
【关于 实体关系联合抽取论文】那些你不知道的事
撰写团队:whalePaper 深度学习学习小组 团队成员:杨夕、谢文睿、jepson、王翔、李威、李文乐、袁超逸
论文地址:https://github.com/km1994/whalePaperShare
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study
前言
这篇文章主要来自于 whalePaper 论文分享的知识沉淀
whalePaper 想做的事:
选取比较成熟的 Topic 和 做一些 开源方案 分享;
给 whalePaper 成员一个一起看论文一起讨论的空间,以帮助组织成员更好“高效+全面”学习;
认识更多更优秀的小伙伴!
一、实体关系联合抽取介绍
实体关系抽取(Entity and Relation Extraction,ERE)是信息抽取的关键任务之一。对于以下给定一段文本,从中抽取出具有特定关系的主体和客体。这里的关系是事先给出的关系之一。因此,训练数据的标注是一些 关系-主体-客体 的三元组,一段文本中可以有一个或多个三元组,属于一种级联任务。

注:样例来自 LIC 2019 信息抽取比赛样例数据
ERE 可分为两个子任务:实体抽取和关系抽取,如何更好处理这种类似的级联任务是NLP的一个热点研究方向。
二、实体关系联合抽取知识框架
实体关系联合抽取主要分 pipeline 方法和 end2end 方法:
pipeline 方法
思路:先命名实体识别( NER) , 在 关系抽取(RE)
问题:
忽略两任务间的相关性
误差传递。NER 的误差会影响 RE 的性能
end2end 方法
解决问题:实体识别、关系分类
思路:
实体识别
BIOES 方法:提升召回?和文中出现的关系相关的实体召回
嵌套实体识别方法:解决实体之间有嵌套关系问题
头尾指针方法:和关系分类强相关?和关系相关的实体召回
copyre方法
关系分类:
思路:判断 【实体识别】步骤所抽取出的实体对在句子中的关系
方法:
方法1:1. 先预测头实体,2. 再预测关系、尾实体
方法2:1. 根据预测的头、尾实体预测关系
方法3:1. 先找关系,再找实体 copyre
需要解决的问题:
关系重叠
(BarackObama, Governance, UnitedStates) 与 (BarackObama, PresidentOf, UnitedStates)
从示例可以看出,实体对(BarackObama,UnitedStates) 存在Governance 和PresidentOfPresidentOf两种关系,也就是关系重叠问题。
* 关系间的交互
(BarackObama, LiveIn, WhiteHouse) 和 (WhiteHouse, PresidentialPalace, UnitedStates) -> (BarackObama, PresidentOf, UnitedStates)
从示例可以看出,实体对(BarackObama,WhiteHouse) 和 实体对(WhiteHouse,UnitedStates) 存在中间实体WhiteHouse,而且通过(BarackObama, LiveIn, WhiteHouse) 和 (WhiteHouse, PresidentialPalace, UnitedStates) 能够推出 (BarackObama, PresidentOf, UnitedStates) 关系,也就是关系间存在交互问题。
三、论文介绍
【paper 1】Joint entity recognition and relation extraction as a multi-head selection problem
论文地址:http://arxiv.org/abs/1804.07847
一、论文动机
最早期的端到端实体关系联合抽取模型
二、论文思路
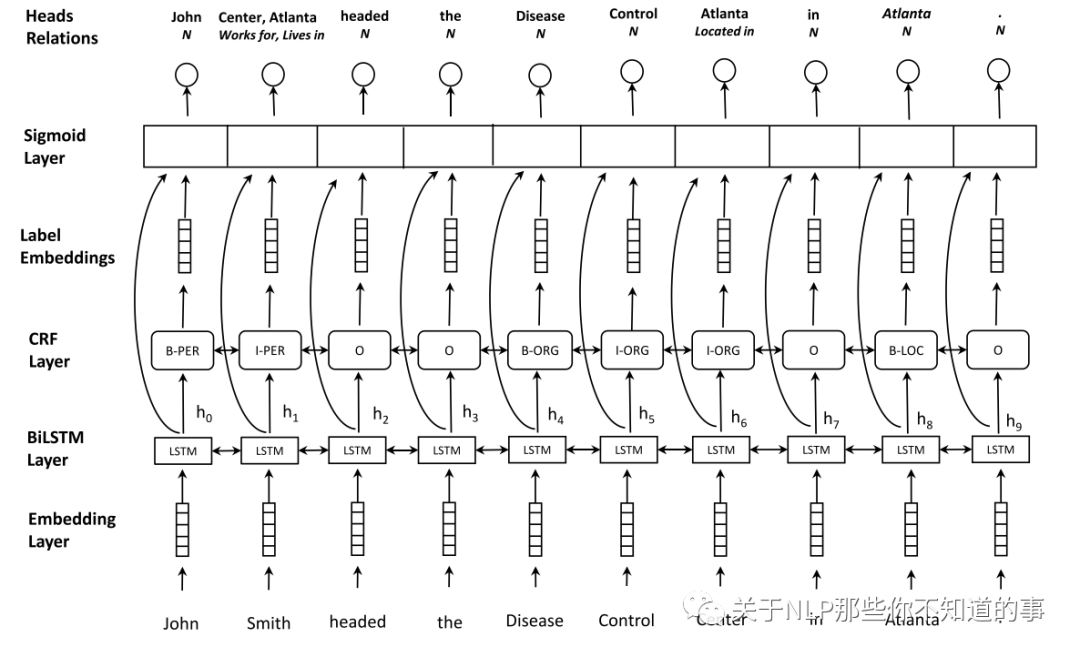
思路:将NER任务和关系分类任务一起做
提出方法
用BiLSTM+CRF识别出所有实体
对任意两个实体进行关系分类
损失函数

【paper 2】Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy[ACL2017]
论文地址:https://www.aclweb.org/anthology/P17-1113/
一、论文动机
如何解决抽取过程中大量冗余实体对;
如何利用实体对之间相互关系
二、论文思路
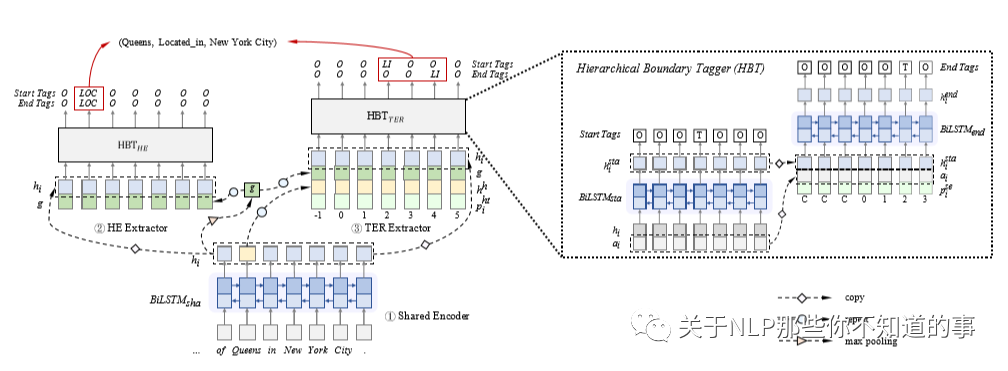
思想:先抽取头实体,再抽取尾实体和关系
步骤
Shared Encoder :字符级别和单词级别的特征抽取,这部分是共享的
HE Extractor :上面共享的特征进来以后,利用LSTM继续抽取特征,并做简单转化,见公式:
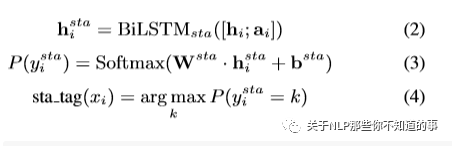
1. TER Extractor :将共享特征和抽取头实体获取的特征,输入进来,同样利用LSTM处理,过程同上,见公式:
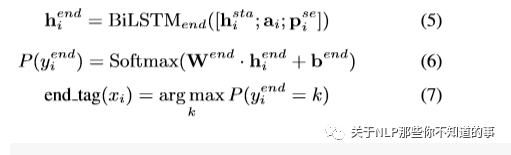
1. Training of Joint Extractor

1. 损失函数
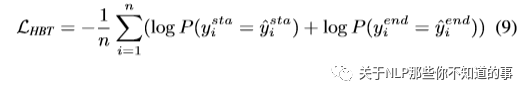
三、论文 trick
本论文的核心编程部分并不复杂,就是逐层写LSTM,后面的输入使用前面生成的特征。
技巧点就在于如何利用丰富的特征,这一点详见论文中对每一部分的输入的介绍。
【paper 3】GraphRel:Modeling Text as Relational Graphs for Joint Entity and Relation Extraction [ACL2019]
论文地址:https://www.aclweb.org/anthology/P19-1136.pdf 论文代码:tsujuifu/pytorch_graph-rel
一、论文动机
端到端的联合抽取实体及其关系
Pipeline:
思路:先 NER , 在 RE
问题:忽略两任务间的相关性
NN 模型:
思路:利用 CNN、LSTM 等深度学习网络进行实体关系联合抽取;
问题:非端到端联合抽取;
重叠关系的预测
考虑到关系间的交互,特别是重叠关系间的交互
二、论文思路
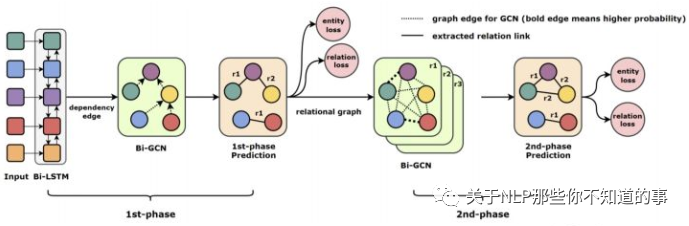
如上图,GraphRel 分为两个阶段:
第一阶段:
BiLSTM
将词向量和对应的词性标签向量作为原始输入,然后利用 Bi-LSTM 抽取 句子的顺序依赖特征。

1. Bi-GCN
对输入句子进行依存句法分析,构建依存树,并将其作为 输入句子的邻接矩阵,然后采用GCN 抽取局部依赖关系。
1. 实体和关系提取
1. 对于实体的抽取:采用 LSTM 输出每个词的类别,并得到 eloss1p;
2. 对于关系的抽取:预测每个单词对之间的关系。对于单词对(w1,w2),我们计算给定关系r的得分,然后对所有关系(包括non关系)做一个softmax,得到每种关系的概率,关系预测的loss为 rloss1p
第二阶段:
a. Relation-weight Graph
经过第一阶段的预测,我们构建了每种关系的关系加权图,图的节点是每个单词,边表示单词之间的关系概率。
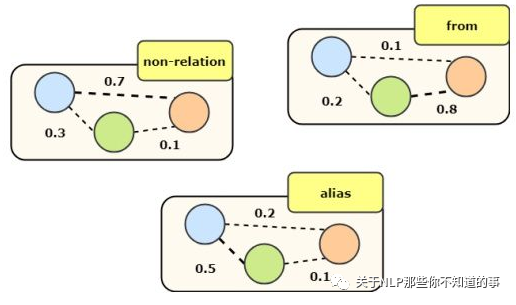
b. Relation-weight Graph
在每个关系图上采用bi-GCN,考虑不同关系的不同影响程度并聚合做为一个单词的综合特征。
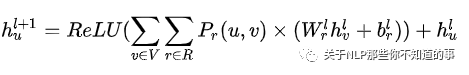
其中, Pr(u,v) 表示单词对(u,r)之间关系为r的概率。V表示所有单词,R表示所有关系。首先遍历所有单词,然后对每个单词v,u和v之间在每种关系下都存在一个概率,然后通过这个概率进行加权求和。这样的话,对于每一个单词,它都考虑到了所有单词在关系加权下的信息。第二阶段的GCN不同关系下的权重信息,对每个单词抽取了更丰富的特征。
得到新的单词特征后,接下来就是实体和关系的预测 ,并获得 eloss2p 和 rloss2p
三、论文 trick
因为关系抽取是对每个单词对都进行一个关系分类,所以对于由多个单词组成的实体对之间的关系预测就可能存在冲突,这里作者提出了三个方法:
head prediction:对于由多个单词组成的实体对,只取每个实体最后一个单词之间的关系作为这两个实体对之间的关系。
比如,实体关系三元组(Barack Obama, PresidentOf, United States)被正确识别出当且仅当Barack Obama和United States是实体,并且P(Obama,States)最大概率的关系为PresidentOf。其实这里称为tail prediction比较好,因为取的是实体的最后一个单词。
average prediction
拿上个例子来说,存在四个单词对(United, Barack)、(United, Obama)、(States, Barack)、(States, Obama),那么就有四个关系概率向量,对这四个关系概率向量求平均然后取概率最大的作为三元组的关系。
threshold prediction:与average不同,这里是对四个关系概率向量分别求概率最大的关系,然后统计每种关系的概率.
比如PresidentOf出现两次,LocatedIn、LivedIn分别出现一次,那么对应的概率为50%、25%、25%,然后取最大的概率50%是否大于θ来调整关系的输出。
四、论文 总结
学习特征
通过堆叠Bi-LSTM语句编码器和GCN(Kipf和Welling, 2017)依赖树编码器来自动学习特征
第一阶段的预测
GraphRel标记实体提及词,预测连接提及词的关系三元组
用关系权重的边建立一个新的全连接图(中间图)
指导:关系损失和实体损失
第二阶段的GCN
通过对这个中间图的操作
考虑实体之间的交互作用和可能重叠的关系
对每条边进行最终分类
在第二阶段,基于第一阶段预测的关系,我们为每个关系构建完整的关系图,并在每个图上应用GCN来整合每个关系的信息,进一步考虑实体与关系之间的相互作用。
五、个人观点
该方法只能解决关系重叠的一种情况,但是对于同一实体对具有多种关系无法解决;
该方法分别预测实体和关系,可能出现关系预测对,实体预测错情况;
构建了单词的关系图,而不是实体的关系图,后果就是预测多个单词的实体之间的关系时存在问题
【paper 4】CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning [AAAI2020]
论文地址:https://arxiv.org/abs/1911.10438?context=cs.lg 论文代码(torch复现):https://github.com/WindChimeRan/CopyMTL
一、论文动机
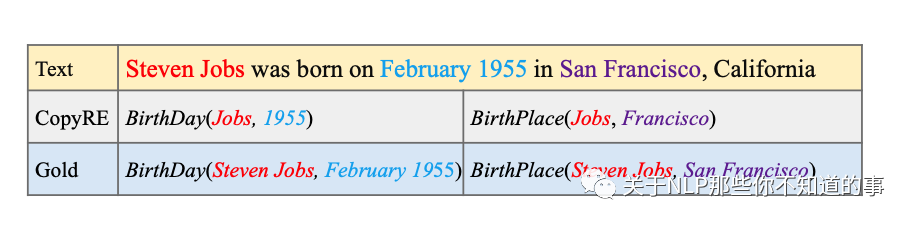
CopyMTL是在CopyRE基础上进行改进,CopyRE是一种基于 copying mechanism + seq2seq 结构的联合关系抽取模型,但存在以下两个缺点:
对头尾实体其实区分不大,基本上使用的是统一预测分布
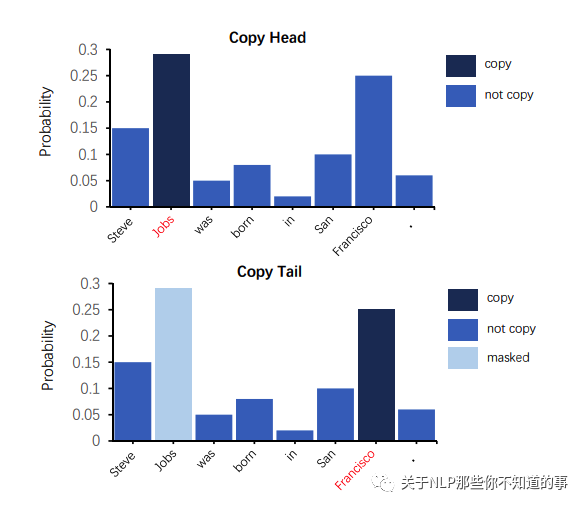
只能抽取单字,不能抽取成词的字
二、论文思路
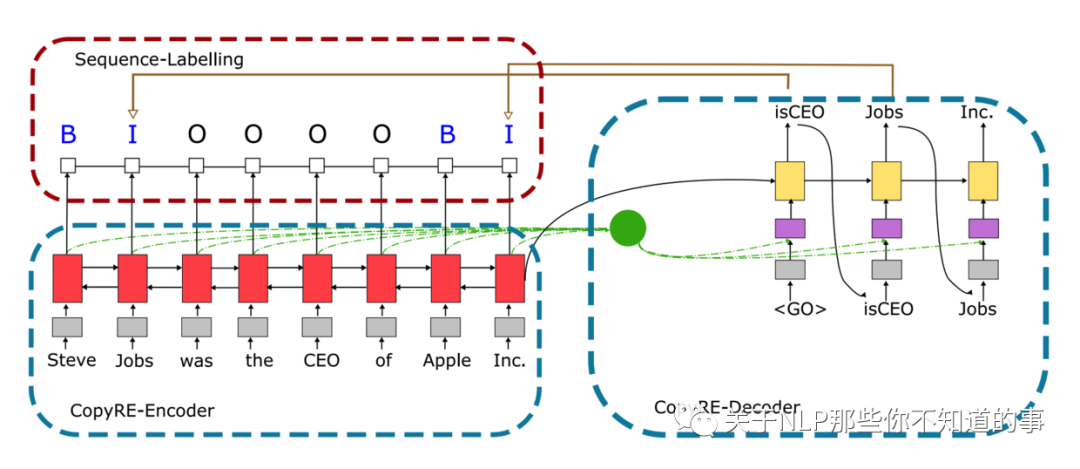
模型核心思路 (CopyRE类似)
Encoder:使用BiLSTM建模句子上下文信息
结合copying mechanism生成多对三元组
同时,针对CopyRE只能抽取单字,不能抽取成词的字的问题,引入命名实体任务进行多任务学习。
模型结构
Encoder
使用BiLSTM建模上下文信息

2. Decoder
解码部分使用Attention + LSTM去建模
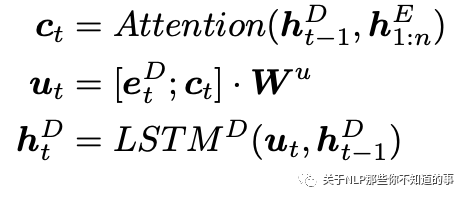
3. 使用一个全连接层获取输出
三、论文 trick
与常规的seq2seq不同,CopyMTL需要获取的是三元组,所以对于头实体、关系和尾实体需要采用不同的策略:
对于关系预测
由于对于三元组的解码从关系开始,所以先做关系预测,同时加入NA表示没有关系。
头实体预测
预测文中哪一个实体最可能是当前关系下的头实体
尾实体预测
在CopyRE中,需要加入隐码矩阵
但CopyMTL认为这主要是由于预测实体时使用的方式不当:
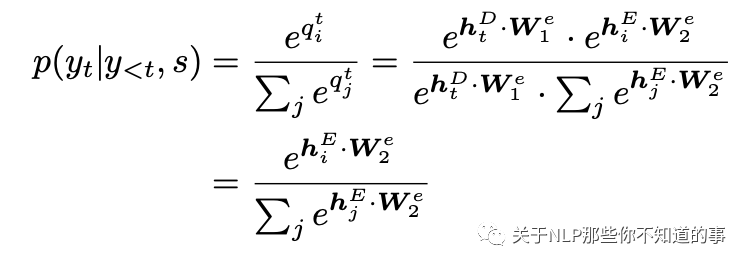
因此在CopyMTL中更改了预测方式,使用如下公式进行预测:
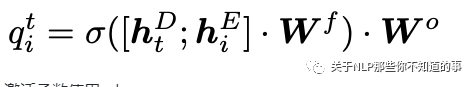
激活函数使用selu
Sequence Labeling
对于CopyRE只能预测单字的问题,CopyMTL加入了一个命名实体任务:
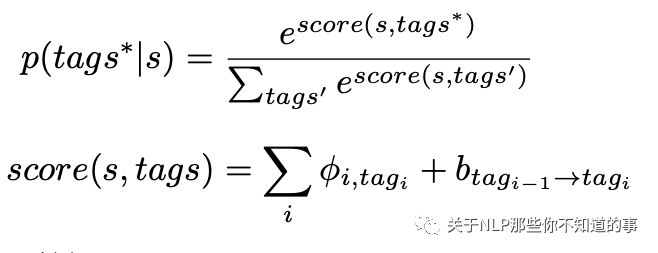
多任务
将seq2seq和Sequence Labeling 的损失加权融合
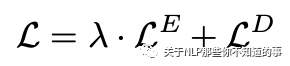
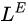 是命名实体的损失:
是命名实体的损失:
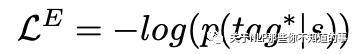
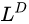 是seq2seq的损失:
是seq2seq的损失:
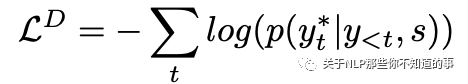
【paper 5】Span-based Joint Entity and Relation Extraction with Transformer Pre-training [ECAI 2020]
论文地址:https://arxiv.org/abs/1909.07755
一、论文动机
如何利用Transformer来解决联合关系抽取问题
二、论文思路
思路
利用预训练的BERT模型作为其核心部分;BERT部分对于一个句子仅仅需要前向执行一次;
抛弃了传统的BIO/BILOU标注实体的方式,构建了一个基于跨度的联合实体识别和关系抽取模型。
具体方法
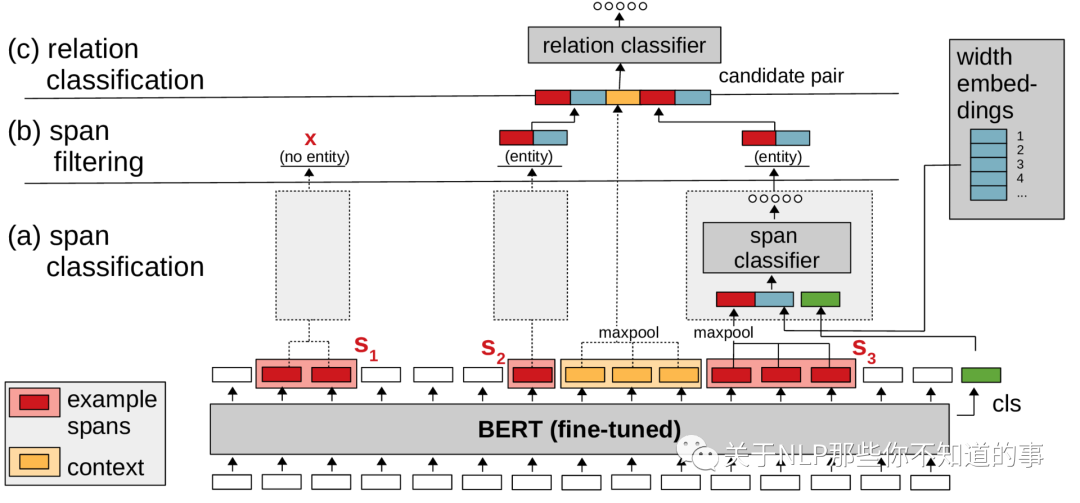
输入:byte-pair encoded (BPE) tokens(和BERT的输入一致)
Span Classification:本质是一个多分类模型(分类类别实体类型:person, organization, none等)
输入:word embedding(实体包括的词向量进行max-pooling操作), width embedding(实体包含的词个数在width向量矩阵中找到的width向量), cls embedding(BERT的cls向量)
输出:实体类别
Span Filtering:预先过滤span size超过10的实体
关系分类:本质也是一个多分类模型
输入:word embedding1(实体1), width embedding1(实体1), context embedding(实体1和实体2中间的词向量进行max-pooling操作), word embedding2(实体2), width embedding2(实体2)
输出:关系类别
损失函数
实体分类损失 + 关系分类损失
三、论文 trick
负采样
实体负采样:在所有可能的实体中最多随机选取 N 个实体,并将未在训练集中被标注为正例的样本标记成负例,同时规定实体的长度不能超过10。
关系负采样:针对所有待预测的实体之间的关系,对于出现过的所有实体任意两两组合构建关系,对于在正样本中未出现的标注为负样本,并且最多选取 M 个负样本。
【paper 6】A Novel Cascade Binary Tagging Framework for Relational Triple Extraction[ACL2020]
论文地址:https://arxiv.org/abs/1909.03227 论文代码(keras):https://github.com/weizhepei/CasRel 论文代码(torch复现):https://github.com/powerycy/Lic2020-
一、论文动机
目前一个句子仅包含一个关系三元组进行关系三元组抽取已经能够达到不错的效果。但在一个句子中包含多个关系三元组,尤其当多个三元组有重叠的情况时,模型表现的效果不尽人意。
二、论文思路
模型着重解决了一对多的问题,利用概率图的思想:首先预测第一个实体s,预测出s过后传入s来预测s对应的p跟o,公式如下:
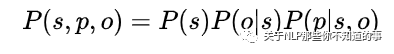
思路
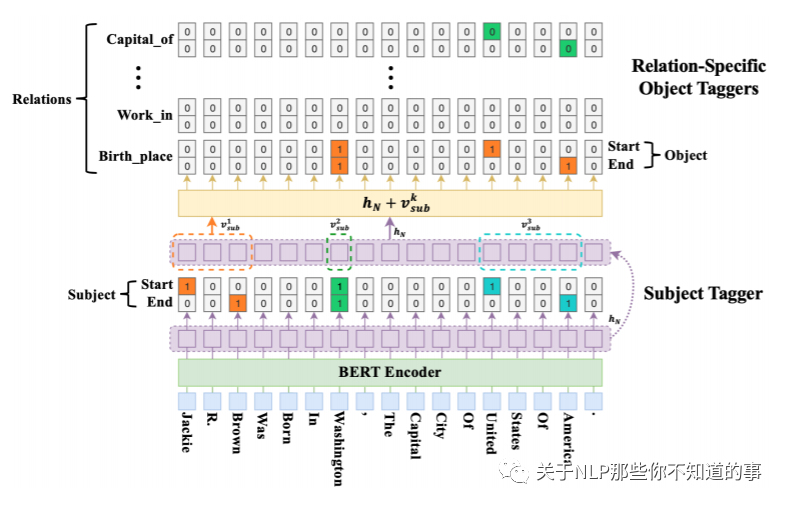
1. 把训练中的句子利用BERT进行切分得到相应的编码

2. 指出句子中subject与object的位置的起始位置与终止位置

3. 随机选择一个subject的起始与终止为止。(这样做的理由是增加了训练集中的负样本数量)

4. 把相应的输入送入的BERT模型得到最后一层的隐藏状态

5. 对隐藏状态进行sigmoid分类,得到subject的开始位置与结束位置

6. 得到subject的开始与结束位置之后,在取出倒数第二层的隐状态,利用输入的subject_id取出隐状态中的首尾向量

7. 得到相应的向量过后对向量进行简单的相加求平均,并通过Conditional Layer Normalization。


8. 得到相加过后的向量通过sigmoid对所有的关系进行二分类

这里是将句子的token_ids,segment_ids和attention_mask_ids传入RoBERTa,RoBERTa对每个token做embedding,通过Linear层与sigmoid函数,得到每个字是subject起始位置和终止位置的概率,然后通过RoBERTa的隐层输出,利用subject_id找到对应得向量取出来,通过这两个向量相加,过一层sigmoid函数得到object的起始位置和终止位置的概率,在subject确定的情况下,在得到相应的object后predicate也就确定了下来。
9. 损失函数中的mask

mask函数可以句子在padding过后只采用有效的部分从而避免计算的时候因为0的添加导致计算错误。
【paper 7】END-TO-END NAMED ENTITY RECOGNITION AND RELATION EXTRACTION USING PRE-TRAINED LANGUAGE MODELS
论文地址:https://arxiv.org/abs/1912.13415
一、论文动机
Pipline的方式存在误差传播
Jiont 方式需要使用额外的NLP工具
二、论文思路
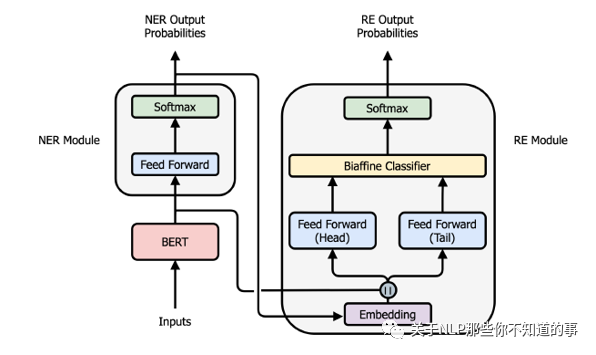
使用bert 提取embedding,然后使用FFNN进行NER任务
得到的NER的vector拼接bert embedding 进行关系分类任务
三**、**论文trick
通过构造NRE和RE的loss权重,引入entity pre-train
使用E-和S-的标记传入RE模型,进行关系分类
在关系分类中引入Head 和 Tail 模块。
参考
Joint entity recognition and relation extraction as a multi-head selection problem
Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy【ACL 2017】
GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction【ACL 2019】
[CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning 【AAAI2020】(https://arxiv.org/abs/1911.10438)
Span-based Joint Entity and Relation Extraction with Transformer Pre-training 【ECAI 2020】
[A Novel Cascade Binary Tagging Framework for Relational Triple Extraction 【ACL2020】(https://arxiv.org/abs/1909.03227)
END-TO-END NAMED ENTITY RECOGNITION AND RELATION EXTRACTION USING PRE-TRAINED LANGUAGE MODELS
