
浅谈Prometheus的数据存储
目录
1、概述
2、时间序列
3、二维模型
4、存储策略的演进
4.1 1.x 版本
4.2 2.x 版本

本文是结合耗子叔的视频及 Prometheus 作者部分原文整理,加上部分个人理解而来,膜拜大神~
1、概述
Prometheus是一套开源的监控&报警&时间序列数据库的组合
Prometheus内部主要分为三大块,Retrieval是负责定时去暴露的目标页面上去抓取采样指标数据,Storage是负责将采样数据写磁盘,PromQL是Prometheus提供的查询语言模块
其有着非常高效的时间序列数据存储方法,每个采样数据仅仅占用3.5byte左右空间
在早期有一个单独的项目叫做 TSDB,但是,在2.1.x的某个版本,已经不单独维护这个项目了,直接将这个项目合并到了prometheus的主干上了
prometheus每次抓取的数据,对于操作者来说可见的格式(即在prometheus界面查询到的值)
requests_total{path="/status", method="GET", instance="10.0.0.1:80"} @1534317560938 94355
意思就是在1534317560938这个时间点,10.0.0.1:80这个实例上,GET /status 这个请求的次数累计是 94355次
最终存储在TSDB中的格式为
{__name__="requests_total", path="/status", method="GET", instance="10.0.0.1:80"}
2、时间序列
Data scheme数据标识
identifier -> (t0, v0), (t1, v1), (t2, v2), (t3, v3), ...
Prometheus Data Model数据模型
<metric name>{<label name>=<label value>, ...}
Typical set of series identifiers

Query 查询
__name__="requests_total":查询所有属于requests_total的序列
method="PUT|POST":查询所有序列中方法是PUT或POST的序列
3、二维模型
Write 写:每个目标暴露成百上千个不同的时间序列,写入模式是完全垂直和高度并发的,因为来自每个目标的样本是独立的
Query 查:查询数据时可以并行和批处理
series
^
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="GET"}
│ . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="POST"}
│ . . . . . . .
│ . . . . . . . . . . . . . . . . . . . ...
│ . . . . . . . . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . . . . . {__name__="errors_total", method="POST"}
│ . . . . . . . . . . . . . . . . . {__name__="errors_total", method="GET"}
│ . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . . . ...
│ . . . . . . . . . . . . . . . . . . . .
v
<-------------------- time --------------------->
二维模型中横轴表示时间,纵轴表示各数据点
这类设计会带来的问题如下
存储问题

如上图所示,在二维模型中的读写差别是很大的
(时间序列查询)读时带来的随机读问题和查询带来的随机写问题,(查询)读往往会比写更复杂,这是很慢的。尽管用了SSD,但会带来写放大的问题,SSD是4k写,256k删除,SSD之所以快,实际上靠的是算法,因此在文件碎片如此大的情况下,都是不能满足的
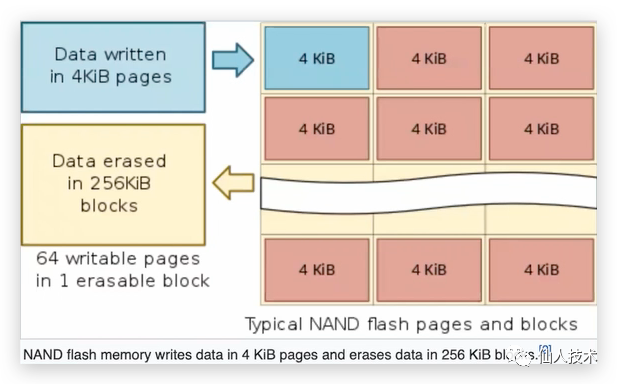
理想状态下的写应该是顺序写、批量写,对于相同的时间序列读应该也是顺序读
4、存储策略的演进
4.1 1.x 版本
1.x 版本下,存储情况是这样的
每个时间序列都对应一个文件 在内存中批量处理 1kb 的的 chunk
┌──────────┬─────────┬─────────┬─────────┬─────────┐ series A
└──────────┴─────────┴─────────┴─────────┴─────────┘
┌──────────┬─────────┬─────────┬─────────┬─────────┐ series B
└──────────┴─────────┴─────────┴─────────┴─────────┘
. . .
┌──────────┬─────────┬─────────┬─────────┬─────────┬─────────┐ series XYZ
└──────────┴─────────┴─────────┴─────────┴─────────┴─────────┘
chunk 1 chunk 2 chunk 3 ...
存在的问题:
chunk保存在内存中,如果应用程序或节点崩溃,它可能会丢失由于时间序列的维度很多,对于的文件个数也会很多,这可能耗尽操作系统的
inode上千的
chunk保存在硬盘需要持久化,可能会导致磁盘I/O非常繁忙磁盘
I/O打开很多的文件,会导致非常高的延迟旧数据需要清理,这可能会导致
SSD的写放大非常大的
CPU、内存、磁盘资源消耗序列的丢失和变动
例如一些时间序列变得不活跃,而另一些时间序列变得活跃,原因在于例如k8s中应用程序的连续自动扩展和频繁滚动更新带来的实例的ip等变化,每天可能会创建数万个新应用程序实例,以及全新的时间序列集
因此,即使整个基础设施的规模大致保持不变,随着时间的推移,数据库中的时间序列也会线性增长。即使Prometheus服务器能够收集1000万个时间序列的数据,但如果必须在10亿个序列中找到数据,查询性能会受到很大影响
series
^
│ . . . . . .
│ . . . . . .
│ . . . . . .
│ . . . . . . .
│ . . . . . . .
│ . . . . . . .
│ . . . . . .
│ . . . . . .
│ . . . . .
│ . . . . .
│ . . . . .
v
<-------------------- time --------------------->
4.2 2.x 版本
2.x 时代的存储布局
https://github.com/prometheus/prometheus/blob/release-2.25/tsdb/docs/format/README.md
4.2.1 数据存储分块
01xxxxx 数据块
ULID,和UUID一样,但是是按照字典和编码的创建时间排序的chunk 目录
包含各种系列的原始数据点块,但不再是每个序列对应一个单一的文件
index 数据索引
可以通过标签找到数据,这里保存了
Label和Series的数据meta.json 可读元数据
对应存储和它包含的数据的状态
tombstone
删除的数据将被记录到这个文件中,而不是从块文件中删除
wal 预写日志 Write-Ahead Log
WAL段将被截断到checkpoint.X目录中chunks_head
在内存中的数据
数据将每 2 小时保存到磁盘中
WAL 用于数据恢复
2 小时块可以高效查询范围数据
分块存储后,每个目录都是独立的存储目录,结构如下:
$ tree ./data
./data
├── b-000001
│ ├── chunks
│ │ ├── 000001
│ │ ├── 000002
│ │ └── 000003
│ ├── index
│ └── meta.json
├── b-000004
│ ├── chunks
│ │ └── 000001
│ ├── index
│ └── meta.json
├── b-000005
│ ├── chunks
│ │ └── 000001
│ ├── index
│ └── meta.json
└── b-000006
├── meta.json
└── wal
├── 000001
├── 000002
└── 000003
分块存储对应着Blocks,可以看做是小型数据库
将数据分成互不重叠的块
每个块都充当一个完全独立的数据库
包含其时间窗口的所有时间序列数据
有自己的索引和块文件集
每个数据块都是不可变的
当前块可以追加数据
所有新数据都写入内存数据库
为了防止数据丢失,还写了一个临时 WAL
t0 t1 t2 t3 now
┌───────────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐
│ │ │ │ │ │ │ │ ┌────────────┐
│ │ │ │ │ │ │ mutable │ <─── write ──── ┤ Prometheus │
│ │ │ │ │ │ │ │ └────────────┘
└───────────┘ └───────────┘ └───────────┘ └───────────┘ ^
└──────────────┴───────┬──────┴──────────────┘ │
│ query
│ │
merge ─────────────────────────────────────────────────┘
4.2.2 block 合并
上面分离了block后,会带来的问题
当查询多个块时,必须将它们的结果合并到一个整体结果中 如果我们需要一个星期的查询,它必须合并 80 多个 block 块
t0 t1 t2 t3 t4 now
┌────────────┐ ┌──────────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐
│ 1 │ │ 2 │ │ 3 │ │ 4 │ │ 5 mutable │ before
└────────────┘ └──────────┘ └───────────┘ └───────────┘ └───────────┘
┌─────────────────────────────────────────┐ ┌───────────┐ ┌───────────┐
│ 1 compacted │ │ 4 │ │ 5 mutable │ after (option A)
└─────────────────────────────────────────┘ └───────────┘ └───────────┘
┌──────────────────────────┐ ┌──────────────────────────┐ ┌───────────┐
│ 1 compacted │ │ 3 compacted │ │ 5 mutable │ after (option B)
└──────────────────────────┘ └──────────────────────────┘ └───────────┘
4.2.3 数据保留
|
┌────────────┐ ┌────┼─────┐ ┌───────────┐ ┌───────────┐ ┌───────────┐
│ 1 │ │ 2 | │ │ 3 │ │ 4 │ │ 5 │ . . .
└────────────┘ └────┼─────┘ └───────────┘ └───────────┘ └───────────┘
|
|
retention boundary
第1块可以被安全删除,第2块必须保持直到它完全超出边界
块合并带来的影响
块压缩可能使块太大而无法删除 需要限制块的大小
最大块大小 = 保留窗口 * 10%
4.2.4 查询和索引
主要特点
使用倒排索引,倒排索引提供基于其内容子集的数据项的快速查找。例如,可以查找所有具有标签的系列,
app=”nginx"而无需遍历每个系列并检查它是否包含该标签正向索引,为每个序列分配一个唯一的
ID,通过它可以在恒定的时间内检索
一个目录中保存了很多Series,如果想要根据一个Label来查询对应的所有Series,具体流程是什么呢
为每个Series中的所有Label都建立了一个倒排索引
| Label | Series |
|---|---|
__name__="requests_total" | {__name__="requests_total", path="/status", method="GET", instance=”10.0.0.1:80”} |
path="/status" | {__name__="requests_total", path="/status", method="GET", instance=”10.0.0.1:80”} |
method="GET" | {__name__="requests_total", path="/status", method="GET", instance=”10.0.0.1:80”} |
instance=”10.0.0.1:80” | {__name__="requests_total", path="/status", method="GET", instance=”10.0.0.1:80”} |
正向索引的引入,给每个Series分配了一个ID,便于组合查询
| Label | SeriesID |
|---|---|
__name__="requests_total" | 1001 |
path="/status" | 1001 |
method="GET" | 1001 |
instance=”10.0.0.1:80” | 1001 |
例如,如果查询的语句是:__name __ =“requests_total” AND app =“nginx”
需要先分别找出对应的倒排索引,再求交集,由此会带来一定的时间复杂度O(N2,为了减少时间复杂度,实际上倒排索引中的SeriesID是有序的,那么采取ZigZag的查找方式,可以保证在O(N)的时间复杂来找到最终的结果
4.2.6 WAL
通过mmap(不经过文件系统的写数据方式),同时在内存和WAL预写日志Write-Ahead Log中保存数据,即可以保证数据的持久不丢失,又可以保证崩溃之后从故障中恢复的时间很短,因为是从内存中恢复
4.2.7 小结
新的存储结构带来的好处
在查询某个时间范围时,可以轻松忽略该范围之外的所有数据块。它通过减少检查数据集来轻松解决数据流失问题 当完成一个块时,可以通过顺序写入一些较大的文件来保存内存数据库中的数据。避免任何写放大,并同样为 SSD和HDD提供服务保留了 V2的良好特性,即最近查询最多的块总是在内存中的不再受限于固定的 1KiB块大小来更好地对齐磁盘上的数据。可以选择对单个数据点和所选压缩格式最有意义的任何大小删除旧数据变得非常便宜和即时,只需要删除一个目录。在旧版本的存储中,必须分析和重写多达数亿个文件,这可能需要数小时才能收敛
参考资料
https://www.bilibili.com/video/BV1a64y1X7ys
[2]https://fabxc.org/tsdb/
[3]http://ganeshvernekar.com/blog/prometheus-tsdb-the-head-block/