
【小白学PyTorch】17.TFrec文件的创建与读取
小白学PyTorch | 15 TF2实现一个简单的服装分类任务
小白学PyTorch | 14 tensorboardX可视化教程
小白学PyTorch | 13 EfficientNet详解及PyTorch实现
小白学PyTorch | 12 SENet详解及PyTorch实现
小白学PyTorch | 11 MobileNet详解及PyTorch实现
小白学PyTorch | 9 tensor数据结构与存储结构
小白学PyTorch | 7 最新版本torchvision.transforms常用API翻译与讲解
小白学PyTorch | 6 模型的构建访问遍历存储(附代码)
小白学PyTorch | 5 torchvision预训练模型与数据集全览
小白学PyTorch | 3 浅谈Dataset和Dataloader
参考目录:
1 为什么用tfrec文件
2 tfrec文件的内部结构
3 制作tfrec文件
4 读取tfrec文件
本文的代码已经上传公众号后台,回复【PyTorch】获取。
第一次接触到TFrec文件,我也是比较蒙蔽的其实: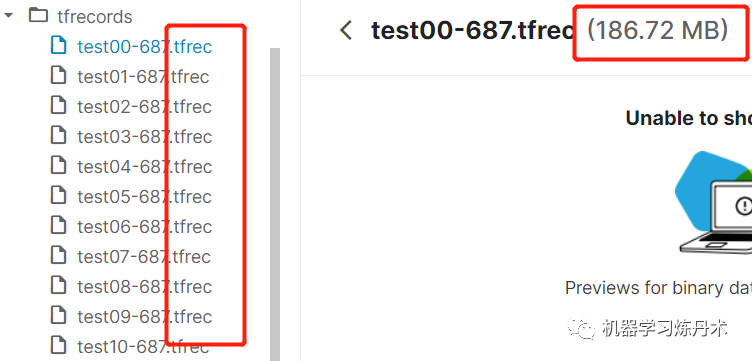
可以看到文件是.tfrec后缀的,而且先记住这个文件是186.72MB大小的。
1 为什么用tfrec文件
正常情况下我们用于训练的文件夹内部往往会存着成千上万的图片或文本等文件,这些文件通常被散列存放。这种存储方式有一些缺点:
占用磁盘空间; 一个一个读取文件消耗时间
而tfrec格式的文件存储形式会很合理的帮我们存储数据,核心就是tfrec内部使用Protocol Buffer的二进制数据编码方案,这个方案可以极大的压缩存储空间。
之前我们知道一个tfrec文件100多M,这是因为这个tfrec文件内存储了很多的图片,类似于压缩,对tfrec解压缩后可以获取到一部分的数据集,当我们把全部的rfrec文件都解压缩后,可以获取到全部的数据集。
值得一提的是,rfrec文件内除了可以存储图片,还可以存储其他的数据,比方说图片的label。字符串,float类型等都可以转换成二进制的方法,所以什么数据类型基本上都可以存储到rfrec文件内,从而简化读取数据的过程。
2 tfrec文件的内部结构
tfrec文件时tensorflow的数据集存储格式,tensorflow可以高效的读取和处理这些数据集,因此我见过有的数据集因为是tfrec文件,所以用TF读取数据集,然后用pytorch训练模型。
之前提到了tfrec文件里面是有多个样本的,所以tfrec可以为是多个tf.train.Example文件组成的序列(每一个example是一个样本),然后每一个tf.train.Example又是由若干个tf.train.Features字典组成。这个Features可以理解为这个样本的一些信息,如果是图片样本,那么肯定有一个Features是图片像素值数据,一个Features是图片的标签值;如果是预测任务,那么这个Feature可能就是一些字符串类型的特征
3 制作tfrec文件
import tensorflow as tf
import glob
# 先记录一下要保存的tfrec文件的名字
tfrecord_file = './train.tfrec'
# 获取指定目录的所有以jpeg结尾的文件list
images = glob.glob('./*.jpeg')
with tf.io.TFRecordWriter(tfrecord_file) as writer:
for filename in images:
image = open(filename, 'rb').read() # 读取数据集图片到内存,image 为一个 Byte 类型的字符串
feature = { # 建立 tf.train.Feature 字典
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])), # 图片是一个 Bytes 对象
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[1])),
'float':tf.train.Feature(float_list=tf.train.FloatList(value=[1.0,2.0])),
'name':tf.train.Feature(bytes_list=tf.train.BytesList(value=[str.encode(filename)]))
}
# tf.train.Example 在 tf.train.Features 外面又多了一层封装
example = tf.train.Example(features=tf.train.Features(feature=feature)) # 通过字典建立 Example
writer.write(example.SerializeToString()) # 将 Example 序列化并写入 TFRecord 文件
代码中我们需要注意的地方是:
先读取图片,然后构建一个字典来作为这个example的格式; 上面代码中,字典中有四个属性,首先是image图片本身的像素值,然后有一个标签,标签是int类型,然后有一个float浮点类型,name是一个字符串类型,这个string类型的需要转换成byte字节类型的才能进行存储,所以这里使用 str.encode来把字符串转换成字节;然后这个features再经过Example的封装,再然后把这个example写进这个tfrec文件中。
这一段代码建议保存下来,方便以后的直接参考和复制。构建tfrec文件对于tensorflow处理图片来说,应该是绕不过的一个步骤。
4 读取tfrec文件
现在,我们运行完上面的代码,应该生成了一个./train.tfrec文件,下面我们再对这个文件进行读取。
import tensorflow as tf
dataset = tf.data.TFRecordDataset('./train.tfrec')
def decode(example):
feature_description = {
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64),
'float': tf.io.FixedLenFeature([1, 2], tf.float32),
'name': tf.io.FixedLenFeature([], tf.string)
}
feature_dict = tf.io.parse_single_example(example, feature_description)
feature_dict['image'] = tf.io.decode_jpeg(feature_dict['image']) # 解码 JEPG 图片
return feature_dict
dataset = dataset.map(decode).batch(4)
for i in dataset.take(1):
print(i['image'].shape)
print(i['label'].shape)
print(i['float'].shape)
print(bytes.decode(i['name'][0].numpy()))
首先使用专门用来读取tfrec文件的方法 tf.data.TFRecordDataset,进行读取,创建了一个dataset,但是这个dataset并不能直接使用,需要对tfrec中的example进行一些解码;自己写一个解码函数decode,首先写一个特征描述,我们知道在保存tfrec的时候每一个example有四个特征,这里需要对每一个特征确定他的类型,是string还是int还是float这样的。 然后通过这个特征描述和 tf.io.parse_single_example方法,从example中提取到对应的特征;因为image是一个图片张量,而我们读取的时候是读取的tf.string的类型,所以使用 tf.io.decode_jpeg()来把字符串解码成一个tensor张量。最后使用上节课讲过的 .batch(4)把数据集每一个batch包含四个样本。
上面代码输出的结果为:
需要注意的是这个如何把name转换成string类型的,如果已经在本地跑完了上面的代码,可以自己看看i['name']是一个什么类型的,然后自己试试如何转换成string类型的。上面的代码是能成功转换的。
下一次的内容就是如何构建模型,然后怎么把数据集喂给模型。
- END -往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):