
BERT-Large推理仅需1.2毫秒!NV发布最新TensorRT 8推理加速器

新智元报道
新智元报道
来源:Nvidia
编辑:Priscilla 好困
【新智元导读】近日,英伟达悄悄地发布了TensorRT 8,BERT-Large推理仅需1.2毫秒!同时还加入了量化感知训练和对稀疏性的支持,实现了性能200%的提升。项目已开源。
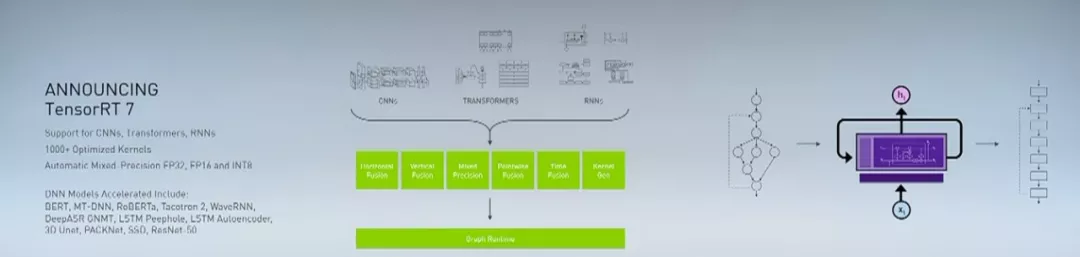
2019年黄仁勋在GTC China正式发布了TensorRT 7,并称其是「我们实现的最大飞跃」。
然而今年TensorRT 8的发布却十分低调。

相比于7.0,TensorRT 8可以说是实现了2倍的性能提升。
在1.2毫秒内实现BERT-Large的推理
通过量化感知训练让INT8的精度达到了与FP32相当的水平
支持稀疏性,让Ampere GPU拥有更快的推理速度
TensorRT
TensorRT
7.0
7.0
推理速度更快
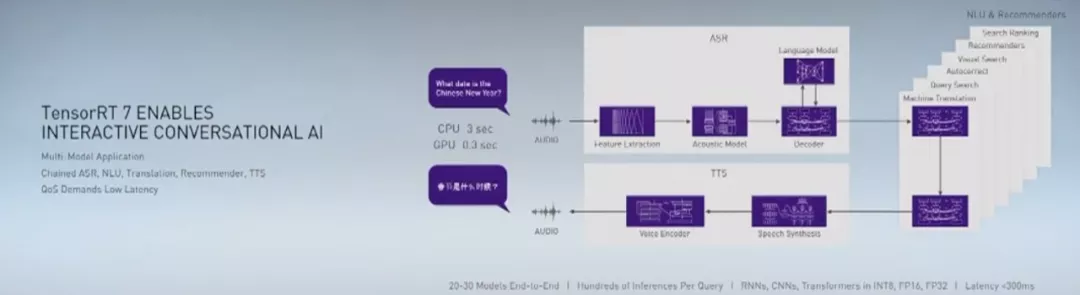
大型语言模型(LSLM),如BERT、GPT-2和XL-Net,极大提升了许多自然语言处理(NLP)任务的准确性。
自2018年10月发布以来,BERT(Bidirectional Encoder Representations from Transformers)及其所有的许多变体,仍然是最受欢迎的语言模型之一,并且仍然可以提供SOTA的准确性。
推理速度更快
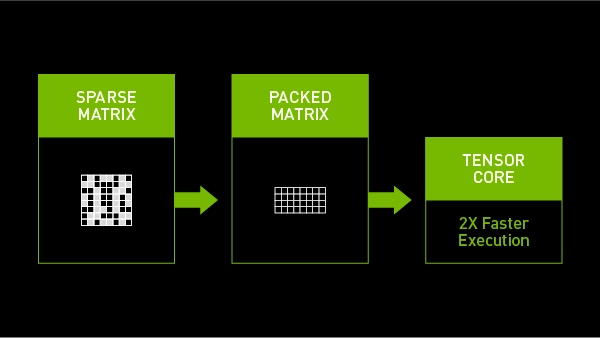
多年来,机器学习研究人员一直在努力使用数字来加速人工智能,目标是减少深度学习所需的矩阵乘法堆,缩短获得结果的时间。
在TensorRT 8中使用稀疏性技术,能够提升英伟达Ampere架构的GPU性能。
在保证推理精度的同时,降低深度学习模型中的部分权重,减小模型所需要的带宽和内存。
内存有富余,就可以分配给那些需要计算的部分,推理速度自然也上来了。
量化感知训练提高精度
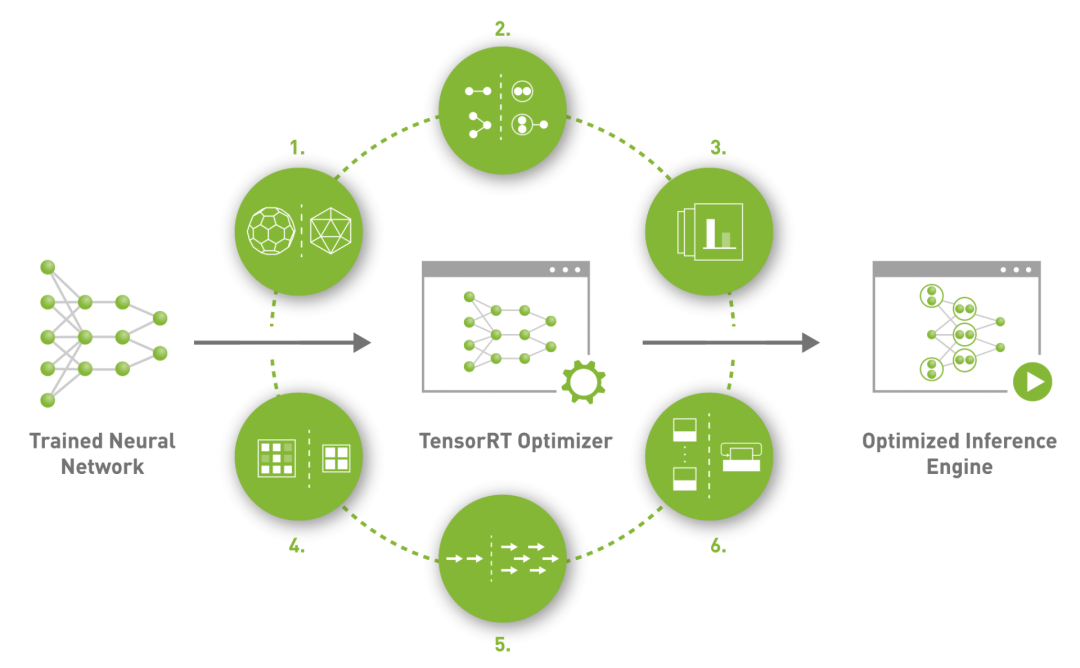
TensorRT的应用

部署TensorRT
下载TensorRT Build
git clone -b master https://github.com/nvidia/TensorRT TensorRTcd TensorRTgit submodule update --init --recursive
如果使用TensorRT OSS Build容器,TensorRT库已经预装在/usr/lib/x86_64-linux-gnu下。否则需要下载TensorRT GA build。
Ubuntu 18.04 x86-64 cuda-11.3
cd ~/Downloadstar -xvzf TensorRT-8.0.1.6.Ubuntu-18.04.x86_64-gnu.cuda-11.3.cudnn8.2.tar.gzexport TRT_LIBPATH=`pwd`/TensorRT-8.0.1.6Windows x86-64 cuda-11.3
cd ~\DownloadsExpand-Archive .\TensorRT-8.0.1.6.Windows10.x86_64.cuda-11.3.cudnn8.2.zip$Env:TRT_LIBPATH = '$(Get-Location)\TensorRT-8.0.1.6'$Env:PATH += 'C:\Program Files (x86)\Microsoft Visual Studio\2017\Professional\MSBuild\15.0\Bin\'
构建环境
1. 生成TensorRT-OSS Build容器
TensorRT-OSS Build容器可以使用提供的Dockerfiles和Build脚本来生成。
Ubuntu 18.04 x86-64 cuda-11.3
./docker/build.sh --file docker/ubuntu-18.04.Dockerfile --tag tensorrt-ubuntu18.04-cuda11.3 --cuda 11.3.1
2. 启动TensorRT-OSS Build容器
Ubuntu 18.04
./docker/launch.sh --tag tensorrt-ubuntu18.04-cuda11.3 --gpus all
构建TensorRT-OSS
生成Makefiles或VS项目(Windows)并构建。
Linux x86-64 cuda-11.3
cd $TRT_OSSPATHmkdir -p build && cd buildcmake .. -DTRT_LIB_DIR=$TRT_LIBPATH -DTRT_OUT_DIR=`pwd`/outmake -j$(nproc)
Windows x86-64 Powershell
cd $Env:TRT_OSSPATHmkdir -p build ; cd buildcmake .. -DTRT_LIB_DIR=$Env:TRT_LIBPATH -DTRT_OUT_DIR='$(Get-Location)\out' -DCMAKE_TOOLCHAIN_FILE=..\cmake\toolchains\cmake_x64_win.toolchainmsbuild ALL_BUILD.vcxproj
参考资料:
https://github.com/NVIDIA/TensorRT
https://developer.nvidia.com/blog/nvidia-announces-tensorrt-8-slashing-bert-large-inference-down-to-1-millisecond/
https://venturebeat.com/2021/07/20/nvidia-releases-tensorrt-8-for-faster-ai-inference/
