
以北京大黄瓜为例,手把手教你使用scrapy抓取数据并存入MongoDB!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包


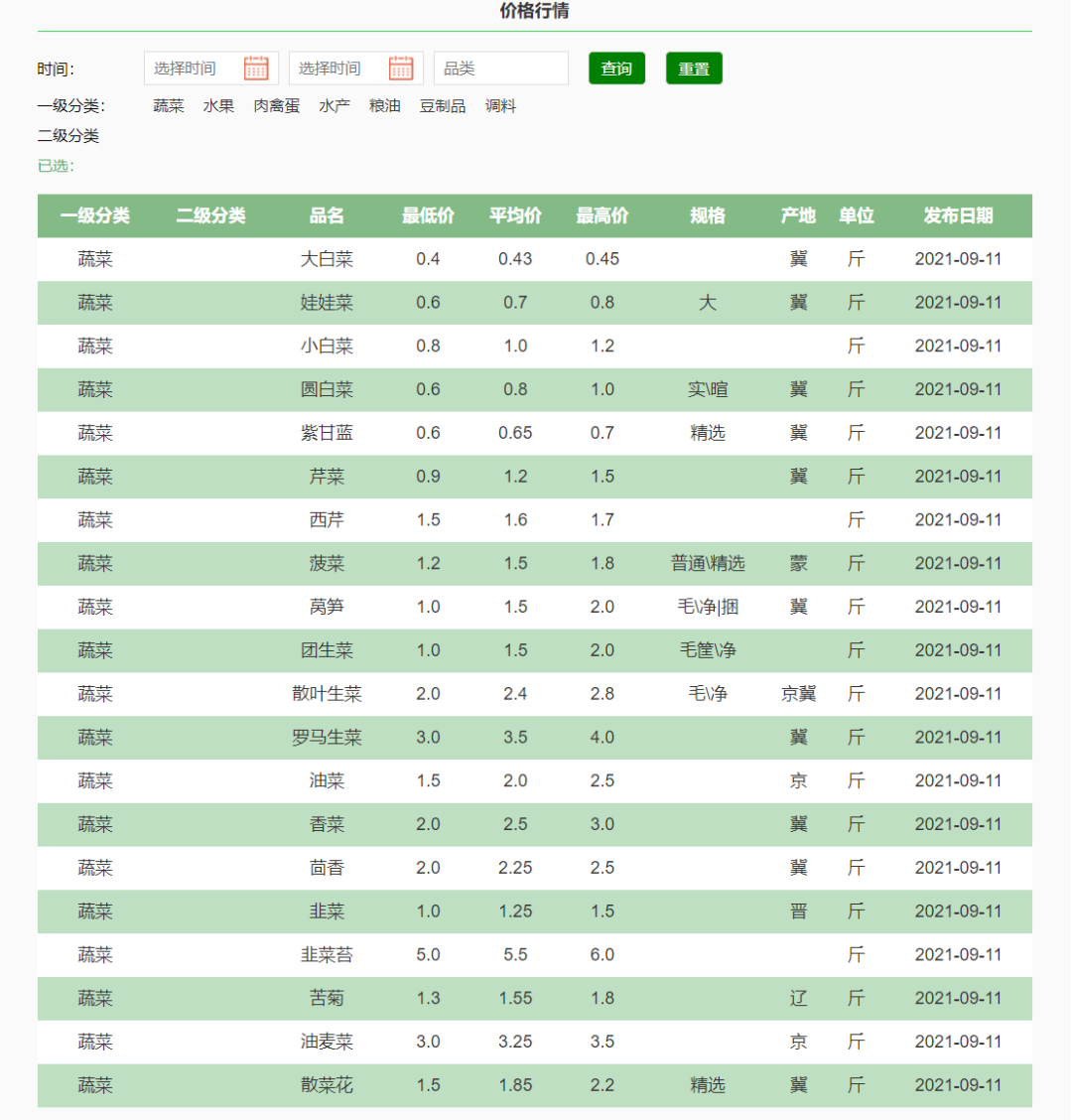
目标获取

spider爬虫
建立完毕结构图如下:
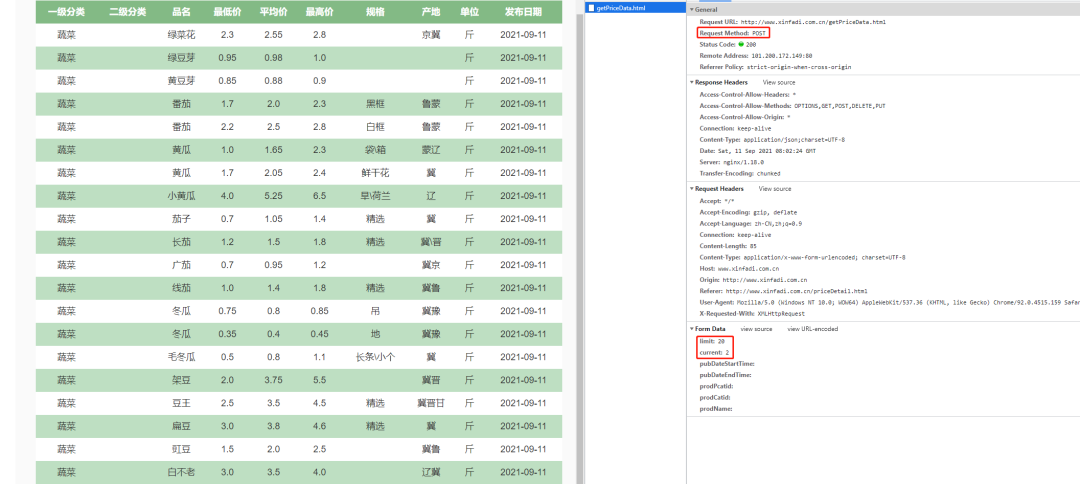
网页分析
F12打开网页源码,如下这是一个POST请求的网页,
分页参数由limit控制,页面显示由current控制
并且每页链接都是相同的,变化的只有分页参数limit。
所以我们可以构造一个请求url:
for page in range(1, 50+1):
url = f'http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t={page}'
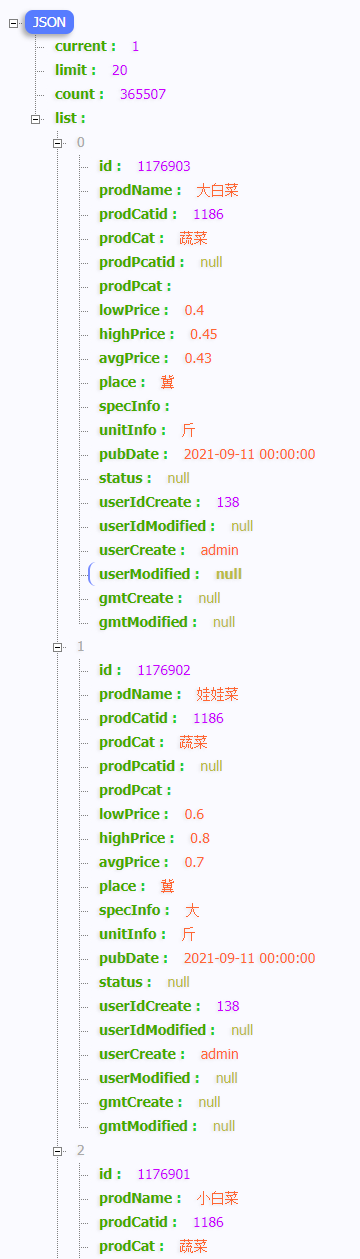
并且我们请求的数据是json结构,如下:
所有的内容都在如下list列表中
发送请求
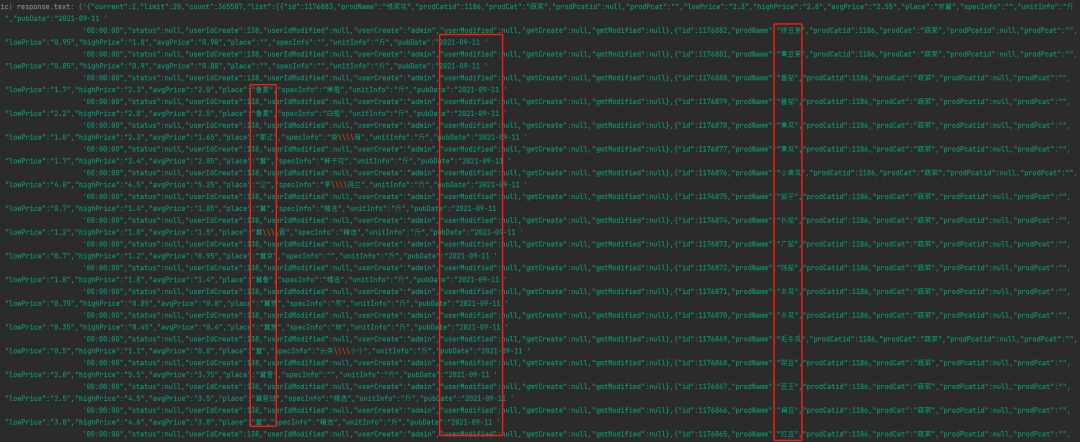
我们先来打印浏览器响应数据
ic(response.text)
结果如下,成功打印出了json结构的全部信息
但是我们需要的数据都在json结构的list列表中,所以还需要对请求到的数据进一步处理,获取list
# 获取蔬菜列表
veg_list = response.json()['list']
ic(veg_list)list结构数据打印如下:
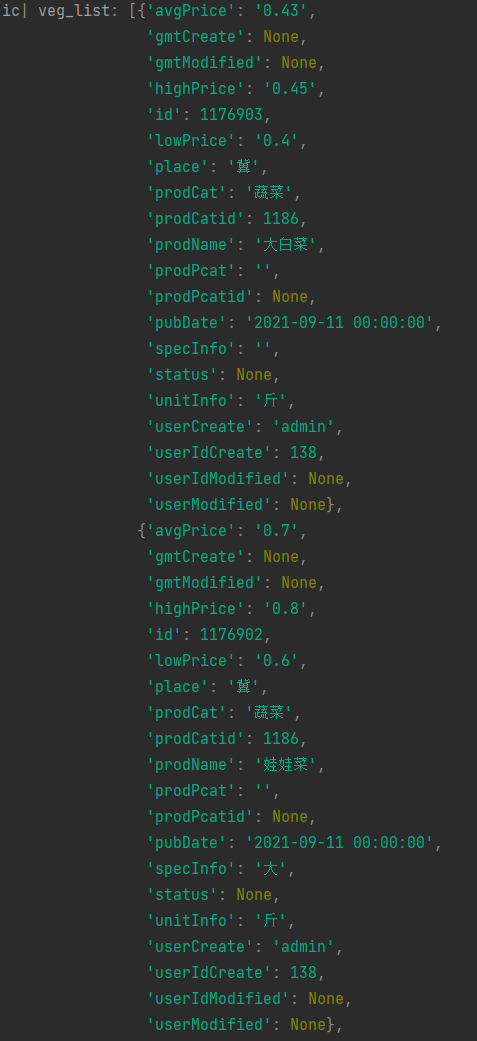
分析至此所有的信息都以获取到,接下来我们要做的就是提取我们要获取的数据
名称、最低价、最高价、均价、产地还有价格发布时间等
for veg in veg_list:
# 实例化scrapy对象
item = BjXinfaItem()
# 蔬菜名称
item['prodName'] = veg['prodName']
# 最低价格
item['lowPrice'] = veg['lowPrice']
# 最高价格
item['highPrice'] = veg['highPrice']
# 平均价格
item['avgPrice'] = veg['avgPrice']
# 产地
item['origin'] = veg['place']
# 日期
rlsDate = veg['pubDate']
item['rlsDate'] = ''.join(rlsDate).split(' ')[0]
'''
ic| item: {'avgPrice': '0.43',
'highPrice': '0.45',
'lowPrice': '0.4',
'origin': '冀',
'prodName': '大白菜',
'rlsDate': '2021-09-11'}
ic| item: {'avgPrice': '0.7',
'highPrice': '0.8',
'lowPrice': '0.6',
'origin': '冀',
'prodName': '娃娃菜',
'rlsDate': '2021-09-11'}
ic| item: {'avgPrice': '1.0',
'highPrice': '1.2',
'lowPrice': '0.8',
'origin': '',
'prodName': '小白菜',
'rlsDate': '2021-09-11'}
ic| item: {'avgPrice': '0.8',
'highPrice': '1.0',
'lowPrice': '0.6',
'origin': '冀',
'prodName': '圆白菜',
'rlsDate': '2021-09-11'}
ic| item: {'avgPrice': '0.65',
'highPrice': '0.7',
'lowPrice': '0.6',
'origin': '冀',
'prodName': '紫甘蓝',
'rlsDate': '2021-09-11'}
ic| item: {'avgPrice': '1.2',
'highPrice': '1.5',
'lowPrice': '0.9',
'origin': '冀',
'prodName': '芹菜',
'rlsDate': '2021-09-11'}
'''
存入数据
当我们要把数据保存成文件的时候,不需要任何额外的代码,只要执行如下代码即可:
scrapy crawl spider爬虫名 -o xxx.json #保存为JSON文件
scrapy crawl spider爬虫名 -o xxx.jl或jsonlines #每个Item输出一行json
scrapy crawl spider爬虫名 -o xxx.csv #保存为csv文件
scrapy crawl spider爬虫名 -o xxx.xml #保存为xml文件想要保存为什么格式的文件,只要修改后缀就可以了,在这里我就不一一例举了。
我们在此将其保存为json格式
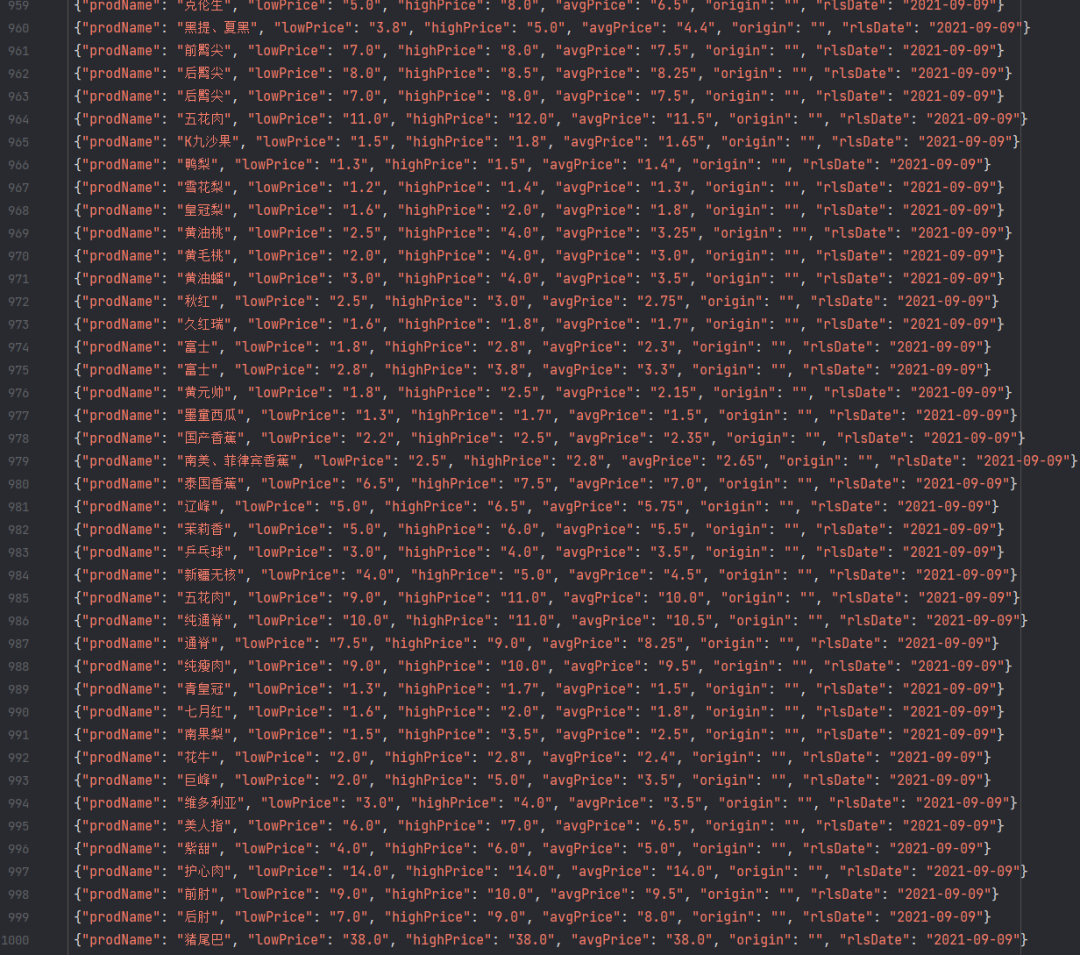
# 保存文件到本地
with open('./北京菜价.json', 'a+', encoding='utf-8') as f:
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
f.write(lines)每页20条数据,50页攻击1000条数据如下:
存入MongoDB
MongoDB的安装之前专门拉出来一节单独讲的,需要的小伙伴可以看一下
这里我们在setting中引入MongoDB。名称如下:
mongo_host = '127.0.0.1'
mongo_port = 27017
mongo_db_name = 'beijing'
mongo_db_collection = 'beijing_price'数据查询如下:
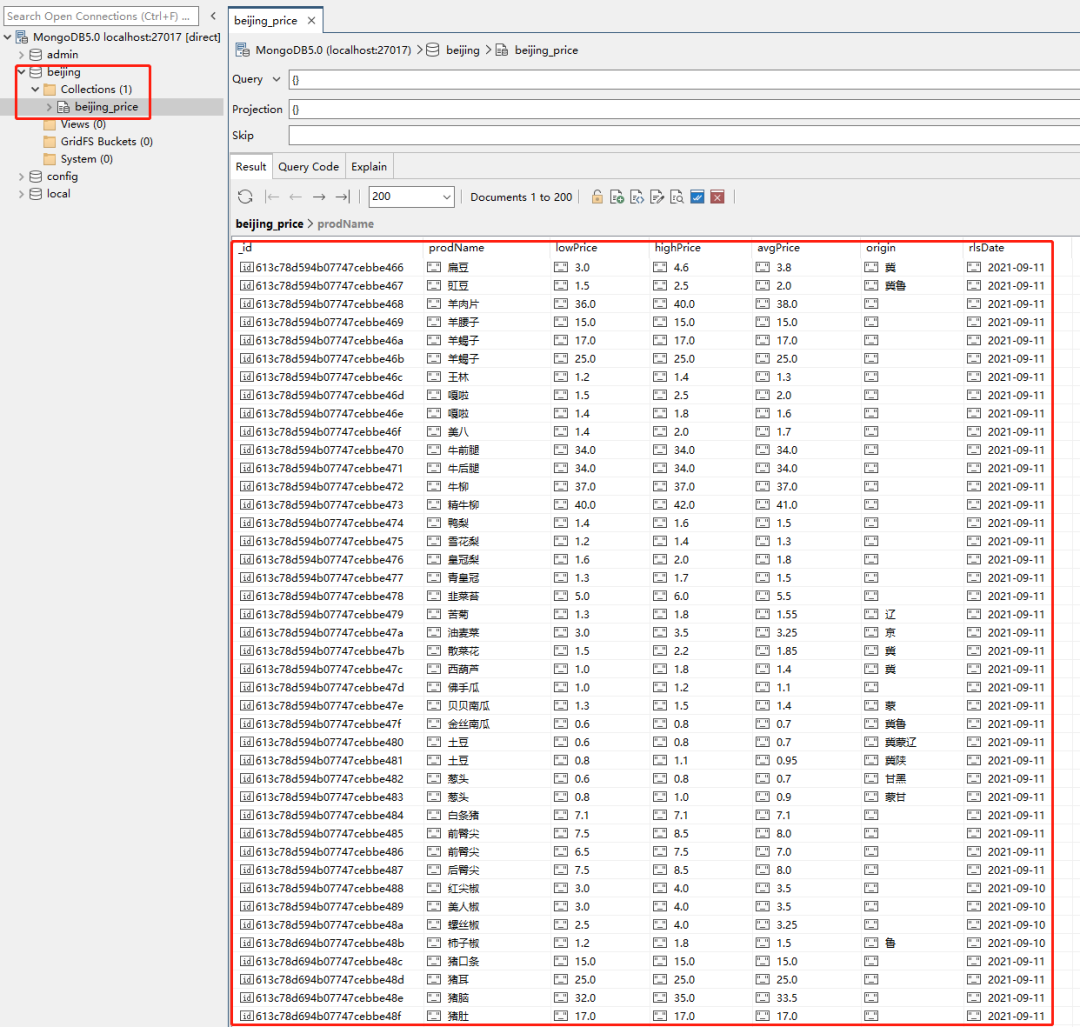
- END -
推荐阅读
推荐一个公众号,帮助程序员自学与成长
觉得还不错就给我一个小小的鼓励吧!

评论