一键中文数据增强工具

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
使用:pip install nlpcda
https://github.com/425776024/nlpcda
介绍
一键中文数据增强工具,支持:
1.随机实体替换
2.近义词
3.近义近音字替换
4.随机字删除(内部细节:数字时间日期片段,内容不会删)
5.NER类
BIO数据增强6.随机置换邻近的字:研表究明,汉字序顺并不定一影响文字的阅读理解<<是乱序的
7.中文等价字替换(1 一 壹 ①,2 二 贰 ②)
8.翻译互转实现的增强
9.使用
simbert做生成式相似句生成
经过细节特殊处理,比如不改变年月日数字,尽量保证不改变原文语义。即使改变也能被猜出来、能被猜出来、能被踩出来、能被菜粗来、被菜粗、能菜粗来.
WIP
基于语音的洗文本过程(类似翻译)。
文本转语音>语音识别回文本:基于fastspeech2对文本生成语音,基于wav2vec2语音识别文本
例子:
input: 新华社北京消息 >
fastspeech2> x.wavx.wav >
wav2vec2> output: 新华设北京消息
数字转换工具(用于文本转换、中文语音合成需要纯中文)
今天是8月29日消息 > 今天是八月二十九日消息
我有1234个苹果 > 我有一千二百三十四个苹果
意义
在不改变原文语义的情况下,生成指定数量的训练语料文本
对NLP模型的泛化性能、对抗攻击、干扰波动,有很好的提升作用
参考比赛(本人用此策略+base bert拿到:50+-/1000):https://www.biendata.com/competition/2019diac/
⚠️ 单纯刷准确率分数的比赛,用此包一般不会有分数提升
API
1.随机(等价)实体替换
参数:
base_file :缺省时使用内置(公司)实体。对公司实体进行替换
是文本文件路径,内容形如:
实体1
实体2
...
实体ncreate_num=3 :返回最多3个增强文本
change_rate=0.3 :文本改变率
seed :随机种子
2.随机同义词替换
参数:
base_file :缺省时使用内置同义词表,你可以设定/自己指定更加丰富的同义词表:
是文本文件路径,内容形如(空格隔开):
Aa01A0 人类 生人 全人类
id2 同义词b1 同义词b2 ... 同义词bk
...
idn 同义词n1 同义词n2\create_num=3 :返回最多3个增强文本
change_rate=0.3 :文本改变率
seed :随机种子
3.随机近义字替换
参数:
base_file :缺省时使用内置【同义同音字表】,你可以设定/自己指定更加丰富的同义同音字表:
是文本文件路径,内容形如(\t隔开):
de 的 地 得 德 嘚 徳 锝 脦 悳 淂 鍀 惪 恴 棏
拼音2 字b1 字b2 ... 字bk
...
拼音n 字n1 字n2\create_num=3 :返回最多3个增强文本
change_rate=0.3 :文本改变率
seed :随机种子
4.随机字删除
参数:
create_num=3 :返回最多3个增强文本
change_rate=0.3 :文本改变率
seed :随机种子
5.NER命名实体 数据增强
输入标注好的NER数据目录,和需要增强的标注文件路径,和增强的数量,即可一键增强
Ner类参数:
ner_dir_name='ner_data' : 在ner数据放在ner_data目录下(里面很多.txt)
ner_dir_name提供的目录下是各种标注数据文件,文件内容以标准的NER 的BIO格式分开
6.随机置换邻近的字
char_gram=3:某个字只和邻近的3个字交换
内部细节:遇到数字,符号等非中文,不会交换
7.等价字替换
参数:
base_file :缺省时使用内置【等价数字字表】,你可以设定/自己指定更加丰富的等价字表(或者使用函数:add_equivalent_list):
是文本文件路径,内容形如((\t)隔开):
0 零 〇
1 一 壹 ①
...
9 九 玖 ⑨create_num=3 :返回最多3个增强文本
change_rate=0.3 :文本改变率
seed :随机种子
添加自定义词典
用于使用之前,增加分词效果
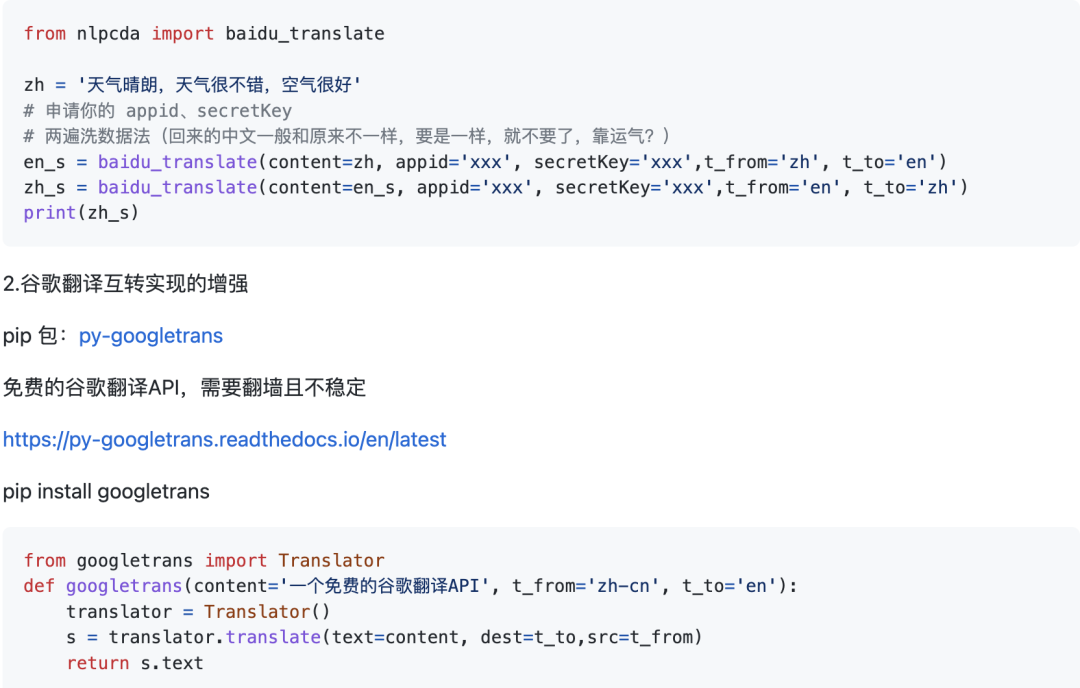
8.翻译互转实现的增强
1.百度中英翻译互转实现的增强 note:
申请你的 appid、secretKey: http://api.fanyi.baidu.com/api/trans
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx