
Linux 直接I/O 原理与实现
缓存I/O
一般来说,当调用 open() 系统调用打开文件时,如果不指定 O_DIRECT 标志,那么就是使用缓存I/O来对文件进行读写操作。我们先来看看 open() 系统调用的定义:
int open(const char *pathname, int flags, ... /*, mode_t mode */ );下面说明一下各个参数的作用:
pathname:指定要打开的文件路径。flags:指定打开文件的标志。mode:可选,指定打开文件的权限。
其中 flags 参数可选值如下表:
| 标志 | 说明 |
|---|---|
| O_RDONLY | 以只读的方式打开文件 |
| O_WRONLY | 以只写的方式打开文件 |
| O_RDWR | 以读写的方式打开文件 |
| O_CREAT | 若文件不存在,则创建该文件 |
| O_EXCL | 以独占模式打开文件;若同时设置 O_EXCL 和 O_CREATE, 那么若文件已经存在,则打开操作会失败 |
| O_NOCTTY | 若设置该描述符,则该文件不可以被当成终端处理 |
| O_TRUNC | 截断文件,若文件存在,则删除该文件 |
| O_APPEND | 若设置了该描述符,则在写文件之前,文件指针会被设置到文件的底部 |
| O_NONBLOCK | 以非阻塞的方式打开文件 |
| O_NELAY | 同 O_NELAY,若同时设置 O_NELAY 和 O_NONBLOCK,O_NONBLOCK 优先起作用 |
| FASYNC | 若设置该描述符,则 I/O 事件通知是通过信号发出的 |
| O_SYNC | 该描述符会对普通文件的写操作产生影响,若设置了该描述符,则对该文件的写操作会等到数据被写到磁盘上才算结束 |
| O_DIRECT | 该描述符提供对直接 I/O 的支持 |
| O_LARGEFILE | 该描述符提供对超过 2GB 大文件的支持 |
| O_DIRECTORY | 该描述符表明所打开的文件必须是目录,否则打开操作失败 |
| O_NOFOLLOW | 若设置该描述符,则不解析路径名尾部的符号链接 |
flags 参数用于指定打开文件的标志,比如指定 O_RDONLY,那么就只能以只读方式对文件进行读写。这些标志都能通过 位或 (|) 操作来设置多个标志如:
open("/path/to/file", O_RDONLY|O_APPEND|O_DIRECT);但 O_RDONLY、O_WRONLY 和 O_RDWR 这三个标志是互斥的,也就是说这三个标志不能同时设置,只能设置其中一个。
当打开文件不指定 O_DIRECT 标志时,那么就默认使用 缓存I/O 方式打开。我们可以通过下图来了解 缓存I/O 处于文件系统的什么位置:
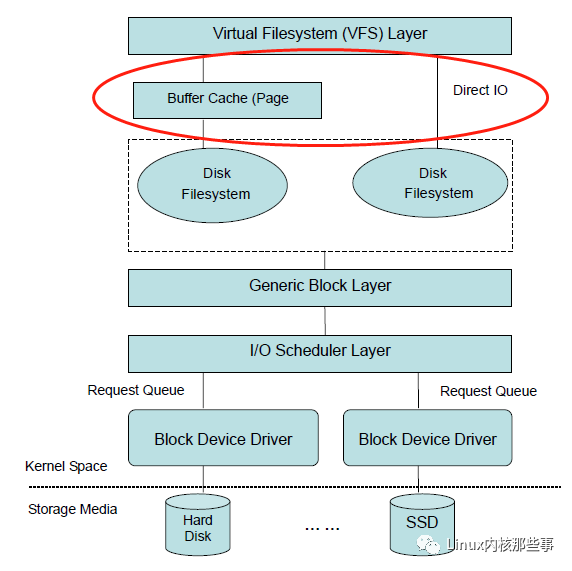
上图中红色框部分就是 缓存I/O 所在位置,位于 虚拟文件系统 与 真实文件系统 中间。
也就是说,当虚拟文件系统读文件时,首先从缓存中查找要读取的文件内容是否存在缓存中,如果存在就直接从缓存中读取。对文件进行写操作时也一样,首先写入到缓存中,然后由操作系统同步到块设备(如磁盘)中。
缓存I/O 的优缺点
缓存I/O 的引入是为了减少对块设备的 I/O 操作,但是由于读写操作都先要经过缓存,然后再从缓存复制到用户空间,所以多了一次内存复制操作。如下图所示:
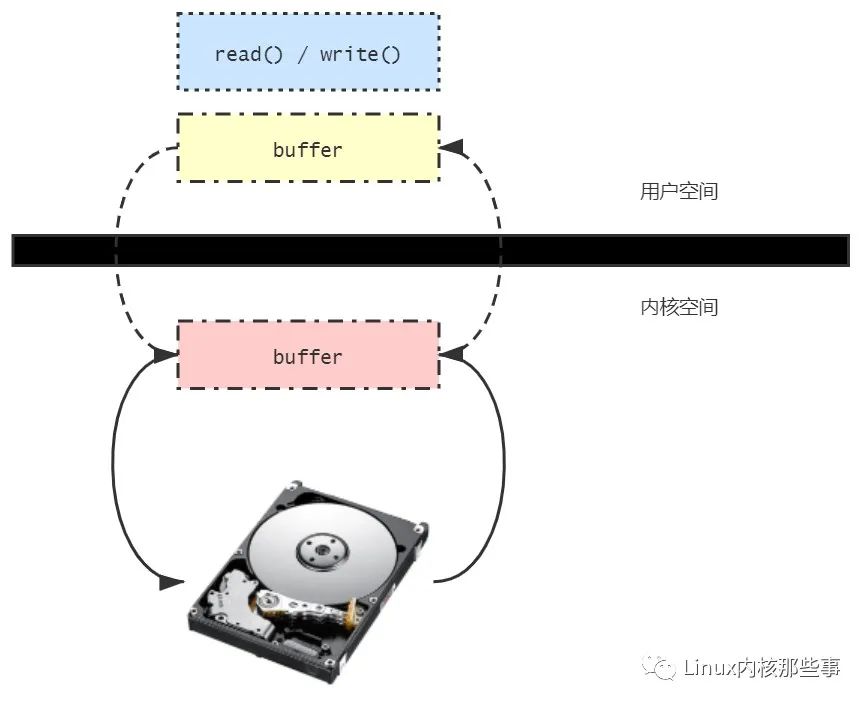
所以 缓存I/O 的优点是减少对块设备的 I/O 操作,而缺点就是需要多一次的内存复制。另外,有些应用程序需要自己管理 I/O 缓存的(如数据库系统),那么就需要使用 直接I/O 了。
直接I/O
直接I/O 就是对用户进行的 I/O 操作直接与块设备进行交互,而不进行缓存。
直接I/O的优点是:由于不对 I/O 数据块进行缓存,所以可以直接跟用户数据进行交互,减少一次内存的拷贝。直接I/O的缺点是:每次 I/O 操作都直接与块设备进行交互,增加了对块设备的读写操作。
但由于应用程序可以自行对数据块进行缓存,所以更加灵活,适合一些对 I/O 操作比较敏感的应用,如数据库系统。
直接I/O 实现
当调用 open() 系统调用时,在 flags 参数指定 O_DIRECT 标志即可使用 直接I/O。我们从 虚拟文件系统 开始跟踪 Linux 对 直接I/O 的处理过程。
当调用 open() 系统调用时,会触发调用 sys_open() 系统调用,我们先来看看 sys_open() 函数的实现:
asmlinkage long sys_open(const char *filename, int flags, int mode){char *tmp;int fd, error;...tmp = getname(filename); // 把文件名从用户空间拷贝到内核空间fd = PTR_ERR(tmp);if (!IS_ERR(tmp)) {fd = get_unused_fd(); // 申请一个还没有使用的文件描述符if (fd >= 0) {// 根据文件路径打开文件, 并获取文件对象struct file *f = filp_open(tmp, flags, mode);error = PTR_ERR(f);if (IS_ERR(f))goto out_error;fd_install(fd, f); // 把文件对象与文件描述符关联起来}out:putname(tmp);}return fd;...}
打开文件的整个流程比较复杂,但对我们分析 直接I/O 并没有太大关系,之前在虚拟文件系统一章已经分析过,这里就不再重复了,可以参考之前的文章:虚拟文件系统
我们主要关注的是,sys_open() 函数最后会调用 dentry_open() 把 flags 参数保存到文件对象的 f_flags 字段中,调用链:sys_open() -> filp_open() -> dentry_open():
struct file *dentry_open(struct dentry *dentry, struct vfsmount *mnt, int flags){struct file *f;...f = get_empty_filp();f->f_flags = flags;...}
也就是说,sys_open() 函数会打开文件,然后把 flags 参数保存到文件对象的 f_flgas 字段中。接下来,我们分析一下读文件操作时,是怎么对 直接I/O 进行处理的。读文件操作使用 read() 系统调用,而 read() 最终会调用内核的 sys_read() 函数,代码如下:
asmlinkage ssize_t sys_read(unsigned int fd, char *buf, size_t count){ssize_t ret;struct file *file;file = fget(fd);if (file) {...if (!ret) {ssize_t (*read)(struct file *, char *, size_t, loff_t *);ret = -EINVAL;// ext2文件系统对应的是: generic_file_read() 函数if (file->f_op && (read = file->f_op->read) != NULL)ret = read(file, buf, count, &file->f_pos);}...}return ret;}
由于 sys_read() 函数属于虚拟文件系统范畴,所以其最终会调用真实文件系统的 file->f_op->read() 函数,ext2文件系统 对应的是 generic_file_read() 函数,我们来分析下 generic_file_read() 函数:
ssize_t generic_file_read(struct file *filp, char * buf, size_t count, loff_t *ppos){ssize_t retval;...if (filp->f_flags & O_DIRECT) // 如果标记了使用直接IOgoto o_direct;...o_direct:{loff_t pos = *ppos, size;struct address_space *mapping = filp->f_dentry->d_inode->i_mapping;struct inode *inode = mapping->host;...size = inode->i_size;if (pos < size) {if (pos + count > size)count = size - pos;retval = generic_file_direct_IO(READ, filp, buf, count, pos);if (retval > 0)*ppos = pos + retval;}UPDATE_ATIME(filp->f_dentry->d_inode);goto out;}}
从上面代码可以看出,如果在调用 open() 时指定了 O_DIRECT 标志,那么 generic_file_read() 函数就会调用 generic_file_direct_IO() 函数对 I/O 操作进行处理。由于 generic_file_direct_IO() 函数的实现曲折迂回,所以下面主要分析重要部分:
static ssize_t generic_file_direct_IO(int rw, struct file *filp, char *buf, size_t count, loff_t offset){...while (count > 0) {iosize = count;if (iosize > chunk_size)iosize = chunk_size;// 为用户虚拟内存空间申请物理内存页retval = map_user_kiobuf(rw, iobuf, (unsigned long)buf, iosize);if (retval)break;// ext2 文件系统对应 ext2_direct_IO() 函数,// 而 ext2_direct_IO() 函数直接调用了 generic_direct_IO() 函数retval = mapping->a_ops->direct_IO(rw, inode, iobuf, (offset+progress) >> blocksize_bits, blocksize);...}...}
generic_file_direct_IO() 函数主要的处理有两部分:
调用
map_user_kiobuf()函数为用户虚拟内存空间申请物理内存页。调用真实文件系统的
direct_IO()接口对直接I/O进行处理。
map_user_kiobuf() 函数属于内存管理部分,可以参考之前的 内存管理 相关的文章进行分析,这里就不重复了。
generic_file_direct_IO() 函数最终会调用真实文件系统的 direct_IO() 接口,对于 ext2文件系统,direct_IO() 接口对应的是 ext2_direct_IO() 函数,而 ext2_direct_IO() 函数只是简单的封装了 generic_direct_IO() 函数,所以我们来分析下 generic_direct_IO() 函数的实现:
int generic_direct_IO(int rw, struct inode *inode, struct kiobuf *iobuf,unsigned long blocknr, int blocksize, get_block_t *get_block){int i, nr_blocks, retval;unsigned long *blocks = iobuf->blocks;nr_blocks = iobuf->length / blocksize;// 获取要读取的数据块号列表for (i = 0; i < nr_blocks; i++, blocknr++) {struct buffer_head bh;bh.b_state = 0;bh.b_dev = inode->i_dev;bh.b_size = blocksize;retval = get_block(inode, blocknr, &bh, rw == READ ? 0 : 1);...blocks[i] = bh.b_blocknr;}// 开始进行I/O操作retval = brw_kiovec(rw, 1, &iobuf, inode->i_dev, iobuf->blocks, blocksize);out:return retval;}
generic_direct_IO() 函数的逻辑也比较简单,首先调用 get_block() 获取要读取的数据块号列表,然后调用 brw_kiovec() 函数进行 I/O 操作。所以 brw_kiovec() 函数才是 I/O 操作的最终触发点。我们继续分析:
int brw_kiovec(int rw, int nr, struct kiobuf *iovec[],kdev_t dev, unsigned long b[], int size){...for (i = 0; i < nr; i++) {...for (pageind = 0; pageind < iobuf->nr_pages; pageind++) {map = iobuf->maplist[pageind];...while (length > 0) {blocknr = b[bufind++];...tmp = bhs[bhind++];tmp->b_size = size;set_bh_page(tmp, map, offset); // 设置保存I/O操作后的数据的内存地址 (用户空间的内存)tmp->b_this_page = tmp;init_buffer(tmp, end_buffer_io_kiobuf, iobuf); // 设置完成I/O后的收尾工作回调函数为: end_buffer_io_kiobuf()tmp->b_dev = dev;tmp->b_blocknr = blocknr;tmp->b_state = (1 << BH_Mapped) | (1 << BH_Lock) | (1 << BH_Req);...submit_bh(rw, tmp); // 提交 I/O 操作 (通用块I/O层)if (bhind >= KIO_MAX_SECTORS) {kiobuf_wait_for_io(iobuf);err = wait_kio(rw, bhind, bhs, size);...}skip_block:length -= size;offset += size;if (offset >= PAGE_SIZE) {offset = 0;break;}} /* End of block loop */} /* End of page loop */} /* End of iovec loop */...return err;}
brw_kiovec() 函数主要完成 3 个工作:
设置用于保存 I/O 操作后的数据的内存地址 (用户申请的内存)。
设置 I/O 操作完成后的收尾回调函数为: end_buffer_io_kiobuf()。
提交 I/O 操作到通用块层。
可以看出,对于 I/O 操作后的数据会直接保存到用户空间的内存,而没有通过内核缓存作为中转,从而达到 直接I/O 的目的。