
JuiceFS 源码阅读-上
JuiceFS 源码阅读-上
最近研究文件系统,把近期比较火的JuiceFS代码翻出来看了一下,研究为啥其性能要比CephFS要好。
背景知识
参考资源:https://mp.weixin.qq.com/s/HvbMxNiVudjNPRgYC8nXyg
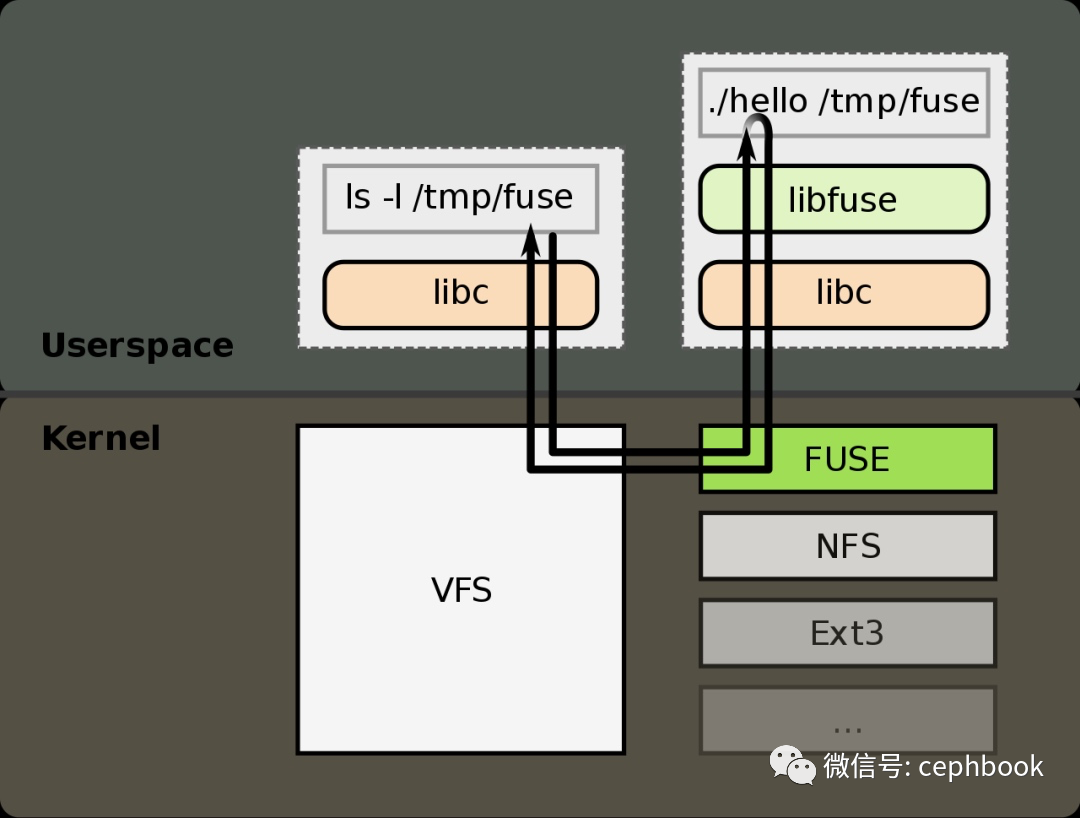
FUSE 是一个用来实现用户态文件系统的框架,这套 FUSE 框架包含 3 个组件:
内核模块 fuse.ko :用来接收 vfs 传递下来的 IO 请求,并且把这个 IO 封装之后通过管道发送到用户态;
用户态 lib 库 libfuse :解析内核态转发出来的协议包,拆解成常规的 IO 请求;
mount 工具 fusermount ;
背景:一个用户态文件系统,挂载点为 /tmp/fuse ,用户二进制程序文件为 ./hello ;当执行 ls -l /tmp/fuse 命令的时候,流程如下:
IO 请求先进内核,经 vfs 传递给内核 FUSE 文件系统模块;
内核 FUSE 模块把请求发给到用户态,由 ./hello 程序接收并且处理。处理完成之后,响应原路返回;
JuiceFS架构简介
JuiceFS 由三个部分组成:
JuiceFS 客户端:协调对象存储和元数据存储引擎,以及 POSIX、Hadoop、Kubernetes、S3 Gateway 等文件系统接口的实现;
数据存储:存储数据本身,支持本地磁盘、对象存储;
元数据引擎:存储数据对应的元数据,支持 Redis、MySQL、SQLite 等多种引擎;
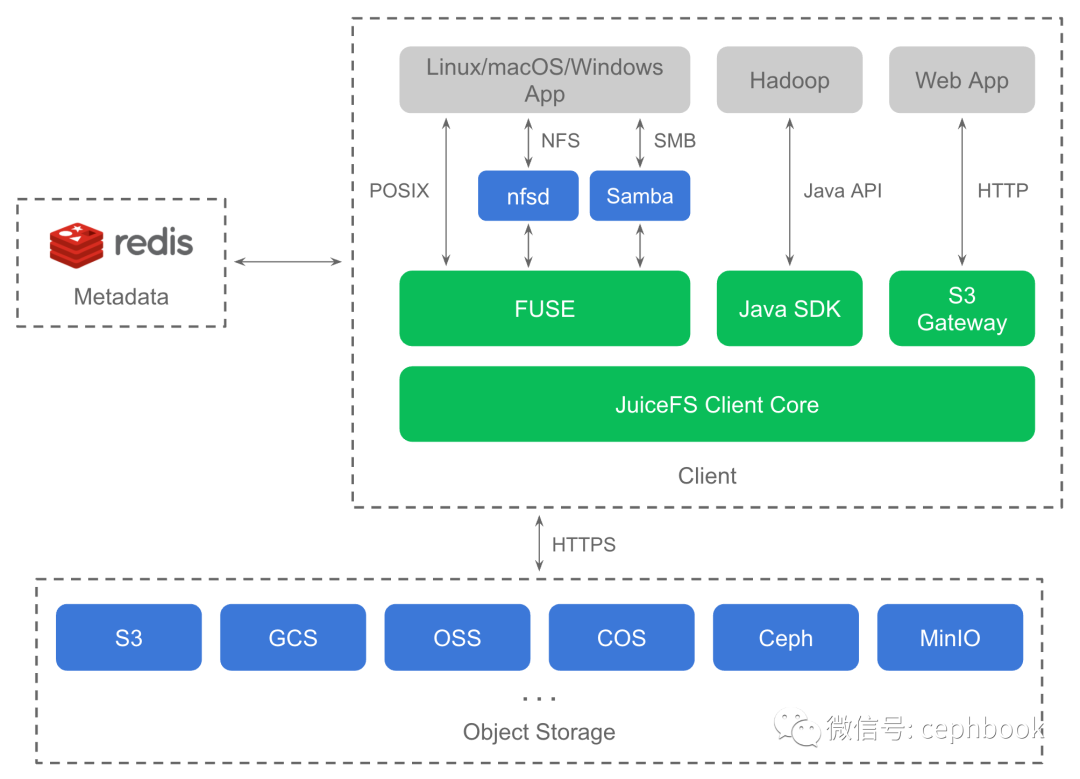
JuiceFS 依靠 Redis 来存储文件的元数据。Redis 是基于内存的高性能的键值数据存储,非常适合存储元数据。与此同时,所有数据将通过 JuiceFS 客户端存储到对象存储中。
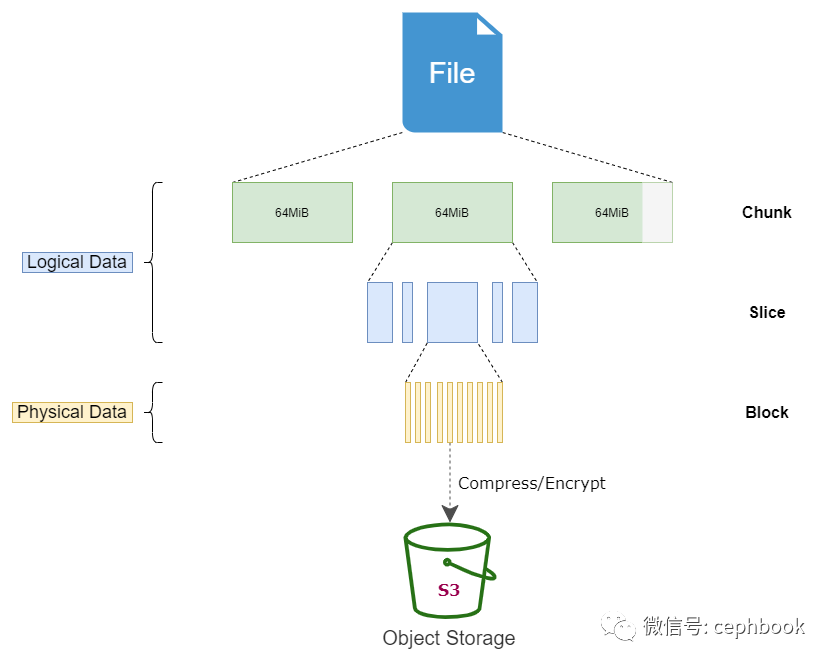
任何存入 JuiceFS 的文件都会被拆分成固定大小的 "Chunk",默认的容量上限是 64 MiB。每个 Chunk 由一个或多个 "Slice" 组成,Slice 的长度不固定,取决于文件写入的方式。每个 Slice 又会被进一步拆分成固定大小的 "Block",默认为 4 MiB。最后,这些 Block 会被存储到对象存储。与此同时,JuiceFS 会将每个文件以及它的 Chunks、Slices、Blocks 等元数据信息存储在元数据引擎中。
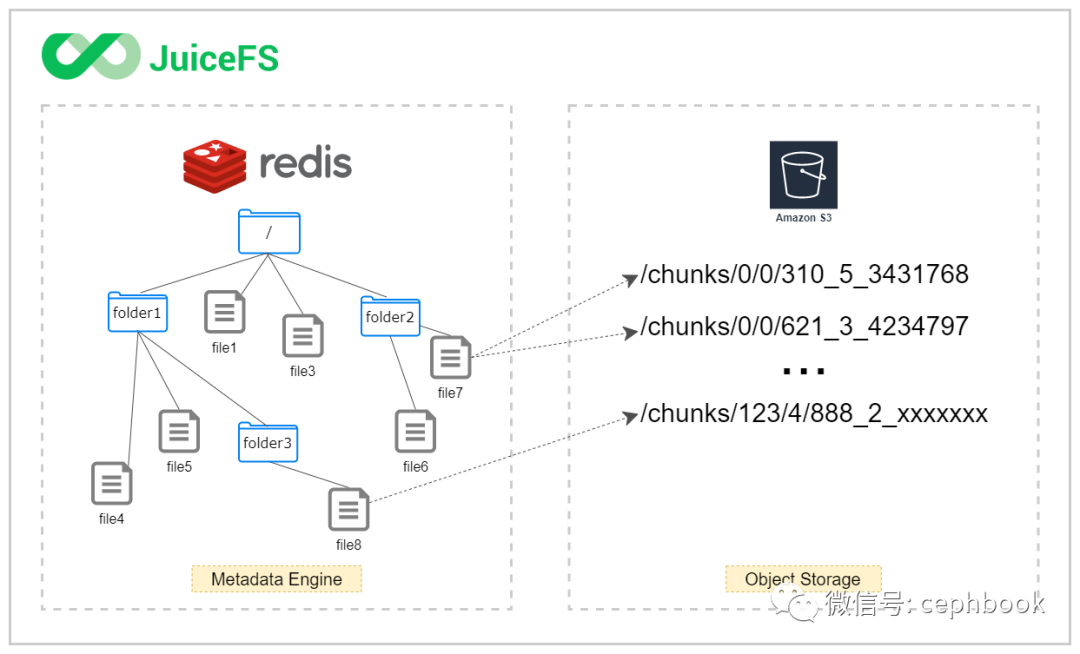
使用 JuiceFS,文件最终会被拆分成 Chunks、Slices 和 Blocks 存储在对象存储。因此,你会发现在对象存储平台的文件浏览器中找不到存入 JuiceFS 的源文件,存储桶中只有一个 chunks 目录和一堆数字编号的目录和文件。不要惊慌,这正是 JuiceFS 高性能运作的秘诀!
补充一下源码中,每个blocks的命名规则定义,也就是最终存储在对象存储系统中的对象key名称。
func (c *rChunk) key(indx int) string {
if c.store.conf.Partitions > 1 {
return fmt.Sprintf("chunks/%02X/%v/%v_%v_%v", c.id%256, c.id/1000/1000, c.id, indx, c.blockSize(indx))
}
return fmt.Sprintf("chunks/%v/%v/%v_%v_%v", c.id/1000/1000, c.id/1000, c.id, indx, c.blockSize(indx))
}
JuiceFS文件系统golang抽象接口组成
文件系统定义核心数据结构
type FileSystem struct {
conf *vfs.Config
reader vfs.DataReader
writer vfs.DataWriter
m meta.Meta
logBuffer chan string
}
下图为个人理解所画的抽象接口结构图
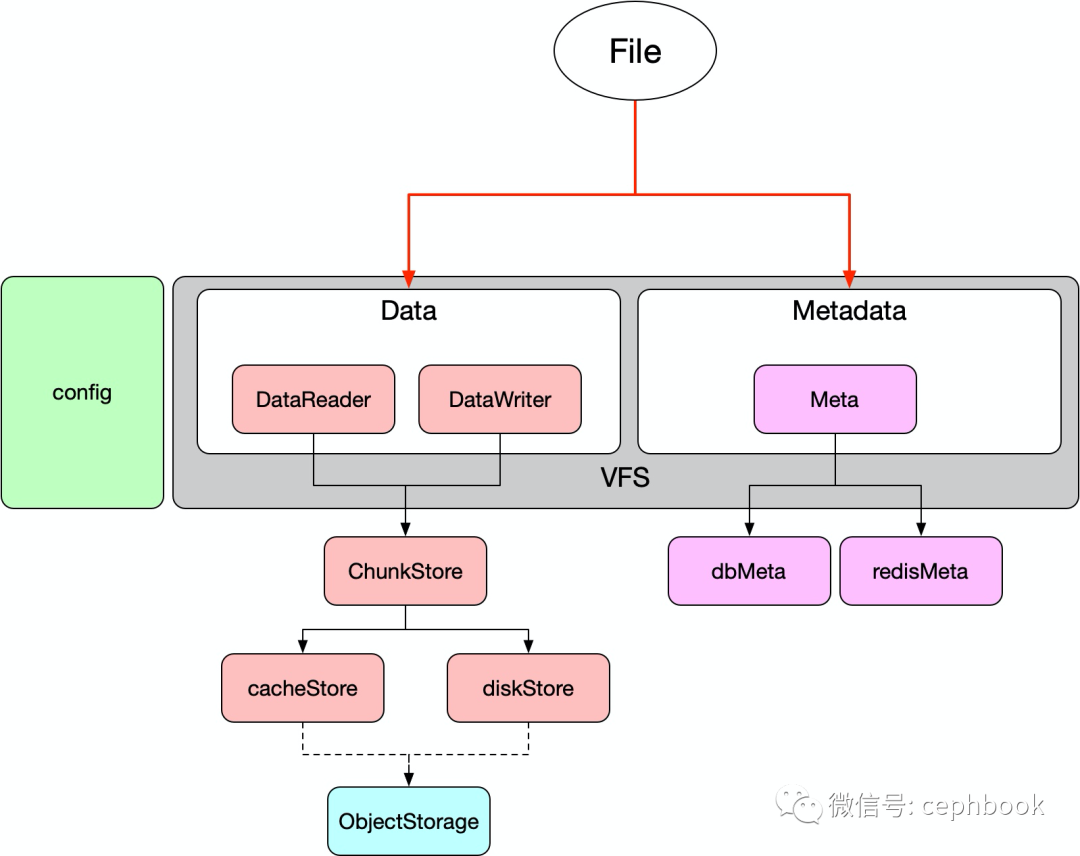
整个JuiceFS文件系统实现主要拆分为VFS抽象实现和相关的config配置管理两大部分。
任意文件File操作都涉及到数据和元数据两部分内容,因此代码中包含数据处理相关的DataReader和DataWriter两个抽象接口,用来处理数据的读取和写入两类请求。而元数据抽象出Meta一个数据库相关的接口,基于这个接口目前官方实现了dbMeta也就是兼容SQL相关的元数据实现,以及redisMeta实现(基于redis)。从性能表现来看,redis比MySQL性能要好3~5倍左右。具体可以参考这个
所有的数据读写操作都要和本地缓存进行交互(Chunk->Slice->block(page)三个层级进行管理),缓存目前主要实现了基于本地文件系统diskStore和基于内存缓存cacheStore(堆空间)两种类型。数据写入和读取最终都是由对应的缓存模块同步到远程的ObjectSotrage。
config主要负责对本地缓存、元数据引擎连接信息等相关的配置。
JuiceFS支持的数据列表:
https://github.com/juicedata/juicefs/blob/main/docs/zh_cn/databases_for_metadata.md
JuiceFS元数据redis与MySQL性能对比测试:
https://github.com/juicedata/juicefs/blob/main/docs/en/metadata_engines_benchmark.md
下图是源码中对ChunkStore的抽象接口定义,通过NewReader和NewWriter生成对应的Reader读取抽象和Writer抽象,实现数据的读写相关原子接口。
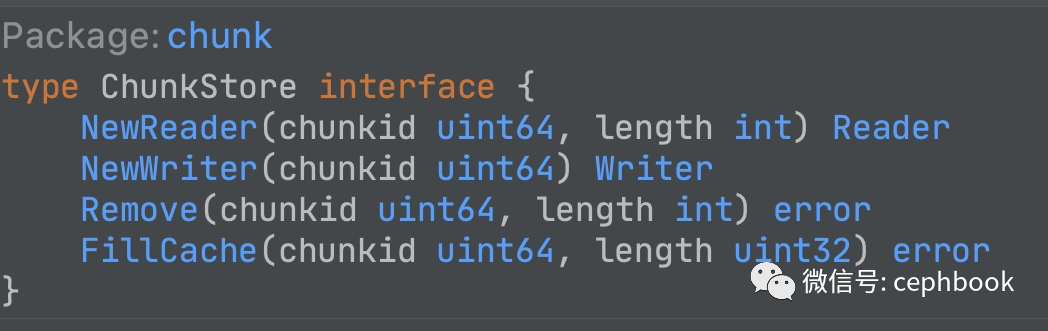
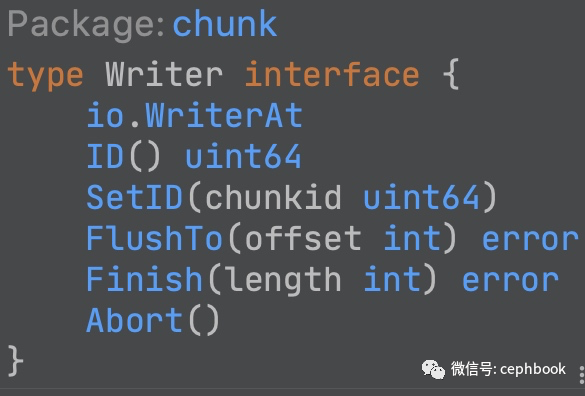

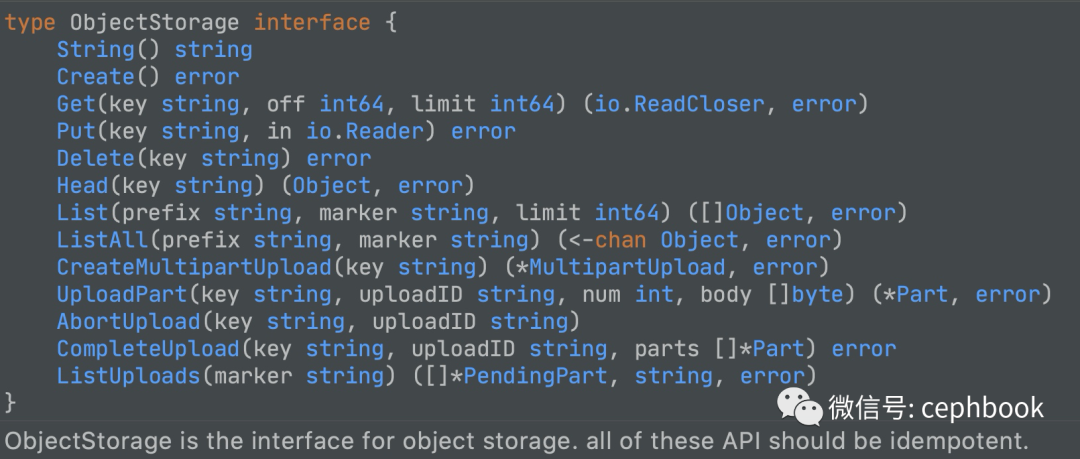
任何厂家的对象存储产品,只要实现下面的接口抽象,即可实现与JuiceFS的对接。
数据读取抽象接口
下图是数据读取抽象接口的继承组合关系
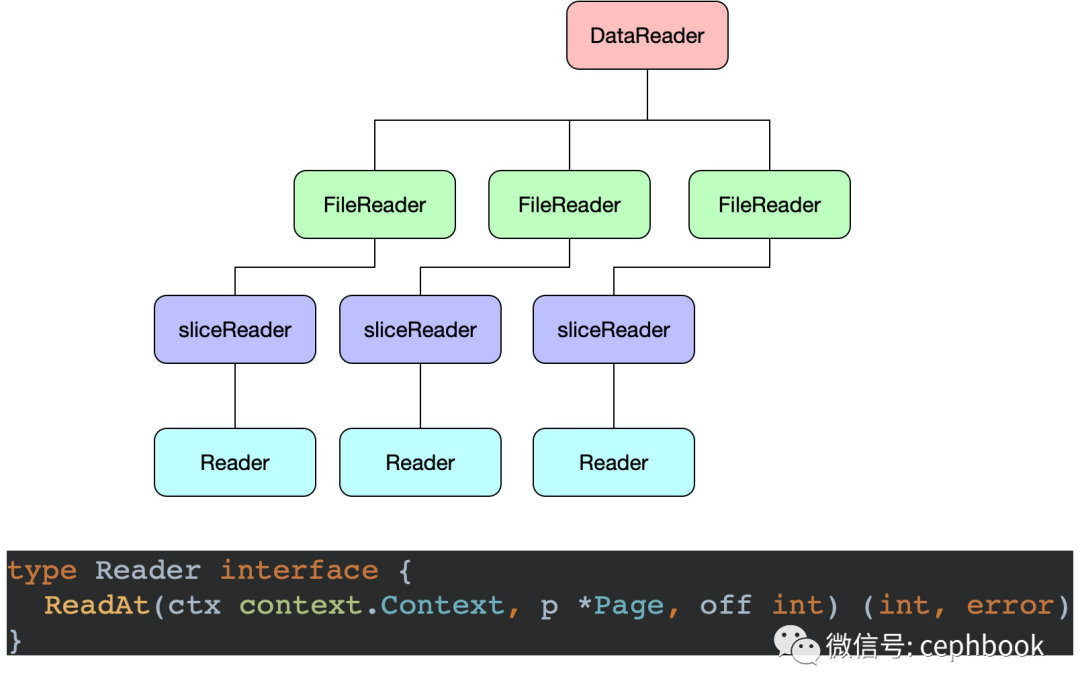
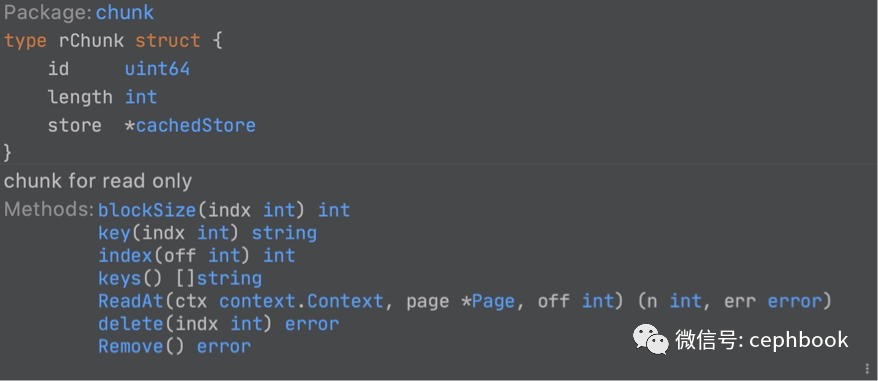
最终的数据读取关联到rChunk这个struct的相关method方法。
数据写入抽象接口
下图是数据写入抽象接口的继承组合关系
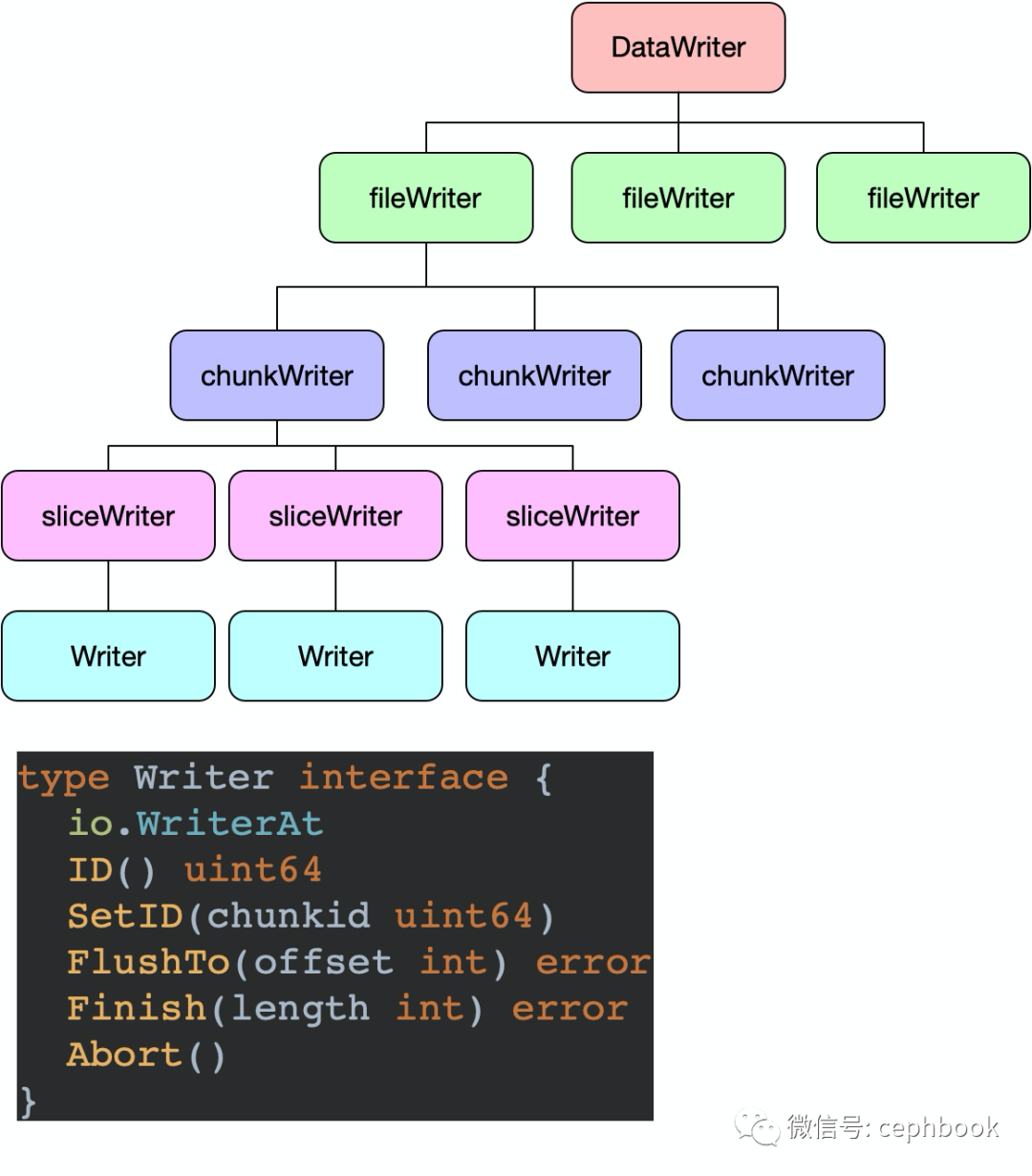
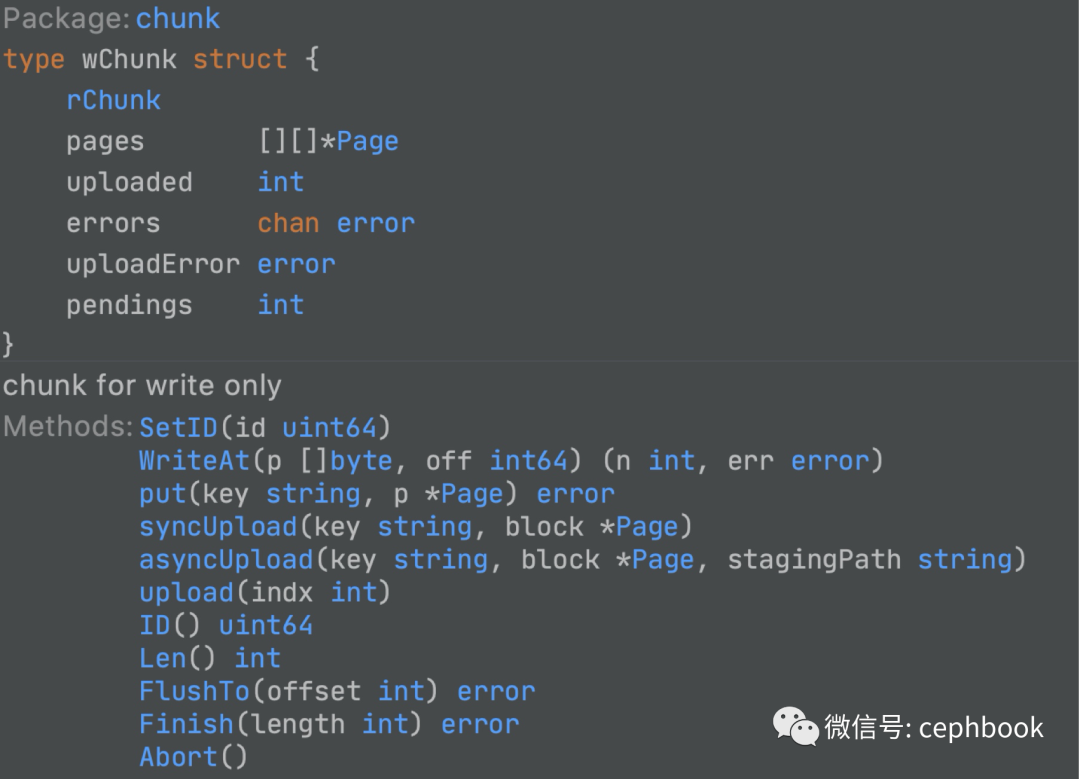
最终的数据读取关联到wChunk这个struct的相关method方法。
小节
至此,基本理清了JuiceFS的基本构架和核心数据结构,下节开始对其读写具体接口流程进行剖析。
打个小广告,团队持续招聘存储开发和运维同学,感兴趣的可以看看之前公众号网易游戏招聘相关内容。