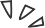光动嘴就能玩原神!用AI切换角色,还能攻击敌人,网友:“绫华,使用神里流·霜灭”

大数据文摘出品
作者:原神长期长草玩家
说到这两年风靡全球的国产游戏,原神肯定是当仁不让。
根据5月公布的本年度Q1季度手游收入调查报告,在抽卡手游里《原神》以5.67亿美金的绝对优势稳稳拿下第一,这也宣告《原神》在上线短短18个月之后单在手机平台总收入就突破30亿美金(大约RM130亿)。
如今,开放须弥前最后的2.8海岛版本姗姗来迟,在漫长的长草期后终于又有新的剧情和区域可以肝了。
不过不知道有多少“肝帝”,现在海岛已经满探索,又开始长草了。
长草期根本没在怕的,原神区从来不缺整活儿。
这不,在长草期间,就有玩家用XVLM+wenet+STARK做了一个语音控制玩原神的项目。
比如,当说出“用战术3攻击中间的火史莱姆”时,钟离先是一个套盾,凌华一个霰步后紧接着一个“失礼了”,团灭了4只火史莱姆。

同样,在说出“攻击中间的大丘丘人”后,迪奥娜长E套盾,凌华紧接着一个E然后3A一重漂亮地收拾掉了两只大丘丘人。

可以在左下方看到,整个过程都没有用手进行任何操作。
文摘菌直呼内行,以后打本连手也能省了,并表示妈妈再也不用担心玩原神玩出腱鞘炎了!
目前该项目已经在GitHub上开源:
GitHub链接:
好好的原神,硬是被玩成了神奇宝贝
这样的整活项目自然也是吸引到了不少原神长草玩家的目光。
比如有玩家就建议到,可以设计得更中二一点,直接用角色名加技能名,毕竟“战术3”这样的指令观众也无法第一时间知道,而“钟离,使用地心”就很容易代入游戏体验。

更有网友表示,既然都能对怪指令,那是不是也可以对人物语音,比如“龟龟,使用霜灭”。
龟龟每日疑惑.jpg
不过,这么这些指令怎么看上去有股似曾相识的味道?

对此up主“薛定谔の彩虹猫”表示,喊技能的话语速可能会跟不上,攻击速度会变慢,这才自己预设了一套。

不过像是一些经典队伍,比如“万达国际”“雷九万班”的输出手法倒也算是相对固定,预设攻击顺序和模式似乎也行得通。
当然除了玩梗之外,网友们也在集思广益,提出了不少优化意见。
比如直接用“1Q”让1号位角色放大招,重击用“重”表示,闪避则用“闪”,这样的话下达指令也能更简单迅速一些,或许还能用来打深渊。

也有内行玩家表示,这个AI似乎有点“不大理解环境”,“下一步可以考虑加上SLAM”,“实现360度的全方位目标检测”。

up主表示,下一步要做“全自动刷本,传送,打怪,领奖励一条龙”,那似乎也还可以加一个自动强化圣遗物功能,歪了就把AI格式化了。

原神区硬核整活up主还出过“提瓦特钓鱼指南”
正如文摘菌所说,原神区从不缺整活儿,而这位up主“薛定谔の彩虹猫”应该是其中最“硬核”的了。
从“AI自动摆放迷宫”,到“AI自动演奏”,原神出的每个小游戏可以说是应AI尽AI了。
其中文摘菌也发现了“AI自动钓鱼”项目(好家伙原来也是你),只需要启动程序,提瓦特的鱼全都能变成囊中之物。
原神自动钓鱼AI由两部分模型组成:YOLOX和DQN:
YOLOX 用于鱼的定位和类型的识别以及鱼竿落点的定位;
DQN 用于自适应控制钓鱼过程的点击,让力度落在最佳区域内。
此外,该项目还用到了迁移学习、半监督学习来进行训练。模型也包含了一些使用opencv等传统数字图像处理方法实现的不可学习部分。

项目地址:
https://github.com/7eu7d7/genshin_auto_fish
等3.0更新后还需要钓鱼获得的“咸鱼弓”,就拜托你了!
那些把原神变成神奇宝贝的“神器”
作为一个严肃的人,文摘菌觉得也有必要给大家科普一下这次原神语音项目用到的几个“神器”。
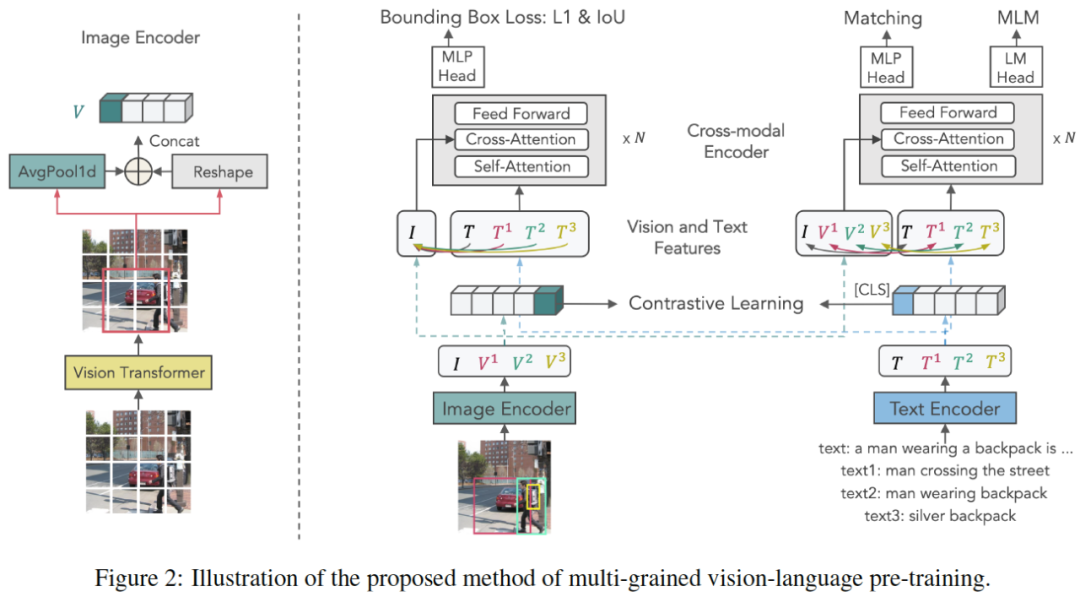
X-VLM是一种基于视觉语言模型(VLM)的多粒度模型,由图像编码器、文本编码器和跨模态编码器组成,跨模态编码器在视觉特征和语言特征之间进行跨模态注意,以学习视觉语言对齐。
学习多粒度对齐的关键是优化X-VLM:1)通过结合边框回归损失和IoU损失,在给定关联文本的图像中定位视觉概念;2)同时,通过对比损失、匹配损失和掩码语言建模损失,将文本与视觉概念进行多粒度对齐。
在微调和推理中,X-VLM可以利用学习到的多粒度对齐来执行下游的V+L任务,而无需在输入图像中添加边框注释。
论文链接:
WeNet是一个面向生产的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时来处理流式和非流式解码模式。
就在今年7月初的时候,WeNet推出2.0版本,并在4个方面进行了更新:
U2++:具有双向注意力解码器的统一双通道框架,包括从右到左注意力解码器的未来上下文信息,以提高共享编码器的表示能力和重新评分阶段的性能;
引入了基于n-gram的语言模型和基于WFST的解码器,促进了富文本数据在生产场景中的使用;
设计了统一的上下文偏置框架,该框架利用用户特定的上下文为生产提供快速适应能力,并在“有LM”和“无LM”两大场景中提高ASR准确性;
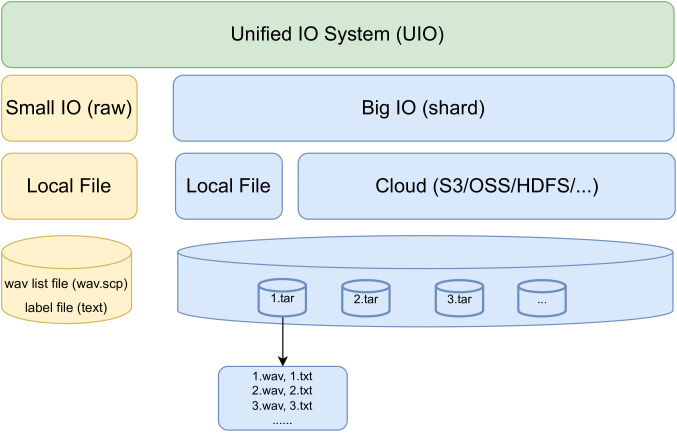
设计了一个统一的IO来支持大规模数据进行有效的模型训练。
从结果上看,WeNet 2.0在各种语料库上比原来的WeNet实现了高达10%的相对识别性能提升。
论文链接:
https://arxiv.org/pdf/2203.15455.pdf
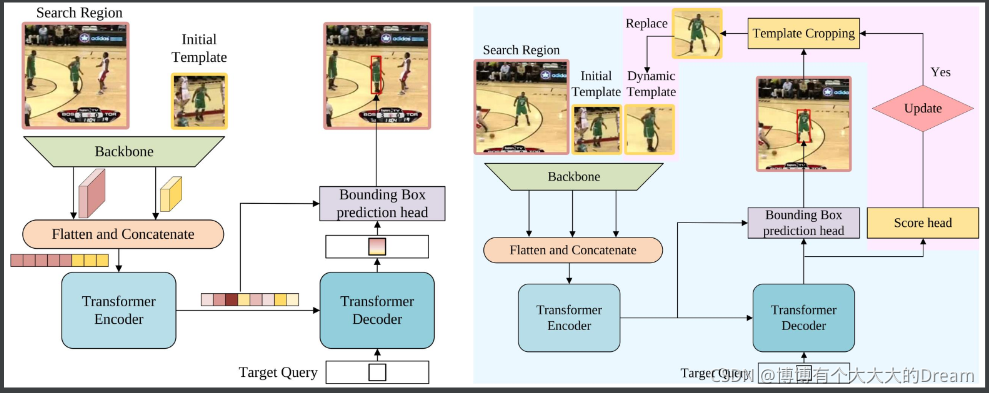
STARK是一种用于视觉跟踪的时空变换网络。基于由卷积主干、编解码器转换器和bounding box预测头组成的baseline的基础上,STARK做了3点改进:
动态更新模板:以中间帧作为动态模板加入输入中。动态模板可捕获外观变化,提供额外时域信息;
score head:判断当前是否更新动态模板;
训练策略改进:将训练分为两个阶段1)除了score head外,用baseline的损失函数训练。确保所有搜索图像包含目标并让模板拥有定位能力;2)用交叉熵只优化score head,此时冻结其他参数,以此让模型拥有定位和分类能力。
论文链接:
https://openaccess.thecvf.com/content/ICCV2021/papers/Yan_Learning_Spatio-Temporal_Transformer_for_Visual_Tracking_ICCV_2021_paper.pdf
有时候,游戏和学习并不是完全泾渭分明的,只要换个思路,两者也能结合得非常好。
不知道各位长草玩家觉得这个语音玩原神项目如何,欢迎在评论区发表自己的观点~