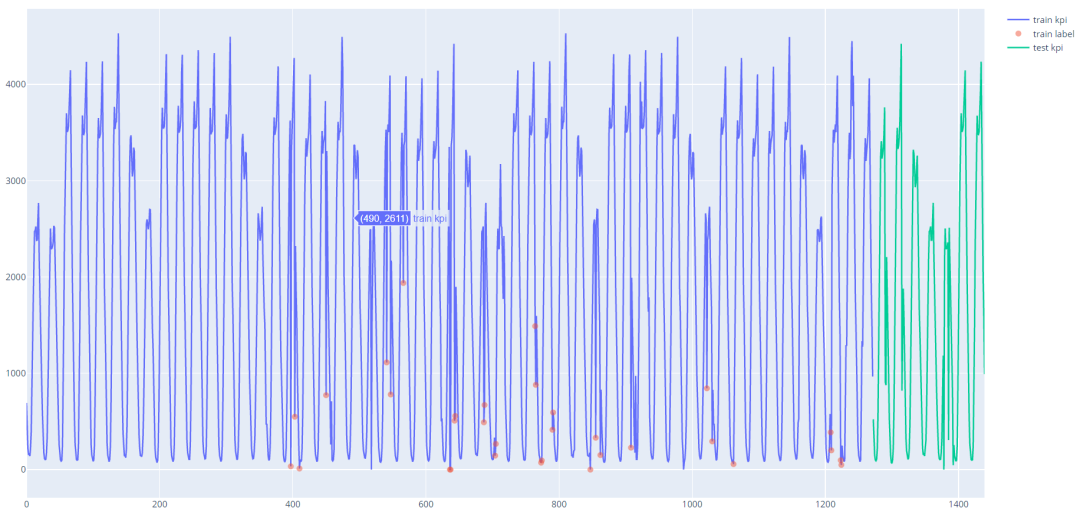
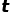 时候的值
时候的值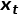 是否为异常时, 都是模型根据历史的信息,预测或者重构出当前时刻点的值
是否为异常时, 都是模型根据历史的信息,预测或者重构出当前时刻点的值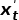 , 然后根据
, 然后根据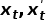 两点的之间的差距大小来判断是否为异常, 差距越大,越有可能为异常。如下图所示, 1,2两个异常点偏离原来的轨迹交大, 使用预测或者重构出来的会与有较大的差距, 所以这两个点能够比较容易地检测出来。但是对于点3这种偏离程度不是很大的情况, 重构出来的会与没有很大的差距,这两种无监督的异常检测方法对它无能为力。
两点的之间的差距大小来判断是否为异常, 差距越大,越有可能为异常。如下图所示, 1,2两个异常点偏离原来的轨迹交大, 使用预测或者重构出来的会与有较大的差距, 所以这两个点能够比较容易地检测出来。但是对于点3这种偏离程度不是很大的情况, 重构出来的会与没有很大的差距,这两种无监督的异常检测方法对它无能为力。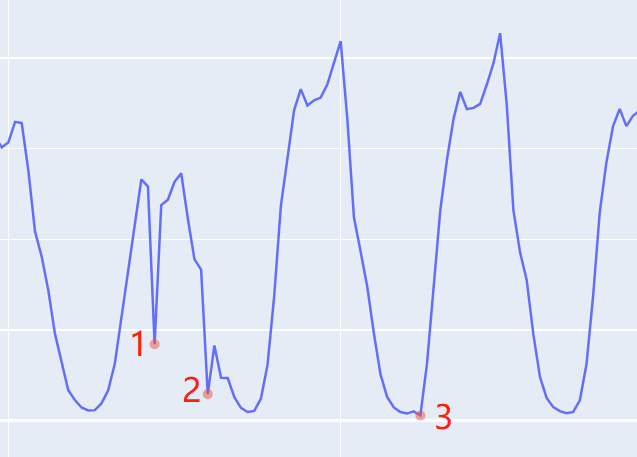
03
赛题思路
1
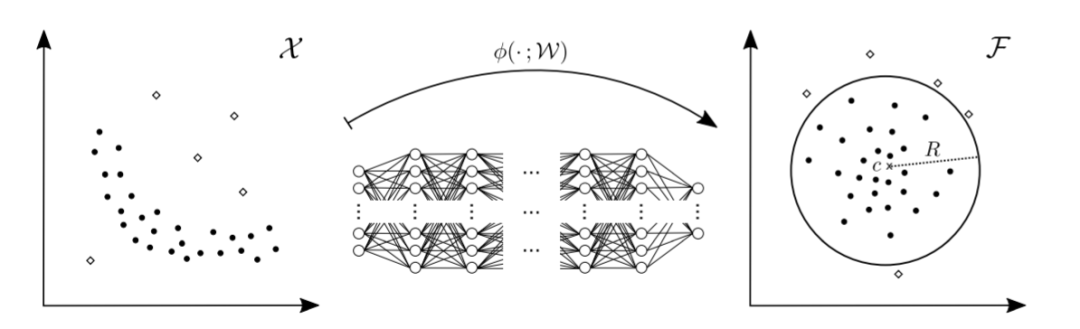
 将样本从输入空间
将样本从输入空间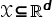 映射到输出空间
映射到输出空间 。使得在隐空间
。使得在隐空间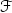 上, 正常样本聚集类中心
上, 正常样本聚集类中心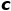 附近。在测试时, 如果一个样本距离正常类中心太远, 就认定为异常。
附近。在测试时, 如果一个样本距离正常类中心太远, 就认定为异常。不择手段一:充分利用标签信息。
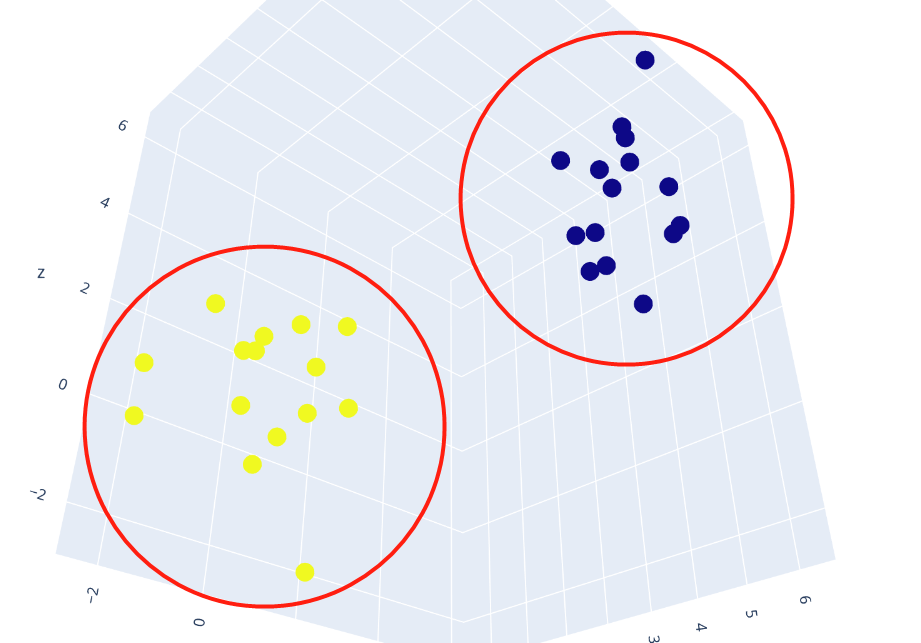 , 我构建的神经网络很简单, 只有三层:
, 我构建的神经网络很简单, 只有三层:nn.Linear(input_size, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 64),
nn.ReLU(inplace=True),
nn.Linear(64, output_size))
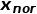 , 所有的异常样本为
, 所有的异常样本为 , 使用 神经网络分别将他们映射到输出空间:
, 使用 神经网络分别将他们映射到输出空间: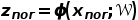
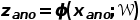
# 计算两个类簇的中心
nor_center = torch.mean(z_nor, dim=0)
ano_center = torch.mean(z_ano, dim=0)
# 两类中心远离, 最大化dist
dist = torch.sum((nor_center - ano_center) ** 2)
# 类内聚集, 最小化nor_dis + ano_dis
nor_dis = torch.sum((nor_center - z_nor) ** 2)
ano_dis = torch.sum((ano_center - z_ano) ** 2)
# 综合以上两点, 整体的loss
loss = (nor_dis + ano_dis) - dist
if dist.item() > max_dis:
Lambda = 0.9
loss = Lambda * (nor_dis + ano_dis) - (1 - Lambda) * dist

不择手段二:调整不同的滑动窗口大小和选取标签的位置。
 , 一般是使用窗口内的点组成的序列
, 一般是使用窗口内的点组成的序列 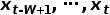 ,取这个窗口内最后一个点的标签作为这个窗口的标签;在本次比赛中, 可以不局限于取这个窗口的最后一点的标签作为这个这窗口的标签,只要能够提升模型的检测效果, 我可以取窗口中的任意一个点的标签作为这个窗口的标签。
,取这个窗口内最后一个点的标签作为这个窗口的标签;在本次比赛中, 可以不局限于取这个窗口的最后一点的标签作为这个这窗口的标签,只要能够提升模型的检测效果, 我可以取窗口中的任意一个点的标签作为这个窗口的标签。不择手段三:不同的参数组合。
04
判断异常的方式
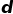 , 确定一个阈值
, 确定一个阈值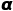 , 当
, 当 就判定该样本为异常。
就判定该样本为异常。05
相邻异常点
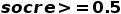 判定为异常, 那么得到的结果是point-wise alert这一行的结果。采用以上的评分方法, 经过调整之后的结果为adjusted alert这一行的结果。
判定为异常, 那么得到的结果是point-wise alert这一行的结果。采用以上的评分方法, 经过调整之后的结果为adjusted alert这一行的结果。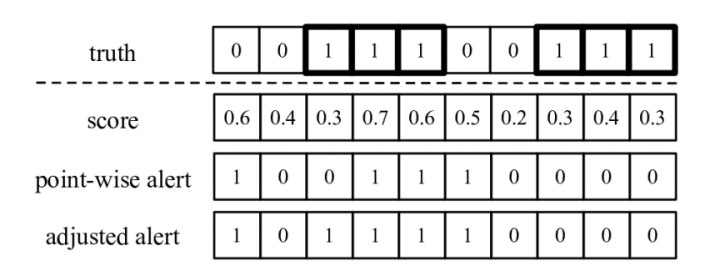
06
其他常规操作
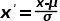
07
总 结
加群交流学习
评论