
实战:基于 CNN 的验证码破解项目(附代码)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|视觉算法


♚
在我们的实际生活中有很多的场景需要输入验证码,在工程实践中为了将数据采集、模拟登录等一系列操作行为自动化处理就需要处理好验证码的识别工作,已有的工作中基于机器学习和深度学习都有很多的工作开展出来,效果也都不错,今天本文的主要内容就是基于卷积神经网络CNN模型来构建验证码图片识别模型。
整体流程示意图如下图所示:
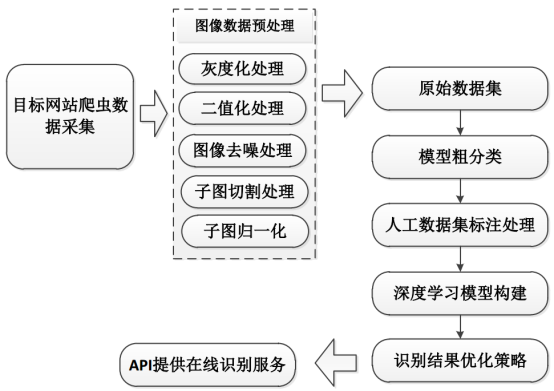
其中,主要的工作分为三个部分:数据采集、数据预处理和模型构建与测试。上述是之前一个实际完成的项目流程示意图,本文主要是实践基于CNN来构建识别模型,对于数据采集和预处理部分不作为讲解的内容,感兴趣可以亲身实践一下,都是图像处理领域内的比较基础的内容。
经过处理后我们将原始的验证码图片均进行了基本的去噪、二值化以及归一化等处理得到了可用于模型直接训练使用的特征向量数据,原始的验证码图像数据如下所示:
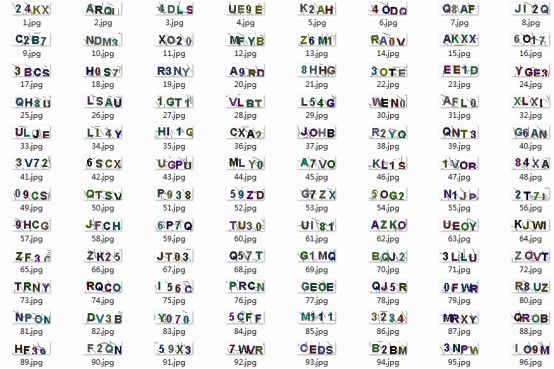
处理后生成的特征向量文件如下所示:
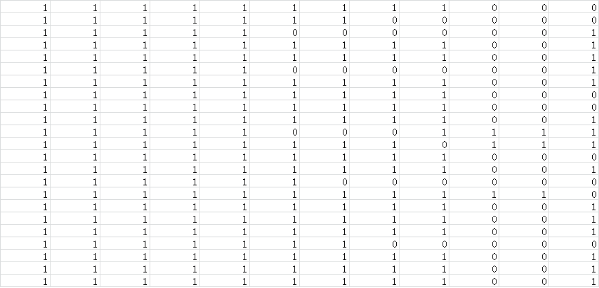
上图中,每一行表示一个字符子图,每一列表示字符子图的一维数据,向量的维数就是经过归一化处理后的字符子图【宽x高】的值,即:将二维的矩阵数据转化为了一维的向量数据,这一步不是必须的,只是我这里采用了这种处理方式。
生成得到原始验证码图片数据的特征向量后就可以搭建训练模型了,具体的代码实现如下所示:
keys = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F','G','H','J','K','L','N','P','Q','R','S','T','U','V','X','Y','Z']
def trainModel(feature='data.csv',batch_size=128,nepochs=50,ES=False,n_classes=31,model_path='vcModel.h5'):
'''
模型训练
'''
df = pd.read_csv(feature)
vals = range(31)
label_dict = dict(zip(keys, vals))
x_data = df[['v'+str(i+1) for i in range(320)]]
y_data = pd.DataFrame({'label':df['label']})
y_data['class'] = y_data['label'].apply(lambda x: label_dict[x])
#数据集划分
X_train, X_test, Y_train, Y_test = train_test_split(x_data, y_data['class'], test_size=0.3, random_state=42)
x_train = np.array(X_train).reshape((1167, 20, 16, 1))
x_test = np.array(X_test).reshape((501, 20, 16, 1))
# label编码处理
y_train = np_utils.to_categorical(Y_train, n_classes)
y_val = np_utils.to_categorical(Y_test, n_classes)
input_shape = x_train[0].shape
#CNN模型搭建开始 【可以根据自己的实际情况进行增删和调整】
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), input_shape=input_shape, padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(0.4))
model.add(Conv2D(64, kernel_size=(3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(0.4))
model.add(Conv2D(128, kernel_size=(3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dense(n_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
plot_model(model, to_file='vcModel.png', show_shapes=True)
if ES:
callbacks = [EarlyStopping(monitor='val_acc', patience=10, verbose=1)] #提前终止策略
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=nepochs, \
verbose=1, validation_data=(x_test, y_val), callbacks=callbacks)
else:
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=nepochs, verbose=1, validation_data=(x_test, y_val))
model.save(model_path)
#模型准确度、损失函数曲线绘制
plt.clf()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend(['train','test'], loc='upper left')
plt.savefig('train_validation_acc.png')
plt.clf()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig('train_validation_loss.png')
if __name__=='__main__':
trainModel(feature='data.csv',batch_size=128,nepochs=100,ES=False,n_classes=31,model_path='vcModel.h5')
默认设置了100次的迭代,不开启提前终止策略,训练完成后截图如下所示:

训练完成后就得到了离线的识别模型文件,可重复加载使用,我们在训练结束后绘制了模型的准确度和损失值对比曲线,如下所示:


从准确度和损失值对比曲线综合来看可以发现:模型在20次迭代计算后就趋近于平稳,之后保持一个比较稳定的状态。
之后对模型的识别能力进行测试分析,测试代码实现如下:
def predict(pic_path,pdir='test_verifycode/chars/',saveDir='test_verifycode/predict/'):
'''
预测识别
'''
pic_list = os.listdir(pdir)
if pic_list:
for File in pic_list:
os.remove(pdir+ File)
splitImage(pic_path)
pic_list = os.listdir(pdir)
if pic_list:
for File in pic_list:
remove_edge_picture(pdir+ File)
for File in os.listdir(pdir):
resplit(pdir+ File)
for File in os.listdir(pdir):
picConvert(pdir, File)
pic_list = sorted(os.listdir(pdir), key=lambda x: x[0])
table = np.array([loadImage(pdir, File) for File in pic_list]).reshape(-1,20,16,1)
cnn = load_model('vcModel.h5')
y_pred = cnn.predict(table)
predictions = np.argmax(y_pred, axis=1)
keys = range(31)
vals = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'X', 'Y', 'Z']
label_dict = dict(zip(keys, vals))
predict_label=''.join([label_dict[pred] for pred in predictions])
moveFile(pdir,saveDir+predict_label+'/')
return predict_label
def mainFunc(picDir='VerifyCode/'):
'''
主模块
'''
count=0
pic_list=os.listdir(picDir)
total=len(pic_list)
for one_pic in pic_list:
true_label=one_pic.split('.')[0].strip()
one_pic_path=picDir+one_pic
predict_label=predict(one_pic_path)
print('True Label: {0}, Predict Label: {1}.'.format(true_label,predict_label))
if true_label==predict_label:
count+=1
print('Accuracy: ',count/total)
测试结果截图如下所示:
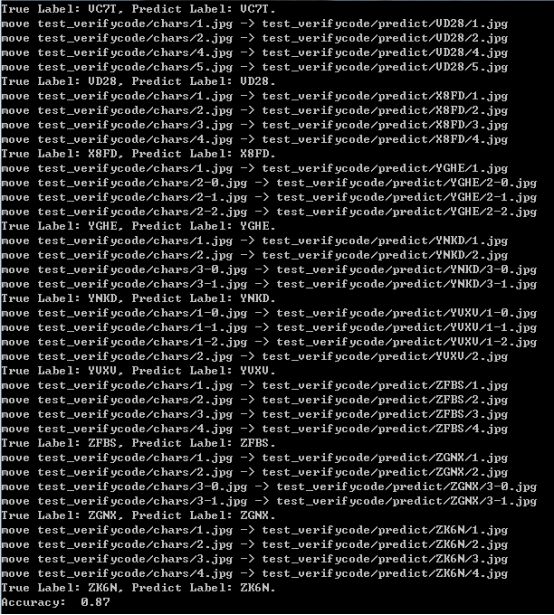
使用了200张的验证码测试集来测试模型的识别能力,最终的准确度为87%,感觉还是不错的,毕竟我只使用了不到2000的训练数据来训练CNN模型。
如果有数据集需求的可以联系我,或者是去随机生成一些验证码数据集也是可以的,一个简单的验证码数据集生成流程如下所示:
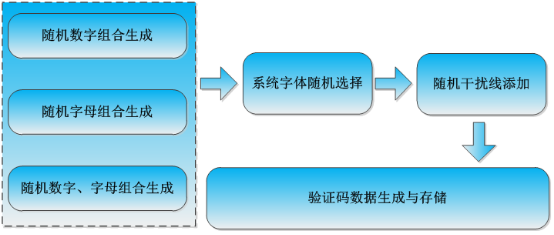
到这里本文的工作就结束了,很高兴在自己温习回顾知识的同时能写下点分享的东西出来,如果说您觉得我的内容还可以或者是对您有所启发、帮助,还希望得到您的鼓励支持,谢谢!
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~