
系统如何设计才能更快地查询到数据?


“开通微信时,系统如何判断你输入的手机号没被注册?如何使用更少的存储空间、更快的速度解决这个问题?”
对于这个问题,最暴力的方法为:
通过遍历来判断是否被注册。那么时间复杂度为O(n),空间复杂度也是O(n)。
稍微学过算法的同学会说:
使用HashMap,时间复杂度瞬间降到O(1)。
精通算法的同学可能会说:
使用Bitmap,因为Bitmap只需要存储数据的状态信息(0和1),这样空间复杂度为O(max_value)。
下面问题又来了:
如果n=10亿,将会占据多少内存?
假设整数为64bit=8Byte,
Hashmap:10亿整数需要8G的内存
Bitmap:
虽然速度提上去了,内存占有量无法想象的…大!
那如何既保证查询效率,又保证低内存占用?
下面我们的主角闪亮登场——布隆过滤器。
一、Bloom过滤器的简介
Bloom过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。
它实际上是由一个很长的二进制向量和一系列随机映射函数组成。
它的目标是——占用更小的空间的前提下,检索一个元素是否在一个集合中。
二、原理介绍
下面我从三个方面来介绍布隆过滤器:构造、检索、效果。
1.构造
构造主要包括以下三个步骤:
选择k个哈希函数
将待检索字符串分别做Hash映射
每个映射的值对应的bit数组置为“1”
我举一个简单的例子:
假设我们有3个哈希函数,有两个待检索字符串"jimboooo"和"luckyyyyy"。
对于字符串"jimboooo",经过三个哈希函数映射后,将1,4,8的位置置为“1”。
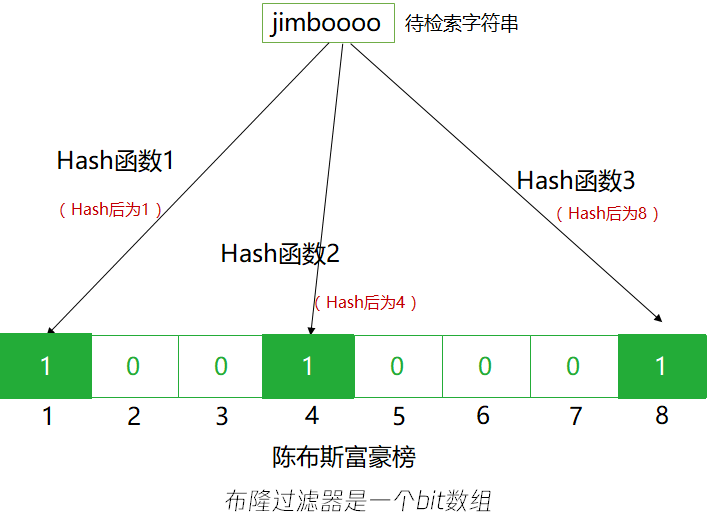
同理,对于字符串“luckyyyyy",我们经过哈希函数映射后,将位置2,4,7置为“1”。
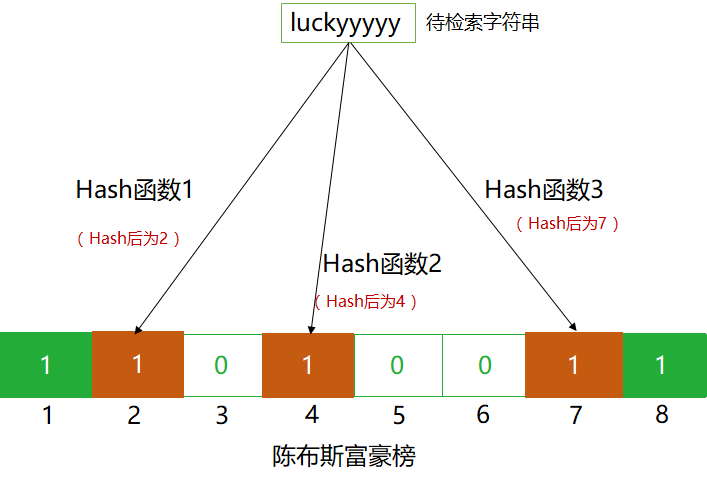
那么,我们的布隆过滤器已经构造完毕了。
2.检索
将待检索的字符串通过k个哈希函数映射;
查看映射的整数对应的位置是否1,如果都为1,说明待检索字符串是存在的。
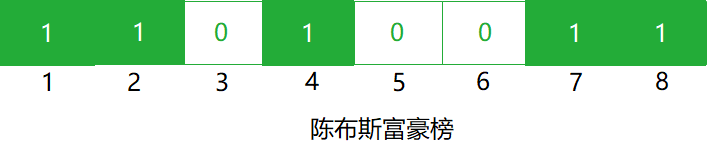
下图是我们构造过程得到的数组,如果要检索"jimbooo",哈希映射后是2,4,7,这三个位置都为1,说明此字符串是存在的。如果要检索"fukuoka",映射后是1,3,4,因为3的位置为0,很明显它是不存在的。
3.效果
布隆过滤器的原理已介绍完毕,看起来十分简单。那可能会出现什么问题呢?
如果要检索的字符串(原本不存在)映射后数组每个位置恰好都为1,那就出现了误判!

我们来通过公式了解下它的误判率、布隆过滤器长度以及哈希函数个数之间的关系吧。
先上公式(推理见附录):
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数(待检索元素总数),p 为误报率,
当且仅当:
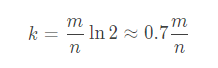
误报率p取得最优解:
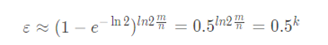
根据公式就可以得到布隆过滤器的长度、误识率、待插入元素个数(待检索元素总数)的关系了。
如下图所示,x轴为m/n,含义为每个元素占有的bit数,y轴为误识率。
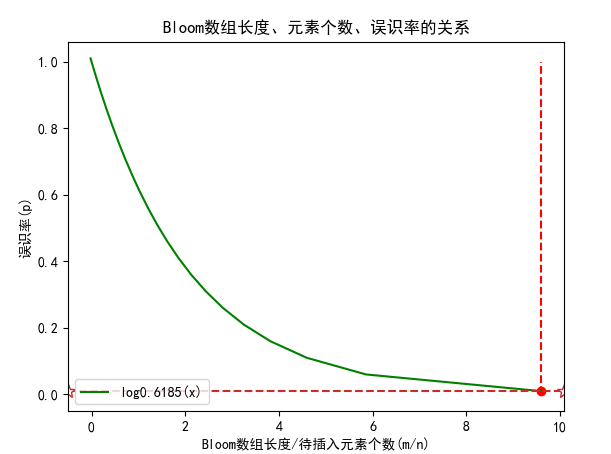
得出的结论是,对于一个拥有最优k值且误判率在1%的布隆过滤器,每个元素只需要9.6bits(与元素的大小无关)。若给每个元素增加4.8bits左右,误判率将会减少十倍。
三、应用
可应用于很多方面:
1.网页爬虫对URL的去重
避免爬取相同的URL地址。
2.缓存击穿
将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
3.HTTP缓存服务器
当本地局域网中的PC发起一条HTTP请求时,缓存服务器会先查看一下这个URL是否已经存在于缓存之中,如果存在的话就没有必要去原始的服务器拉取数据了(为了简单起见,我们假设数据没有发生变化),这样既能节省流量,还能加快访问速度,以提高用户体验。
4.黑/白名单
类似反垃圾邮件。
四、结论
布隆过滤器用于判断一个元素是否在一个集合中,不会有假负例(将在集合中的元素误判不在集合中),但会有一定的误识率(将不在集合中的元素误判为在集合中)。
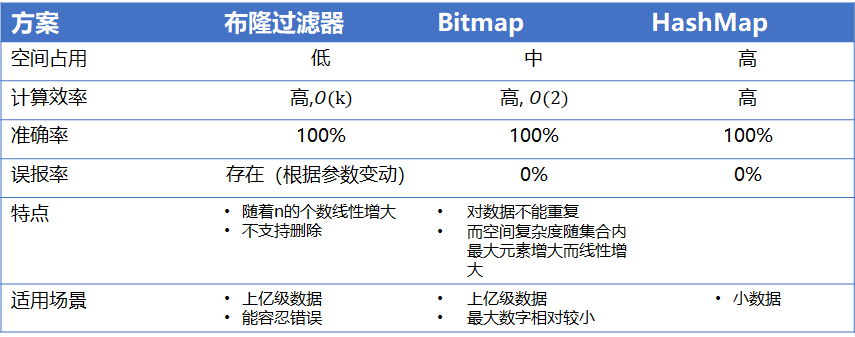
方案对比结论:
五、附录
1.公式推导
(1)k次哈希函数某一bit(长度为m)未被置为1的概率为:
(2)插入n个元素后依旧为 0 的概率和为 1 的概率分别是:
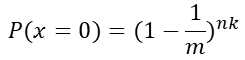
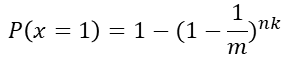
(3)k个位置均被设为1的概率:
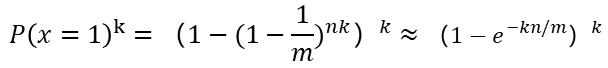
2.如何让误识率降到最低?

3.哈希函数怎么设计?
要点:
Independent 相互独立
Uniformly distributed.离散型均匀分布(概率相同)
They should also be as fast as possible. 要快
案例分享:
Chromium uses HashMix
python-bloomfilter uses cryptographic hashes(cryptographic hashes)
Plan9 uses a simple hash as proposed in Mitzenmacher 2005
Sdroege Bloom filter uses fnv1a (included just because I wanted to show one that uses fnv.)Squid uses MD5
4.参考文章
(1)布隆过滤器应用:
https://www.pdai.tech/md/algorithm/alg-domain-bigdata-bloom-filter.html
(2)Hash函数设计:
https://llimllib.github.io/bloomfilter-tutorial/
(3)函数推导参考:
https://blog.csdn.net/quiet_girl/article/details/88523974
作者简介

杭天梦
微信支付数据开发工程师
微信支付数据开发工程师。毕业于清华大学,硕士学位。2018年加入腾讯。现在从事大数据相关工作,现研究方向主要包括异动数据归因分析、多源数据策略选择、知识图谱实体对齐等。
推荐阅读
