
如何评价说 Python 是最快的语言?
作者:沈崴
我是视频的作者,首先感谢朋友们的关注,并且诞生了这个论题,让我可以看到大家对我视频中的观点的反馈。对于大家的讨论,在日常时间允许的条件下,我会尽量参与。下面就我目前已经看到的朋友们的评论,做一下展开。

一、如果说 Python 协程是个优势,那其他语言难道就没有协程吗?【1】
对其他语言来说“协程”或许是近年来才流行起来的一种“新技术”,但是对 Python 来说,协程早在 1998 年就已经出现并且大规模使用至今 —— 虽然从表面上看,各种语言的协程实现都大同小异,比如 Goroutine 和 gevent.patch_all() 都可以直接把整个语言协程化,使用起来非常方便 —— 似乎“只要增加了协程这个新特性就可以在任意语言中直接使用了”,但实际上协程具有极深的技术栈。
Python 在之前的 20 多年里,在积累上的领先,让 Python 和其他语言有了本质上的区别 —— “可以大规模商用”和“玩具”的区别。
下面我来简单摘取几个方面,来说明在这之前的 20 多年里面,Python 可以在协程技术上比“后起之秀们”多做多少事情。
1、调度器

和其他语言不同,Python 在长时间的积累中形成了大量可用的协程调度器,包括“抢占式”、“非抢占式”、“全功能”、“高性能”等各种实现,以适用于各种应用场景的需求。
我使用过的调度器就有 Stackless Python、Gevent、Curio 以及 Eurasia【2】等 —— 在这里,Eurasia 是我于 2007 年开源的协程服务器框架,使用了我自己开发的轻量级协程调度器,在性能上具有相当大的优势。
而在我开源的另一种协程服务器框架 Slowdown【3】中,我则是使用了在功能特性上更为全面的 Gevent 作为调度器,更加适合用于搭建复杂应用。
在不同的应用场景下能够拥有如此之多的选择,是 Python 在协程技术上,成熟性的体现。我开发的 Eurasia 发布于 2007 年,并在接下来的时间里一直在投入使用 —— 直到 6 年以后 Goroutine 才开始出现 —— 而此时,距离 Python 著名的大规模协程应用 EVE online 的推出,更已经经过 10 年。
2、专业性
协程在“栈切换”“调用上下文”上,和一般程序具有很大的差别,特别是和线程池、多进程配合使用时,情况会更加复杂。
如果没有技术积累,开发者往往不知道“代码在何种情况下会出现意外情况”,在出现错误时也不知道该如何正确地去调试 —— 这让协程技术虽然门槛很低,入门容易,但是在实际使用中,它会变成一个巨型的“天坑”—— 而 Python 长期在协程上的实践,形成了大量的技术积累,和无数的专家用户。这让你在遇到困难时,更容易查阅到解决方案,并获得更多的帮助 —— 而不是让你在协程技术领域中拓荒、踩坑。
3、文件/数据库
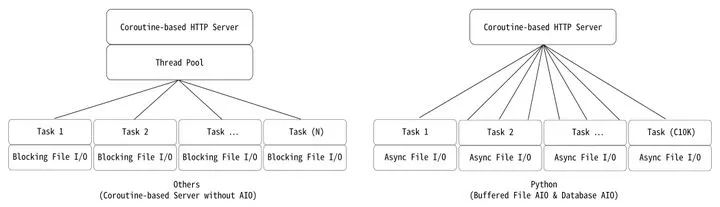
要在协程架构中真正实现高并发,就必须要把系统中的所有操作全部进行异步化 —— 任何没有异步化的节点全部都会变成性能瓶颈 —— 这相当于是要把整个操作系统都进行异步化改造,如果没有像 Python 这样,经过了漫长的积累,是无法做到的。
其中“文件”和“数据库”就是很难异步化的一个例子 —— 像 Python 中著名的 Tornado 就是只实现了网络部分的“协程异步化”,却对文件 IO 无能为力的一个典型案例。这样就只能被迫使用“基于多线程的应用层框架”,以“传统的多线程模式”来处理文件和数据库的请求。因此 Tornado 在事实上,仍然只是一个传统的,受限于“文件 IO 瓶颈”以及“线程数量”的服务器框架,同时数据库服务器也会变成整个系统的瓶颈。
其他像 Goroutine 协程,在遇到文件及数据库时,也同样会退化为线程池,这也是其他各种语言的常态 —— 其实在 Python 世界中,以我自己为例,在使用协程的十几二十年的时间里,早已完成“缓存式文件 IO”及“数据库底层磁盘 IO”的“协程异步化”改造。
这意味着高级的 Python 协程系统,不仅可以同时响应“百万级的网络 IO”,也能处理同等并发规模的“文件读写”和“SQL 请求”。这使得 Python 的协程可以贯穿整个系统,没有任何一个节点成为瓶颈。
二、说 Python 的运行速度快是不是太扯了?
视频中的观点是“程序性能只和瓶颈有关”,“语言快不快只和它拥有多少绕过瓶颈的手段有关”。
开发效率越高,语言可以实现的性能优化就会越多,程序也就越快 —— 表面上可以用其他语言来改写 Python 程序来获得更高的执行效率,但是可能会花上好几倍的时间 —— 而在同样这段时间里 Python 已经可以写出更快的实现了。
在 PyPy 出现以前,Python 主要的 JIT 还是 Psyco 的时候,开发者就已经需要在 Unix/Win32 等不同平台下来维护 Psyco 的 32 位版本了,但随着 64 位 CPU 的逐渐普及,要想同时维护多个 OS,以及 MIPS/ARM/x86 等 CPU 架构,并同时维护 32 位和 64 位 CPU 下的版本,这让维护 Psyco 本身就变得非常吃力,在 JIT 算法上进行突破就变得更加不可能了。
于是 64 位 CPU 的推出,成了压跨项目的最后一根稻草,Psyco 的开发者在一篇文章中最后提到【4】,他发现只有依赖 Python 的开发效率才能让 JIT 更进一步,尤其是在开发阶段 Python 可以直接解释执行的特点让 JIT 的调试工作变得非常容易。所以 Pysco 的开发者停止了 Psyco 项目,并转而开创了 PyPy 项目。
这说明当一个项目的“复杂性”和“工作量”到达一定级别时,Python 已经不是仅仅能够“快过”C 语言这么简单了,事情会变成“如果不使用 Python,问题可能根本就没有办法解决”的程度。故而在视频里“JIT 开发”被当作典型案例来使用 —— 当然这肯定不是孤例。
在许多时候,我们可能只是把 Python 当作“能跑起来的伪代码”用来进行“快速原型开发”,一旦原型验证完成,程序员会有一个本能的冲动,就是把它修改成“正式”的 C 语言版本来“一劳永逸”、“以利千秋”。
IBus 输入法便是从一个 Python 项目逐渐 C++ 化,并让性能得到提升的一个很好的例子,但是更多的 Python 项目却并没有像意料中那样,最终走上 C 语言化的这条道路,而是依旧坚持使用 Python 语言来进行开发。
所以在“从‘Python 快速原型开发’到‘C 语言最终正式版’”的这个演进剧本里一定是出现了某种变数 —— 当开发者准备替换 Python 时,他们发现:
如果使用其他语言来强行改写 Python 程序,由于瓶颈可能并不在语言这个层面,可能根本就无法在性能上得到可观的提升。 如果不使用 Python,开发和维护的成本可能会大幅升高到无法承受的程度,强行替换 Python 只会让程序在“功能”和“性能”上全面落后于 Python 版本的升级速度。
这指向一点:只要存在大量的 Python 项目,在经过无数次升级后,仍然没有被 C 语言化,那么在这些项目中,Python 的执行性能肯定不会输于其他语言。“这些项目其实‘都’是 Python 程序运行速度快的例子”。
在后面我即将发布的该系列视频的第二集「PYTHON 为什么是最快的语言(时空篇)」中,我会提到,由于 Python 语言简洁的特性,会让程序看上去都非常简单,这掩盖了每个 Python 程序事实上的复杂度,并给人以一个错觉,以为用其他语言“也”可以轻松地写出具有同等复杂度的程序。
而等到真正用其他语言来着手实施的时候,才发现要实现同等复杂度的程序,语言性能下降的幅度,最终会出乎所有人的意料。
三、Python 在执行效率上会不会被编译型语言吊打?
一个例子是 Java 的 WEB 服务常常会给人以性能不行的印象,然而事实却是,Java 是一种逐行执行性能很高的语言,Java 的 socket 服务器其实也拥有相当不错的性能。
但是当把应用逻辑加进来以后,为了漂亮地解决各种业务逻辑,服务架构变得异常复杂和庞大,以至于曾经出现过著名的“厚胶合层怪物”:“J2EE”,并最终把 Java 服务的性能从高空拽下地板。
这说明在应用领域,“逐行执行性能”并不是“最终真实性能”的决定性因素。只有抑制住让架构无限膨胀的冲动,才能在性能上最终胜出。
PHP 这种“最好的编程语言”就曾长期被人批评为“不够面向对象”、“缺少企业级开发能力”—— 但无论如何,在客观上,这使得 PHP 很难写出痴肿的应用架构,这导致 PHP 编写的 WEB 服务,最终无论是在“性能”上还是在“功能”上都相当出色。
感谢 Python 出色的开发效率,重新制造一个轮子变成了一件似乎没有什么成本的事情,所以在 Python 中诞生了无数的 WEB 框架,这是一个只有在 Python 世界才会出现的独特现象 —— 其中就包括我开源的“Slowdown”(及前面提到的“Eurasia” 等)项目。
这是一个从 socket 底层到应用层,都完全使用 Python 开发的服务器框架。那么问题来了,这里使用 Python 来进行应用层开发是可以理解的,但是为什么连 socket 底层都要使用 Python 来开发,这不会有性能问题吗?
虽然有点违反直觉,但我的答案是:“使用 Python 进行底层开发只会让服务器性能变得更好”。
首先,使用 C 语言来处理 socket 通信和 IO 调度,的确会让服务器的底层性能有所提升。
但是我们无可避免地要将底层接口“封装”给 Python 等其他语言的“应用层框架”使用,这就涉及到了“底层”到“应用层”的接口转换,在转换过程中,相当一部分“底层接口”的“灵活性”将无可避免地牺牲掉了。
为了弥补这部分灵活性的损失,“底层”和“应用层”需要被迫调整出更加复杂庞大的封装架构,增加更多的接口,来应付一些涉及到“底层”的需求。 如果底层和应用层实现了彻底的封装隔离,许多通过操作底层可以直接轻松处理掉的需求将无法实现,或者只能通过其他相对复杂的方法来“近似”实现。
如果你是某个应用框架的用户,看到这里或许会有一种似曾相识的感觉。因为曾经有个功能你发现框架并没有提供,而要把这个功能加上,则需要操作框架底层的权利,但是由于底层已经被“封装”得“很好”是无法接触的 —— 这最终让你动弹不得 —— 而当问题被提交给框架的维护者时,解决方法往往是“为每个新增的问题设计出更多的接口”、“重构出更好的架构”。
这样,框架的复杂度就会逐渐滑入失控,变得臃肿,最终让性能大幅下降。
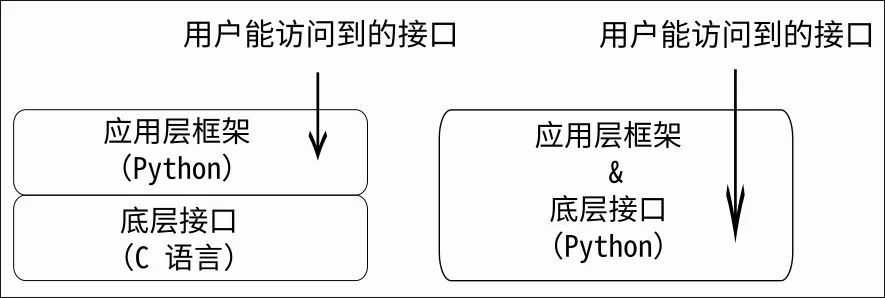
而使用 Python 来统一开发“应用层框架”和“服务器底层”,则可以避免让“底层”和“应用层”进行跨语言接口转换与封装 —— 进一步,可以让“底层直接穿透到顶层”,并最终让“底层和应用层完全合并”,胶合层消失,框架(framework)程序库(library)化。最终实现架构简化,和性能反超。
而这,对 Slowdown 之类的协程服务器具有着更加非凡的意义。由于协程是用之不竭的,所以可以“利用协程来维护‘无数’长连接的上下文”来“等待长时间执行结果”而无需受到“传统架构下线程数量的限制”,不需要通过“中断连接上下文”来“释放有限的线程”用额外的缓存架构和消息队列来传递“长时间的执行结果”。
这样就可以把大量的因“受限于传统线程架构”而增加的中间架构(中间服务器、IPC)给精简掉了。而此时,由于应用层中“长时间任务的上下文”和底层的“长连接上下文”是紧密耦合的,所以在这里“底层穿透性”就尤为重要了。
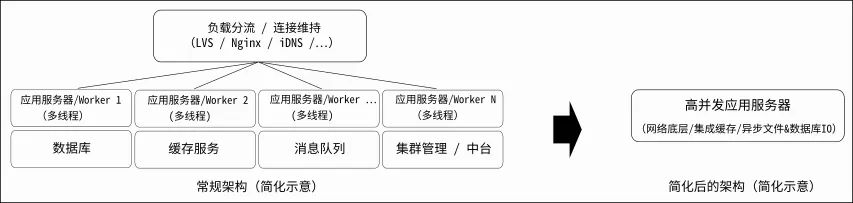
结合上述内容,我们不难发现使用 Python 将底层与应用层进行融合,最终可以起到将整个系统的架构大幅简化的惊人效果。
这样匪夷所思的结果出现了:使用 Python 进行服务器底层开发,在整个系统层面反而取得了更好的性能。
目前有大量的基于 Gevent 或者 asyncio 等框架的 Python 项目,仗着自己是协程架构,性能起点高,不管有意无意,通常会采用从网络底层到应用层的全栈式设计,虽然没有用到编译型语言来“优化”底层,却在 benchmark 中都具有不错的成绩,这又成为 Python “直接用于性能敏感的底层开发”,并“在性能上超过包括编译型语言在内的其他语言”的典型案例。
四、和其他解释性语言的性能比较
下面我们来谈一下视频中提到的“开发效率 == 运行效率”这一条,是否同样可以套用在其他语言上的这个问题。
简单来说,答案是肯定的 —— 由于在“公平”“同等”的时间里,开发效率高的编程语言一定可以实现更多的“优化”绕过更多的“瓶颈”,任何语言只要能够拥有极致的开发效率,那么(在不是强烈依赖于逐行性能的多数场景下)一定会拥有不错的运行效率。
这样在许多时候,程序“运行效率”的比拼,其实就是“开发效率”的比拼。
那么其他语言是否拥有和 Python 一样的开发效率呢?
这就是一个非常依赖于主观判断的问题了。所以我试图采用一个“更为客观”的标准来对编程语言的开发效率进行评价:“有效项目数”—— 如果一种语言的开发效率很高,那么在“足够长的时间段”和“相同的时间”里,它一定会开发出比别人更多的项目,“产量更高”。
在翻阅了 Github 的“Ranking”、“Trending”、“Stars”中的项目之后,我发现这些指标几乎都被两大语言所“霸榜”:“Javascript”和“Python”。这意味着“单从客观指标上来讲”,大部分语言的开发效率尚不能达到 Python 的级别。
依赖于开发效率,Python 在单位时间里就可以生产出更多的优化算法,绕过更多瓶颈,从而实现更高的执行效率。这样 PYTHON 作为最快的编程语言,可以说实至名归。
五、“靠开发效率省下时间优化算法”是否足以让 Python 获得比 C 更好的性能(况且很多业务代码根本不存在多大优化空间),这点需要有说服力的实践来举例论证。
首先我们来思考一个业务问题,在登录、验证的场景中 Python 每秒能够生成多少个图形验证码?当验证码的并发请求数太多,超出程序处理能力的时候,我们应该如何去优化?
最简单的想法,自然是使用 C 语言来优化出更快的 captcha 生成方法,如果性能还是不够用,我们就增加服务器,用来生成验证码 —— 不过在实际开发中,我们并不会真的这么做 —— 今天我主要会用我“正在使用的”,并且开源的 Slowdown 服务器作为说明案例。这个服务器实现简单、代码不多,作为作者我又比较熟悉,拿来当例子会比较方便。
1、Captcha
Slowdown 的 captcha.py 模块,会预生成一批随时间轮替的验证码图片,当请求验证码图片时,它不会通过“即时演算”真的去生成一张图片,而是会从“已有的图片池”中,随机抽取出一张图片来返回给用户。这样每个用户就可以拿到不同的图片,而不同的用户则可以对图片进行复用。在这种情况下,图片验证码的生成速度会快到令人窒息,从而让性能测试变得毫无意义。
尽管如此,我还是顺手测了一下,生成 1000000(一百万)个图形验证码的时间大约是 1.9 秒 —— 这就回答了前面的第一个问题“Python 每秒能够生成多少图形验证码”(50万+)。 那么这个“图形验证码的优化实现”需要多少 Python 代码?—— 76 行(含注释)。
2、接下来是一个更大的案例
尽管性能并不是 Slowdown 最主要的设计目标(所以是我设计的服务器里性能最弱的一款,轻业务下,性能只有我其他 Python 服务器作品的 1/2~1/3 ),但是这种完全使用 Python 开发的服务器,在性能上与纯 C 实现的服务器并没有特别严重的差距 —— 这里我选择的比较对象是 μwsgi,这是一款非常著名的,使用纯 C 开发的异步服务器。具有和 nginx 相当的性能。
下面我们来做一下测试。因为都是已经公开发布的开源软件,下面这些测试方案也比较简单,有兴趣的朋友可以自行搭建、测试。
# 用例: μwsgi
def application(env, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
# connection.execute(SQL)
return [CONTENT]
# 用例: slowdown
def handler(rw):
rw.start_response('200 OK', [('Content-Type', 'text/html')])
# connection.execute(SQL)
rw.write(CONTENT)
rw.close()
首先是空载测试,仅输出“It works”页面。
Server Software : uwsgi --http-socket :8080 --wsgi-file test.py > /dev/null 2>&1
Document Length : 117 bytes
Concurrency Level : 1000
Requests per second: 22374.22 [#/sec] (mean)
Transfer rate : 3519.30 [Kbytes/sec] received
Server Software : slowdown {'handler': 'mytest'}
Document Length : 117 bytes
Concurrency Level : 1000
Requests per second: 7238.88 [#/sec] (mean)
Transfer rate : 1392.64 [Kbytes/sec] received
为了尽量贴近真实,我进一步设计了一个简单的应用场景,完整的服务器日志输出,并模拟一次耗时约 0.002 秒的数据库操作(独立数据库服务器)和 20KB 页面。
Server Software : uwsgi --http-socket :8080 --wsgi-file test.py --logto access.log
Document Length : 20493 bytes
Concurrency Level : 1000
Requests per second: 418.94 [#/sec] (mean)
Transfer rate : 8406.01 [Kbytes/sec] received
Server Software : slowdown {'handler': 'mytest', 'accesslog': 'access-%Y%m.log'}
Document Length : 20493 bytes
Concurrency Level : 1000
Requests per second: 4546.93 [#/sec] (mean)
Transfer rate : 91302.86 [Kbytes/sec] received
可以发现,当没有业务负载时,纯 Python 开发的 Slowdown 服务器,在性能上大约是纯 C 服务器的 1/3 。
但是当少量业务被部署上去以后,C 服务器的性能突然出现了大幅下降。最终 Python 服务器的性能惊人地达到了 C 服务器的 10 倍之多(高一个数量级)。
这正是 Slowdown 的设计目标之一,放弃空载性能的争夺,着重让服务器在具有实际业务负载的情况下,使性能缓慢下降,并在“满业务负载”的情况下,最终稳定在一个很高的数值上。
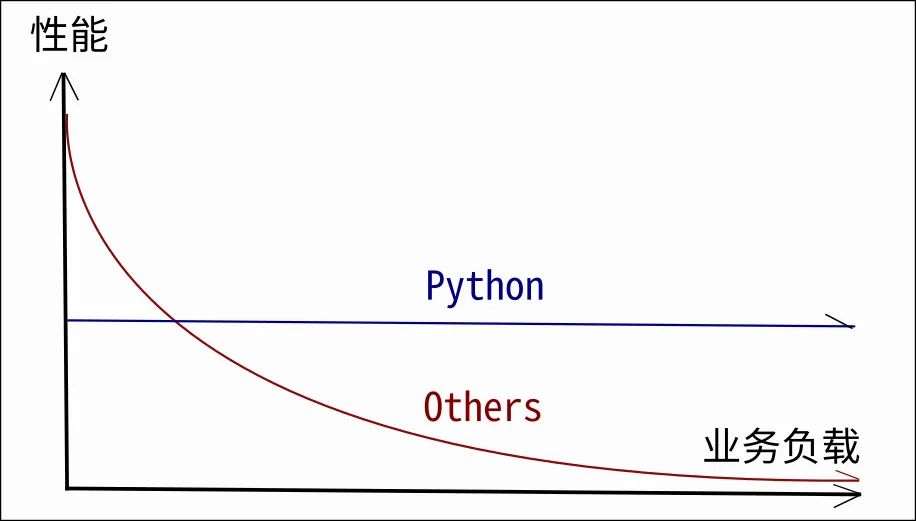
3、开发效率和性能的关系
在上面这个例子中,类似 Captcha Token 这样的联合缓存、磁盘路径及静态文件缓存,这些几十行代码就能带来极大性能提升的优化随处可见。使用 Python 来开发服务器还能够省下大量的时间,用于全架构的体系性优化。还可以把瓶颈点用 C 语言进行逐点优化(正如视频中所说,Python 和 C 并不是竞争关系,Python 就是 C)—— 这都是高开发效率下,拥有足够的时间才能做到的结果。
Slowdown 仅仅是一个底层服务器框架,用到的优化就已经如此之多了。那么在更加复杂庞大的业务层,将会拥有多少的优化空间?—— “理论上”C 语言也不是不能“从头就开发出一样的程序”,但是像 Python 这样每隔几十行就会有一个高效算法,做到如此密集的优化,实际上是很难达到的。因为受制于开发效率,其他看似“逐行执行性能很高”的语言,最终也只能与 Python 争一域之得失。
业务越复杂,工作量越大,Python 在性能上的优势就会越明显。
六、GIL 会影响 Python 使用多核吗?GIL 会影响 Python 的性能吗?【5】
有句话叫做 Unix 程序员永远可以把多核用完,Python 也不例外。操作系统本身,各式各样的服务,被管道串起来的进程们,Apache、Nginx、MySQL、PostgreSQL、Redis、memcached、MQ …… 都可以把多核用完。
不过,我们今天来谈另外一个问题,为什么 GIL 会影响到 Python 使用多核 —— 一般的看法是 GIL 的存在,让 Python 同时只能允许一个线程执行,这样 Python 就不能真正的使用多线程,自然也就不能透过多线程来用到多核了。
但是,为什么要使用多线程?

参考
本文分别就以下知乎网友提供的答案进行了进一步的展开:(一)潘俊勇(二)季晨曦、游汉(三)山海师(四)季晨曦(五)SherlockGy(六)陆海绵 Eurasia 基于协程异步的服务器及开发框架 https://code.google.com/archive/p/eurasia Slowdown 基于协程异步的服务器及开发框架 https://github.com/wilhelmshen/slowdown 由于时代过于久远,该文章的归档暂时没有找到。可以参阅 Psyco 项目主页上“Related project”一节 http://psyco.sourceforge.net/links.html 进一步内容可参考知乎「CPython有GIL是因为当年设计CPython的人偷懒吗?https://www.zhihu.com/question/439920631/answer/1685766305

还不过瘾?试试它们