
PPO算法的一个简单实现:对话机器人
本文接前面文章:
(接上文)
综上,PPO算法是一种具体的Actor-Critic算法实现,比如在对话机器人中,输入的prompt是state,输出的response是action,想要得到的策略就是怎么从prompt生成action能够得到最大的reward,也就是拟合人类的偏好。具体实现时,可以按如下两大步骤实现
1、首先定义4个模型:Actor(action_logits)、SFT(sft_logits)、Critic(value)、RM「r(x, y)」,和kl_div、reward、优势函数adv
从prompt库中采样出来的prompt在经过SFT(微调过GPT3/GPT3.5的模型称之为SFT)做generate得到一个response,这个『prompt + response』定义为sequence(这个采样的过程是批量采样进行generate,得到一个sequence buffer),然后这个sequence buffer的内容做batched之后输入给4个模型做inference
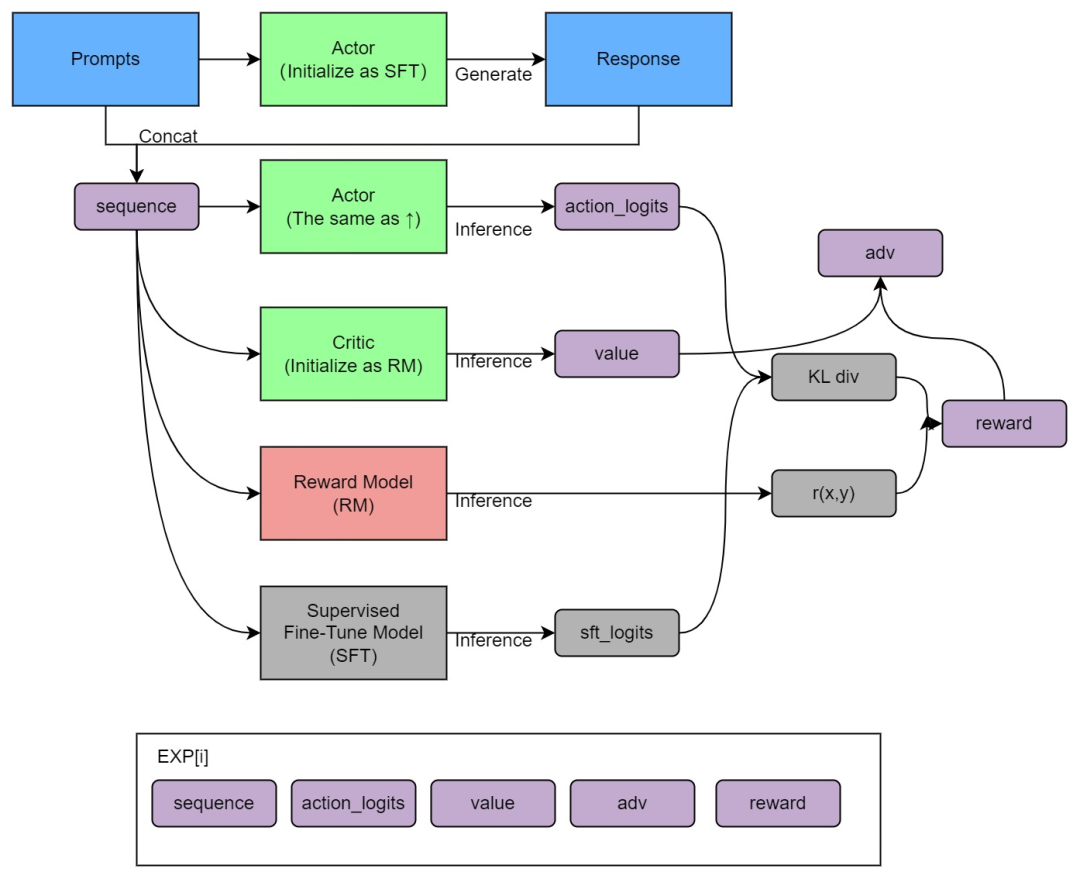
这4个模型分别为Actor、SFT、Critic、RM,其中:
Actor和SFT都是175B的模型,且Actor参数由SFT初始化(SFT是baseline),Actor输出action_logits,SFT输出sft_logits
sft_logits和action_logits做kl_div,为了约束actor模型的更新step不要偏离原始模型SFT太远
Critic和RM是6B的模型,Critic参数由RM初始化
Critic输出标量value,RM输出标量r(x, y),由r(x, y)和kl_div计算得到reward,reward和value计算得到adv
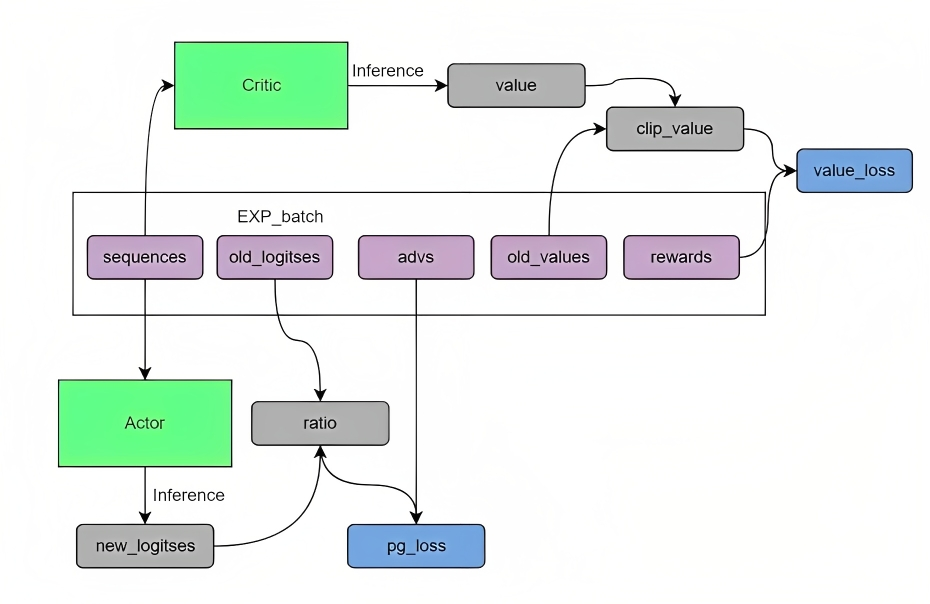
2、其次,通过pg_loss和value_loss优化迭代
Actor的流程是取出sequence,然后inference生成新的logits,再和sequence对应的之前的logits计算ratio,和adv计算出pg_loss,也就是actor的loss,然后反向传播,优化器迭代
Critic的流程是取出sequence,然后inference得到新的value,和old_value做clip_value,再和reward计算value loss,然后反向传播,优化器迭代
代码实现需要的话可以私苏苏老师V:julyedukefu008
✓
好消息
为助力更多小伙伴稳赢下半年—转型成功,升职加薪,七月在线机器学习集训营、高级班限时五折起购!加满额赠课+所有集训营高级班课程一次报名,答疑服务三年
学术/学业/职称论文,申硕/申博,1V1辅导现在需求也越来越旺,如果你有论文需求,别犹豫,七月在线论文保发;国内外求职1V1辅导也如火如荼进行中

有意找苏苏老师(VX:julyedukefu008 )或七月在线其他老师申请试听/了解课程
(扫码联系苏苏老师)
点击“阅读原文”了解更多

评论