
5000字阐述云原生消息中间件Apache Pulsar的核心特性和设计概览
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜

Pulsar中的核心概念
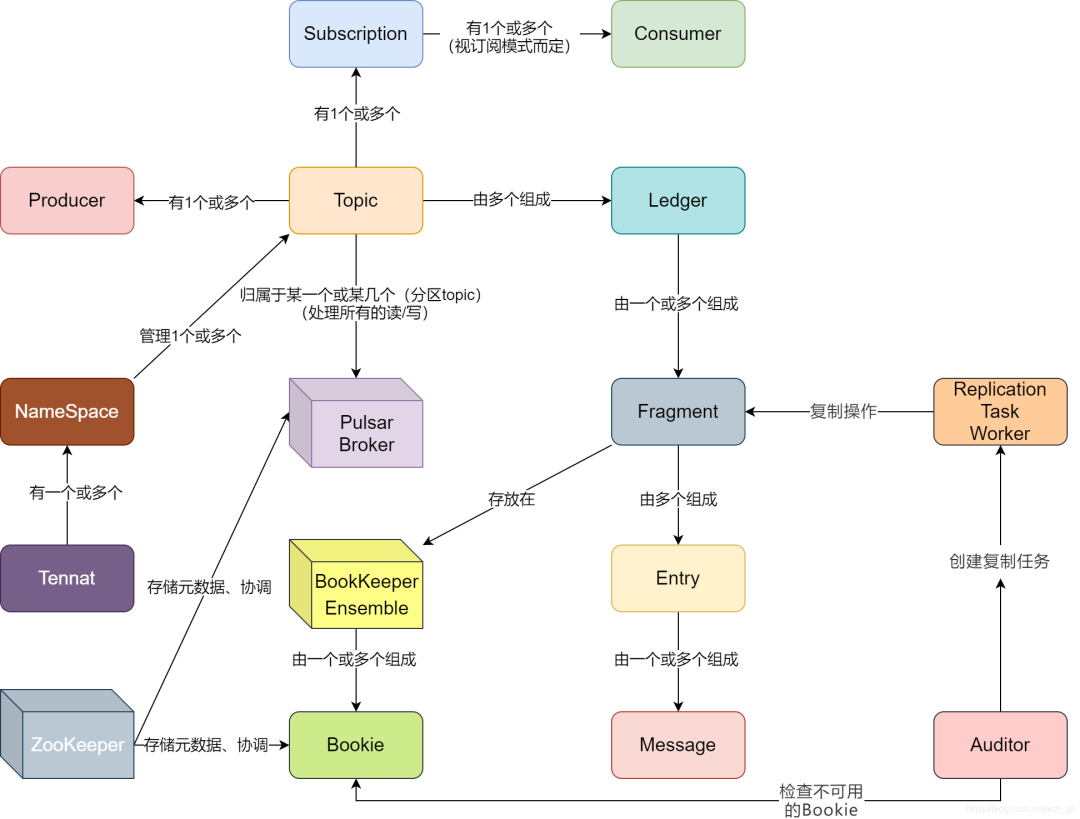
Topic

Bookie
Broker
Entry
Ledger
MetaData Storage
Journal
Entry log
Index file
Ledger cache
数据落盘
Data Compaction
Minor compaction
Major compaction
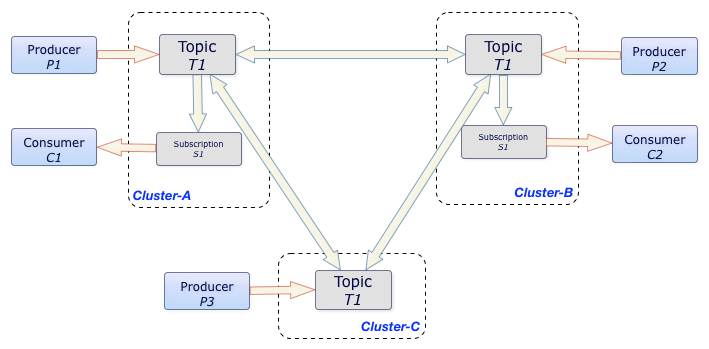
跨地域复制( geo-replication),单个实例原生支持多个集群(跨集群复制)
极低的发布延迟和端到端延迟
可无缝扩展到超过一百万个 topic
简单的客户端API,支持Java、Go、Python和C++
支持多种topic订阅模式:独占订阅、共享订阅、故障转移订阅、键共享(exclusive, shared, failover, key_shared)
通过 Apache BookKeeper 提供的持久化消息存储机制保证消息传递
由轻量级的无服务器(serverless )计算框架 Pulsar Functions 实现流原生的数据处理
基于 Pulsar Functions 的无服务器连接器框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar
分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如S3、GCS)中
Pulsar的架构设计
一个或者多个 broker :负责处理和负载均衡 producer 发出的消息,并将这些消息分派给 consumer;Broker 与 Pulsar 配置存储交互来处理相应的任务,并将消息存储在 BookKeeper 实例中(又称 bookies);Broker 依赖 ZooKeeper 集群处理特定的任务;
一个BookKeeper:包含一个或多个 bookie 的 BookKeeper 集群负责消息的持久化存储;
一个ZooKeeper:特定于某个Pulsar集群的ZooKeeper集群处理Pulsar集群之间的协调任务。
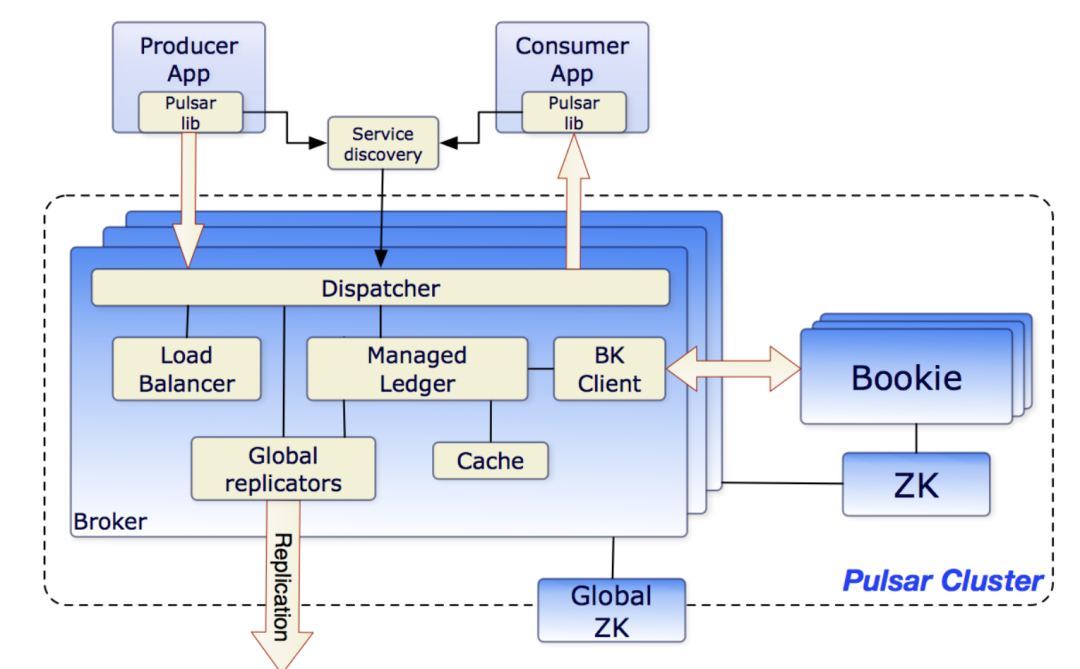
利用多个ledger保存独立的日志
为按条目复制的顺序数据提供了非常高效的存储
保证了多系统挂掉时ledgers的读取一致性
提供不同的Bookies之间均匀的IO分布的特性
在容量和吞吐量上都可以水平扩展。通过向集群添加更多bookie,可以立即增加容量
Bookies可以包含数千个具备同时读写功能的ledger。使用多个磁盘设备,一个用于日志,另一个用于一般存储,这样Bookies可以将读操作的影响和对于写操作的延迟分隔开
除消息数据外,游标(cursors)还永久存储在BookKeeper中;Cursors是消费端订阅消费的位置;BookKeeper让Pulsar可以用一种可扩展的方式存储消费位置
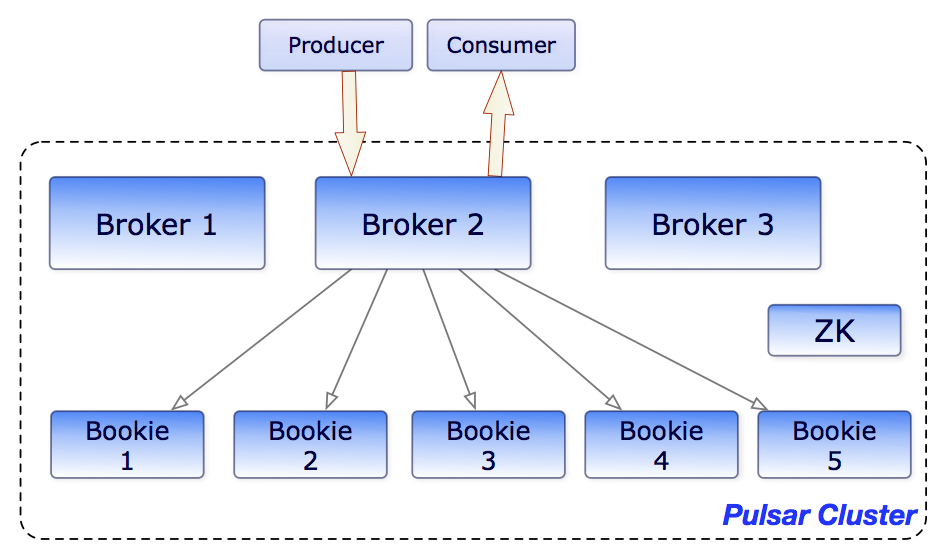
Pulsar Broker可以创建ledeger,添加内容到ledger和关闭ledger。
当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,这个ledger只会以只读模式打开。
最后,当ledger中的条目不再有用的时候,整个legder可以被删除(ledger分布是跨Bookies的)。
多个Broker节点组成一个Pulsar Cluster;多个Pulsar Cluster组成一个Pulsar Instance。
Pulsar通过geo-replication支持一个Instance内在不同的集群发送和消费消息。
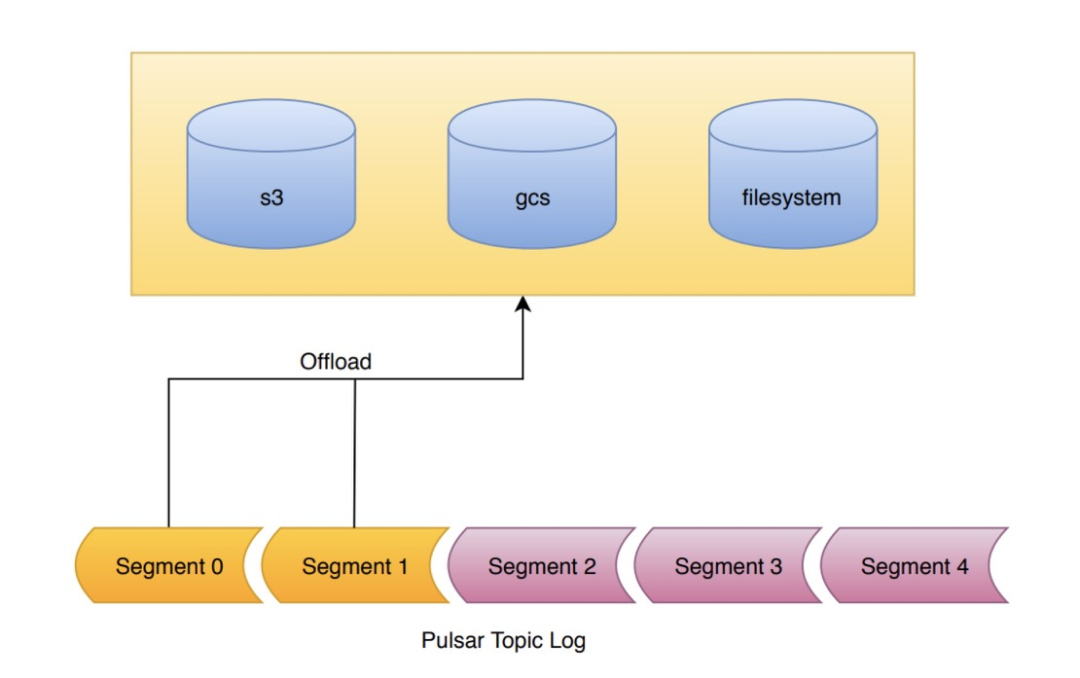
Pulsar的核心设计
保证不丢失消息
强顺序性保证
读写延迟

你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。