
不管卷不卷,跳槽时还得问问你G1原理!

源 / 文/
所有的垃圾回收器的目的都是朝着减少STW的目的而前进,G1(Garbage First)回收器的出现颠覆了之前版本CMS、Parallel等垃圾回收器的分代收集方式,从2004年Sun发布第一篇关于G1的论文后,直到2012年JDK7发布更新版本,花了将近10年的时间G1才达到商用的程度,而到JDK9发布之后,G1成为了默认的垃圾回收器,CMS也变相地相当于被淘汰了。
G1结构
自由分区Free Region 年轻代分区Young Region,年轻代还是会存在Eden和Survivor的区分 老年代分区Old Region 大对象分区Humongous Region
-XX:G1HeapRegionSize来设置,大小为1~32MB,默认最多可以有2048个Region,那么按照默认值计算G1能管理的最大内存就是32MB*2048=64G。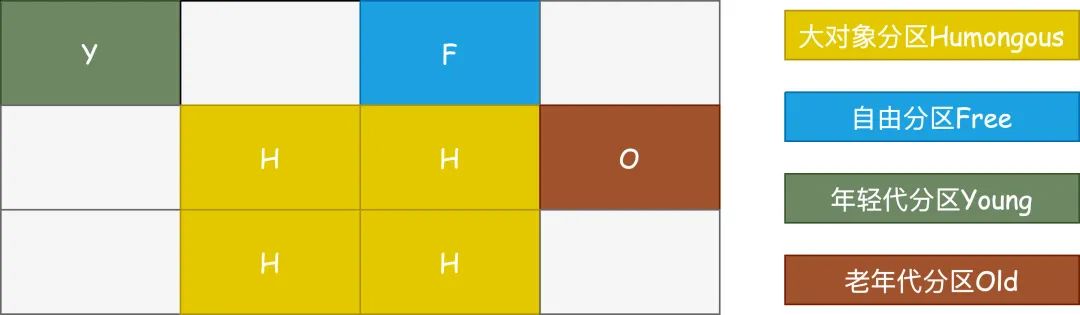
G1优势
-XX:MaxGCPauseMillis来设置允许的停顿时间(默认200ms),G1会收集每个Region的回收之后的空间大小、回收需要的时间,根据评估得到的价值,在后台维护一个优先级列表,然后基于我们设置的停顿时间优先回收价值收益最大的Region。hotspot/src/share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
double get_new_prediction(TruncatedSeq* seq) {
return MAX2(seq->davg() + sigma() * seq->dsd(),
seq->davg() * confidence_factor(seq->num()));
}
davg表示衰减值sigma表示一个系数,代表信贷度,默认值为0.5dsd表示衰减标准偏差confidence_factor表示可信度系数,用于当样本数据不足(小于5个)时取一个大于1的值,样本数据越少该值越大。空间分配&扩展
G1MaxNewSizePercent、G1NewSizePercent,用来控制新生代的大小,默认的情况下G1NewSizePercent为5,也就是占整个堆空间的5%,G1MaxNewSizePercent默认为60,也就是堆空间的60%。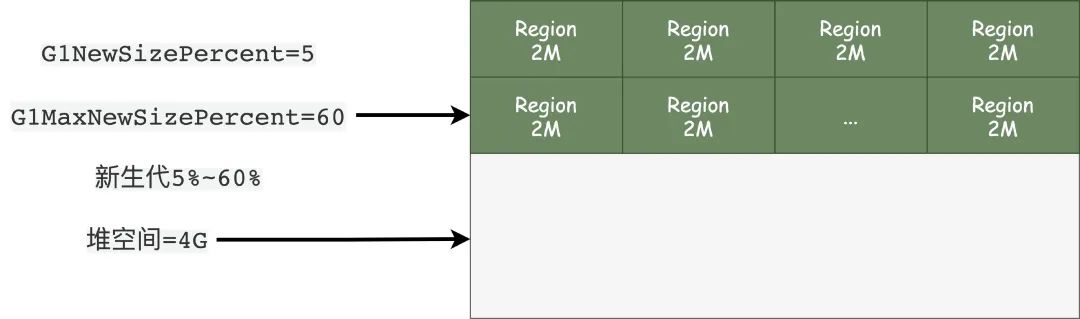
-Xms设置初始堆的大小,-Xmx设置最大堆的大小还是生效的,可以设置堆的大小。可以通过原有参数 -Xmn或者新的参数G1NewSizePercent、G1MaxNewSizePercent来设置年轻代的大小,如果设置了-Xmn相当于设置G1NewSizePercent=G1MaxNewSizePercent。接着看是不是设置了 -XX:NewRatio(表示年轻代与老年代比值,默认值为2,代表年轻代老年代大小为1:2),如果1都设置了,那么忽略NewRatio,反之则代表G1NewSizePercent=G1MaxNewSizePercent,并且分配规则还是按照NewRatio的规则。如果只是设置了 G1NewSizePercent、G1MaxNewSizePercent中的一个,那么就按照这两个参数的默认值5%和60%来设置。如果设置了 -XX:SurvivorRatio,默认为8,那么Eden和Survivor还是按照这个比例来分配
-XX:GCTimeRatio表示GC时间与应用耗费时间比,默认为9,就是说GC时间和应用时间占比超过10%才进行扩展,扩展比例为20%,最小不能小于1M。回收过程
初始标记:标记GC ROOT能关联到的对象,需要STW 并发标记:从GCRoots的直接关联对象开始遍历整个对象图的过程,扫描完成后还会重新处理并发标记过程中产生变动的对象 最终标记:短暂暂停用户线程,再处理一次,需要STW 筛选回收:更新Region的统计数据,对每个Region的回收价值和成本排序,根据用户设置的停顿时间制定回收计划。再把需要回收的Region中存活对象复制到空的Region,同时清理旧的Region。需要STW。
年轻代GC,年轻代Region在超过我们默认设置的最大大小之后就会触发GC,还是用的我们熟悉的复制算法,Eden和Survivor来回倒腾,这里不再赘述。 Mixed GC混合回收,混合回收类似于之前我们的Full GC概念,既会回收年轻代的Region,也会回收老年代的Region,还有我们新的Humongous大对象区域。触发规则根据参数 -XX:InitiatingHeapOccupancyPercent(默认45%)值,也就是说老年代Region达到整个堆内存的45%时触发Mixed GC。
其他问题
记忆集
原始快照SATB
总结
参考: 彭成寒《JVM G1源码分析和调优》 周志明《深入理解Java虚拟机第三版》 美团:Java Hotspot G1 GC的一些关键技术
END


顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」
评论