
【关于Transformer】 那些的你不知道的事(上)
作者:杨夕
项目地址:https://github.com/km1994/nlp_paper_study
论文链接:https://arxiv.org/pdf/1706.03762.pdf
【注:手机阅读可能图片打不开!!!】
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
## 引言
本博客 主要 是本人在学习 Transformer 时的**所遇、所思、所解**,通过以 **十六连弹** 的方式帮助大家更好的理解 该问题。
## 十六连弹
1. 为什么要有 Transformer?
2. Transformer 作用是什么?
3. Transformer 整体结构怎么样?
4. Transformer-encoder 结构怎么样?
5. Transformer-decoder 结构怎么样?
6. 传统 attention 是什么?
7. self-attention 长怎么样?
8. self-attention 如何解决长距离依赖问题?
9. self-attention 如何并行化?
10. multi-head attention 怎么解?
11. 为什么要 加入 position embedding ?
12. 为什么要 加入 残差模块?
13. Layer normalization。Normalization 是什么?
14. 什么是 Mask?
15. Transformer 存在问题?
16. Transformer 怎么 Coding?
## 问题解答
### 一、为什么要有 Transformer?
为什么要有 Transformer? 首先需要知道在 Transformer 之前都有哪些技术,这些技术所存在的问题:
- RNN:能够捕获长距离依赖信息,但是无法并行;
- CNN: 能够并行,无法捕获长距离依赖信息(需要通过层叠 or 扩张卷积核 来 增大感受野);
- 传统 Attention
- 方法:基于源端和目标端的隐向量计算Attention,
- 结果:源端每个词与目标端每个词间的依赖关系 【源端->目标端】
- 问题:忽略了 远端或目标端 词与词间 的依赖关系
### 二、Transformer 作用是什么?
基于Transformer的架构主要用于建模语言理解任务,它避免了在神经网络中使用递归,而是完全依赖于self-attention机制来绘制输入和输出之间的全局依赖关系。
### 三、Transformer 整体结构怎么样?
1. 整体结构
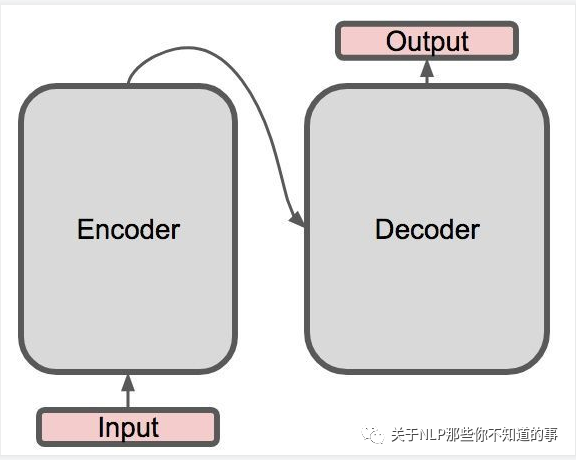
- Transformer 整体结构:
- encoder-decoder 结构
- 具体介绍:
- 左边是一个 Encoder;
- 右边是一个 Decoder;
2. 整体结构放大一点
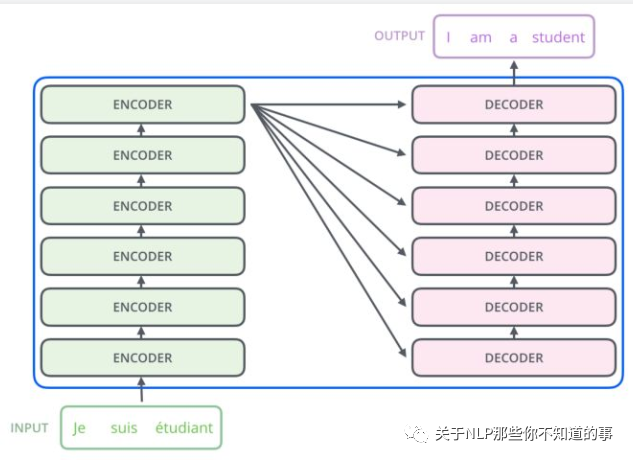
从上一张 Transformer 结构图,可以知道 Transformer 是一个 encoder-decoder 结构,但是 encoder 和 decoder 又包含什么内容呢?
- Encoder 结构:
- 内部包含6层小encoder 每一层里面有2个子层;
- Decoder 结构:
- 内部也是包含6层小decoder ,每一层里面有3个子层
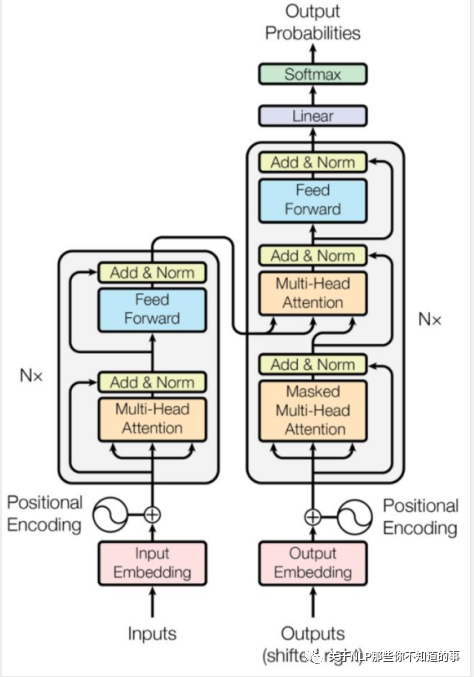
3. 整体结构再放大一点
其中上图中每一层的内部结构如下图所求。
- 上图左边的每一层encoder都是下图左边的结构;
- 上图右边的每一层的decoder都是下图右边的结构;
具体内容,后面会逐一介绍。
### 四、Transformer-encoder 结构怎么样?
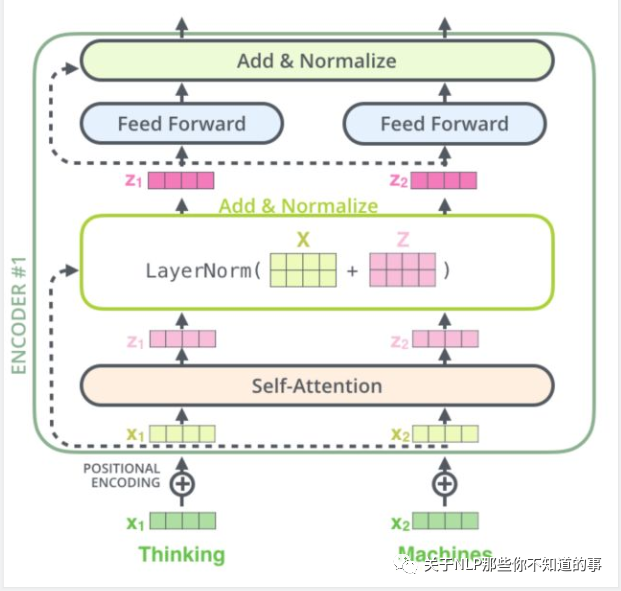
- 特点:
- 与 RNN,CNN 类似,可以当成一个特征提取器;
- 组成结构介绍
- embedding 层:将 input 转化为 embedding 向量 X;
- Position encodding: input的位置与 input 的 embedding X 相加 得到 向量 $X$;
- self-attention : 将融合input的位置信息 与 input 的 embedding 信息的 $X$ 输入 Self-Attention 层得到 Z;
- 残差网络:Z 与 X 相加后经过 layernorm 层;
- 前馈网络:经过一层前馈网络以及 Add&Normalize,(线性转换+relu+线性转换 如下式)

- 举例说明(假设序列长度固定,如100,如输入的序列是“我爱中国”):
- 首先需要 **encoding**:
- 将词映射成一个数字,encoding后,由于序列不足固定长度,因此需要padding,
- 然后输入 embedding层,假设embedding的维度是128,则输入的序列维度就是100*128;
- 接着是**Position encodding**,论文中是直接将每个位置通过cos-sin函数进行映射;
- 分析:这部分不需要在网络中进行训练,因为它是固定。但现在很多论文是将这块也embedding,如bert的模型,至于是encoding还是embedding可取决于语料的大小,语料足够大就用embedding。将位置信息也映射到128维与上一步的embedding相加,输出100*128
- 经过**self-attention层**:
- 操作:假设v的向量最后一维是64维(假设没有多头),该部分输出100*64;
- 经过残差网络:
- 操作:即序列的embedding向量与上一步self-attention的向量加总;
- 经过 **layer-norm**:
- 原因:
- 由于在self-attention里面更好操作而已;
- 真实序列的长度一直在变化;
- 经过 **前馈网络**:
- 目的:增加非线性的表达能力,毕竟之前的结构基本都是简单的矩阵乘法。若前馈网络的隐向量是512维,则结构最后输出100*512;
### 五、Transformer-decoder 结构怎么样?
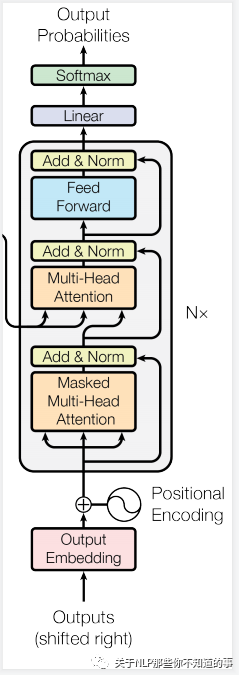
- 特点:与 encoder 类似
- 组成结构介绍
- masked 层:
- 目的:确保了位置 i 的预测仅依赖于小于 i 的位置处的已知输出;
- Linear layer:
- 目的:将由解码器堆栈产生的向量投影到一个更大的向量中,称为对数向量。这个向量对应着模型的输出词汇表;向量中的每个值,对应着词汇表中每个单词的得分;
- softmax层:
- 操作:这些分数转换为概率(所有正数,都加起来为1.0)。选择具有最高概率的单元,并且将与其相关联的单词作为该时间步的输出
## 参考资料
1. [Transformer理论源码细节详解](https://zhuanlan.zhihu.com/p/106867810)
2. [论文笔记:Attention is all you need(Transformer)](https://zhuanlan.zhihu.com/p/51089880)
3. [深度学习-论文阅读-Transformer-20191117](https://zhuanlan.zhihu.com/p/92234185)
4. [Transform详解(超详细) Attention is all you need论文](https://zhuanlan.zhihu.com/p/63191028)
5. [目前主流的attention方法都有哪些?](https://www.zhihu.com/question/68482809/answer/597944559)
6. [transformer三部曲](https://zhuanlan.zhihu.com/p/85612521)
7. [Character-Level Language Modeling with Deeper Self-Attention](https://aaai.org/ojs/index.php/AAAI/article/view/4182)
8. [Transformer-XL: Unleashing the Potential of Attention Models](https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html)
9. [The Importance of Being Recurrent for Modeling Hierarchical Structure](https://arxiv.org/abs/1803.03585)
10. [Linformer](https://arxiv.org/abs/2006.04768)
