
英伟达StyleGAN团队新作:分析脸部纹理
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
杨净 发自 凹非寺 量子位 报道 | 公众号 QbitAI
换脸的GAN,还能有啥突破?
要不,分析个脸部纹理试试。

不得不说,真有点科幻电影的赶脚~
这是英伟达最新推出GAN——Alias-Free GAN,号称更适合图片和视频生成。
尤其是他们之前推出的StyleGAN2相比。

在很多细节上, 比如头发、皱纹的转换、移动都更加顺滑。

我仔细看了看,确实如此。
以前的StyleGAN2,就像是某些固定的点粘在屏幕上,然后脸在屏幕下面移动。
而最新的GAN,则是所有细节全都一起移动。

对此,有网友表示,
StyleGAN2出来后,不知道在此基础上还能有啥突破。
结果现在一对比,StyleGAN2更像是拙劣的视频游戏特效。

论文详情
一个典型的GAN是这样处理脸部细节的。
首先提取一些粗糙、低分辨率的特征,通过上采样层分层细化。随后经过卷积层进行局部混合,并经由非线性映射层引入新的细节。
呈现出来的效果就像是,移动头部导致了鼻子的移动,而鼻子又会移动周围的皮肤毛孔。

△StyleGAN2
但这些细节特征有很强的位置偏好。
也就是说,这些细节特征每移动到一个位置,都会在那里停留很久,才移去下一个位置。
依然给人一种不太自然的感觉~
就好比是某个毛孔被固定住了,其他细节绕着它原地摩擦~
用他们的话来说,就是纹理粘连(texture sticking)。
比如StyleGAN2生成的毛发,大多坚持在相同的坐标上,形成了水平的条纹。

本次则主要针对两种类型的移动——平移和旋转,Alias-Free-T和Alias-Free-R。
传统的GAN网络结构,包括卷积、上采样、下采样和非线性这几个方面,而Alias-Free GAN整架构,是在StyleGAN2基础上调整的。

大致是这样一个调整过程。
首先,为了便于对输入的图像进行连续的平移和转化,他们用傅里叶特征取代StyleGAN2中的输入常数。接着,删除了每个像素中的噪声输入,因为它们与特征转换无关。
此外,他们还降低了映射网络的深度,并禁用了混合正则化和路径长度正则化。最后取消了输出跳过连接。
在实践中,还对卷积权重进行了划分。各层遵循严格的2×上采样时间表,在每个分辨率下执行两层,使得上采样后特征图的数量减半。
结果表明,与StyleGAN2相比,Alias-Free GAN在FID分数上表现的更好。
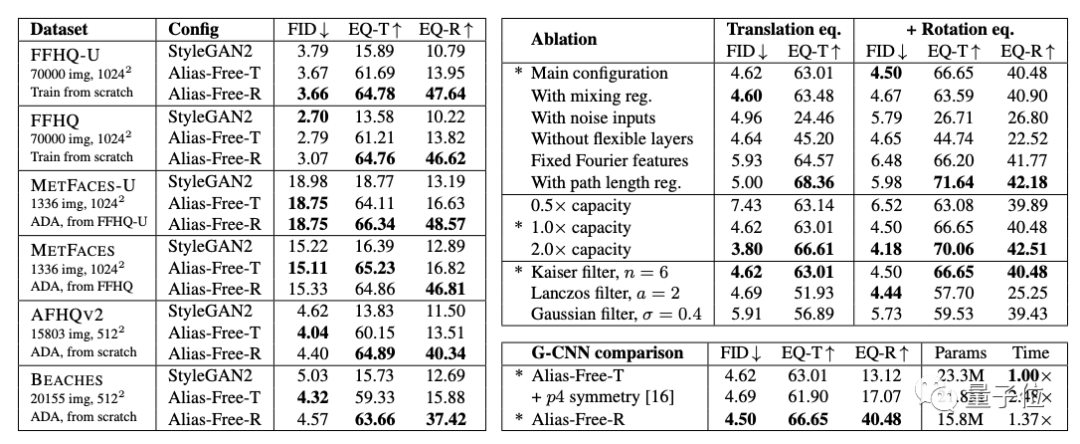
(FID 用于评估GAN生成图像的质量,分数越低说明图像质量越高)

英伟达出品

一作Tero Karras,可能熟悉StyleGAN系列的看出来了。
这位也是StyleGAN系列的主要开发者。

目前Alias-Free GAN还未开源,GitHub上还没有任何内容。
研究人员表示,预计9月开源。
论文链接:
https://nvlabs-fi-cdn.nvidia.com/alias-free-gan/alias-free-gan-paper.pdf
参考链接:
[1]https://news.ycombinator.com/item?id=27606347
[2]https://nvlabs.github.io/alias-free-gan/
[3]https://github.com/NVlabs/alias-free-gan
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!