
数据库、数据仓库、大数据平台、数据中台、数据湖对比分析
写在前面
层出不穷的新技术、新概念、新应用往往会对初学者造成很大的困扰,有时候很难理清楚它们之间的区别与联系。本文将以数据研发相关领域为例,对比分析我们工作中高频出现的几个名词,主要包括以下几个方面:
数据 什么是大数据 数据分析与数据挖掘的区别是什么 数据库 什么是数据库 数据库中的分布式事务理论 数据仓库 什么是数据仓库 什么是数据集市 数据库与数据仓库的区别是什么 大数据平台 什么是大数据平台 什么是大数据开发平台 数据中台 什么是数据中台 数据仓库与数据中台的区别与联系 数据湖 什么是数据湖 数据仓库与数据湖有什么区别与联系
希望本文对你有所帮助,烦请读者诸君分享、点赞、转发。
数据
什么是大数据
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
我们再往深处思考一下,为什么会有大数据(大数据技术)?其实大数据就是在这个数据爆炸增长的时代,业务需求增长促进技术迭代,技术满足需求后又形成闭环促进业务持续增长,从而形成一个闭环。
数据分析与数据挖掘的区别是什么
数据分析可以分为广义的数据分析和狭义的数据分析。广义的数据分析就包括狭义的数据分析和数据挖掘。我们在工作中经常常说的数据分析指的是狭义的数据分析。
| 数据分析(狭义) Data Analysis | 数据挖掘 Data Mining | |
|---|---|---|
| 定义 | 根据分析目的,用适当的统计分析方法及工具,对收集来的数据进行处理与分析,提取有价值的信息,发挥数据的作用。 | 数据挖掘是指从大量的数据中,通过统计学、人工智能、机器学习等方法,挖掘出未知的、且有价值的信息和知识的过程。 |
| 作用 | 主要实现三大作用:现状分析、原因分析、预测分析(定量)。数据分析的目标明确,先做假设,然后通过数据分析来验证假设是否正确,从而得到相应的结论。 | 数据挖掘主要侧重解决四类问题:分类、聚类、关联和预测(定量、定性),数据挖掘的重点在寻找未知的模式与规律;如我们常说的数据挖掘案例:啤酒与尿布等,这就是事先未知的,但又是非常有价值的信息。 |
| 方法 | 主要采用对比分析、分组分析、交叉分析、回归分析等常用分析方法。 | 主要采用决策树、神经网络、关联规则、聚类分析等统计学、人工智能、机器学习等方法进行挖掘。 |
| 结果 | 数据分析一般都是得到一个指标统计量结果,如总和、平均值等,这些指标数据都需要与业务结合进行解读,才能发挥出数据的价值与作用。 | 输出模型或规则,并且可相应得到模型得分或标签,模型得分如流失概率值、总和得分、相似度、预测值等,标签如高中低价值用户、流失与非流失、信用优良中差等。 |
数据库
什么是数据库
数据库是按照数据结构来组织、存储和管理数据的仓库。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
一般而言,我们所说的数据库指的是数据库管理系统,并不单指一个数据库实例。
根据数据存储的方式不同,可以将数据库分为三类:分别为行存储、列存储、行列混合存储,其中行存储的数据库代表产品有Oracle、MySQL、PostgresSQL等;列存储的数据代表产品有Greenplum、HBASE、Teradata等;行列混合存储的数据库代表产品有TiDB,ADB for Mysql等。
数据库中的分布式事务理论
ACID
传统关系型数据库事务设计原则,以下四点必须全部满足:
原子性Atomicity:事务中操作要么都发生,要么都不发生; 一致性Consistency:事务前后数据完整性保持一致; 隔离性Isolation:多个用户并发事务相互隔离; 持久性Durability:事务被提交后数据的改变就是永久性的。
举例说明:A账号有200元,B账号有100元,现在A给B账户进行转账操作:
A减少100元,同时B增加100元,两个操作要么都成功要么都失败,满足原子性;
A减少的金额,和B增加的金额要一致,按照一致性;
假如A给B转账的同一时刻,B又给C转账,这两笔交易是相互隔离,满足隔离性;
A给B转账100元,事务提交之后,在查询账号,A减少100元,B增加100元,满足持久性;
CAP理论
2000年,Berkerly大学有位Eric Brewer教授提出了一个CAP理论,在2002年,麻省理工学院的Seth Gilbert(赛斯·吉尔伯特)和Nancy Lynch(南希·林奇)发表了布鲁尔猜想的证明,证明了CAP理论的正确性。所谓CAP理论,是指对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistency)
等同于所有节点访问同一份最新的数据副本。即任何一个读操作总是能够读到之前完成的写操作的结果,也就是说,在分布式环境中,不同节点访问的数据是一致的。可用性(Availability)
每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据。即快速获取数据,可以在确定的时间内返回操作结果。分区容错性(Partition tolerance)
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。即指当出现网络分区时(系统中的一部分节点无法与其他的节点进行通信),分离的系统也能够正常运行,即可靠性。
一个分布式的系统不可能同时满足一致性、可用性和分区容错性,最多同时满足两个。当处理CAP的问题时,可以有一下几个选择:
满足CA,不满足P。将所有与事务相关的内容都放在同一个机器上,这样会影响系统的可扩展性。传统的关系型数据库。如MySQL、SQL Server 、PostgresSQL等都采用了此种设计原则。 满足AP,不满足C。不满足一致性(C),即允许系统返回不一致的数据。其实,对于WEB2.0的网站而言,更加关注的是服务是否可用,而不是一致性。比如你发了一篇博客或者写一篇微博,你的一部分朋友立马看到了这篇文章或者微博,另一部分朋友却要等一段时间之后才能刷出这篇文章或者微博。虽然有延时,但是对于一个娱乐性质的Web 2.0网站而言,这几分钟的延时并不重要,不会影响用户体验。相反,当发布一篇文章或微博时,不能够立即发布(不满足可用性),用户对此肯定不爽。所以呢,对于WEB2.0的网站而言,可用性和分区容错性的优先级要高于数据一致性,当然,并没有完全放弃一致性,而是最终的一致性(有延时)。如Dynamo、Cassandra、CouchDB等NoSQL数据库采用了此原则。 满足CP,不满足A。强调一致性性(C)和分区容错性(P),放弃可用性性(A)。当出现网络分区时,受影响的服务需要等待数据一致,在等待期间无法对外提供服务。如Neo4J、HBase 、MongoDB、Redis等采用了此种设计原则。
数据仓库
什么是数据仓库
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
面向主题的:根据使用者的需求,将来自不同数据源的数据围绕着各种主题进行分类整合。
集成的:来自各种数据源的数据按照统一的标准集成于数据仓库中。
相对稳定的:数据仓库中的数据是一系列的历史快照,不允许修改或删除,只涉及数据查询。
反映历史变化的 :数据仓库会定期接收新的集成数据,从而反映出最新的数据变化。
数据库与数据仓库有什么区别
严格来讲数据仓库不是一门技术,也不是一个产品。像前文提到的关系型数据库MySQL和Oracle都属于一种产品。那么是什么数据仓库的,见名知意,其实就是存储数据的仓库,数据的来源有很多种,可以统一在数据仓库中进行汇合,然后通过统一的建模,加工成服务与数据分析的数据模型,辅助企业分析决策。
那么,数据仓库该怎么构建呢,目前使用Hive构建数据仓库的比较多,本文不会过多分析这些大数据技术。总之一句话,数据仓库涉及数据建模,数据抽取ETL,数据可视化等一系列的流程,是一种数据解决方案,通常需要多种技术进行组合使用。
数据仓库的本质是OLAP,即是做在线分析处理,这是与数据库的本质区别。还有一点既然是数据仓库,肯定是要加工数据,那么加工数据肯定耗时间,所以加工数据在实际的应用中又分为批处理和实时处理。
数据库是为了解决OLTP而存在的,而数据仓库是为了分析数据而存在的。数据库的数据是数据仓库的数据源,即将数据库的数据加载至数据仓库,所以说,数据仓库不生产数据,只做数据的搬运工。
还有一点就是,数据仓库并不是必须的,但是对于一个业务系统而言,数据库是必须的。只有在业务稳定运转的情况下,才会去构建企业级数据仓库,通过数据分析,数据挖掘来辅助业务决策,实现锦上添花。
| 数据库 | 数据仓库 | |
|---|---|---|
| 数据处理类型 | OLTP | OLAP |
| 使用人员 | 业务开发人员 | 分析决策人员 |
| 核心功能 | 日常事务处理 | 面向分析决策 |
| 数据模型 | 关系模型(ER) | 多维模型(雪花、星型) |
| 数据量 | 相对较小 | 相对较大 |
| 存储内容 | 存储当前数据 | 存储历史数据 |
| 操作类型 | 查询、插入、更新、删除 | 查询为主:只读操作、复杂查询 |
什么是数据集市
数据集市(Data Mart),也叫数据市场,就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
从范围上来说,数据集市的数据是从数据库,或者是更加专业的数据仓库中抽取出来的。数据集市分为从属的数据集市与独立的数据集市:
独立型数据集市的数据来自于操作型数据库,是为了满足特殊用户而建立的一种分析型环境。这种数据集市的开发周期一般较短,具有灵活性,但是因为脱离了数据仓库,独立建立的数据集市可能会导致信息孤岛的存在,不能以全局的视角去分析数据。
从属型数据集市的数据来自于企业的数据仓库,这样会导致开发周期的延长,但是从属型数据集市在体系结构上比独立型数据集市更稳定,可以提高数据分析的质量,保证数据的一致性。
| 指标 | 数据仓库 | 数据集市 |
|---|---|---|
| 数据来源 | OLTP系统、外部数据 | 数据仓库 |
| 范围 | 企业级 | 部门级或工作组级 |
| 主题 | 企业主题 | 部门或特殊的分析主题 |
| 数据粒度 | 最细的粒度 | 较粗的粒度 |
| 历史数据 | 大量的历史数据 | 适度的历史数据 |
| 目的 | 处理海量数据,数据探索 | 便于某个维度数据访问和分析,快速查询 |
大数据平台
什么是大数据平台
大数据平台是一个集数据接入、数据处理、数据存储、查询检索、分析挖掘等、应用接口等功能为一体的平台。通俗的理解包括Hadoop生态的相关产品,比如Spark、Flink、Flume、Kafka、Hive、HBase等等等经典开源产品。
提到Hadoop生态技术,不得不提的是Apache和Cloudera。国内绝大部分公司的大数据平台都是基于这两个分支的产品进行商业化包装和改进。例如:阿里云EMR、腾讯TBDS、华为FusionInsight、新华三DataEngine、浪潮Insight HD、中兴DAP等产品。
其实,对于大数据平台,业内并无一个固定的能力范围。当前比较权威的是全国信标委今年发布了大数据平台的国标 《GB/T 38673-2020 信息技术 大数据 大数据系统基本要求》,将大数据系统划分为数据收集、数据存储、数据预处理、数据处理、数据分析、数据访问、资源管理、系统管理8个部分,分别对各部分提出技术要求。所以会发现每个厂家推出的大数据平台都包含很多功能、甚至组合的产品,属于大数据的产品种类非常多。
什么是大数据开发平台
由于大数据技术很多,单独使用的学习成本很高,为了提升数据开发的效率,也就出现了大数据开发平台。简单讲,数据开发平台就是集成了大数据平台的一个开发套件,比如阿里云的DataWorks就是一个代表,DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS(Platform-as-a-Service)平台产品,提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。
数据中台
什么是数据中台
阿里巴巴于2017年云栖大会正式对外提出数据中台概念,数据中台的出现,就是为了弥补数据开发和应用开发之间,由于开发速度不匹配,出现的响应力跟不上的问题。中台不是一个产品!与业务强相关。
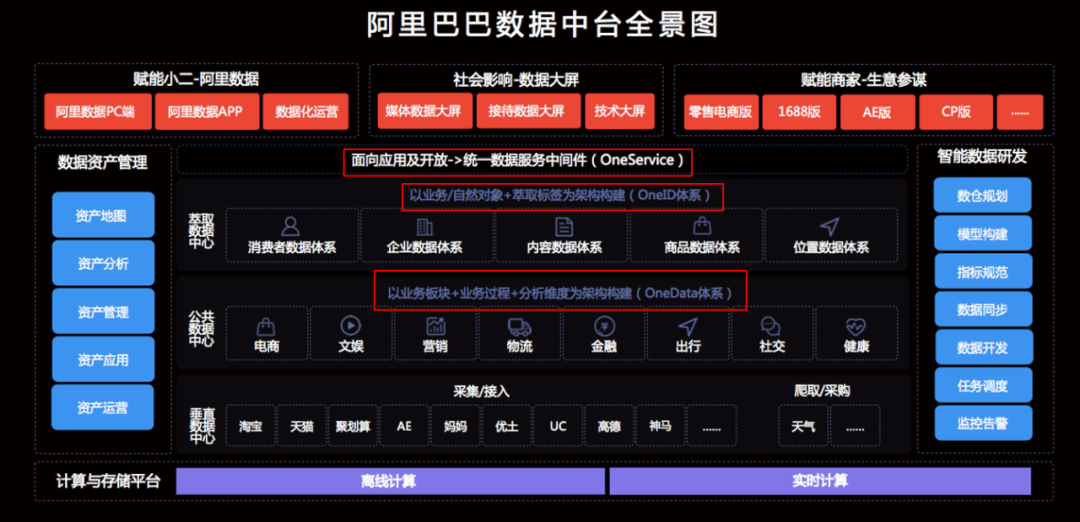
数据中台的一些定义:
| 序号 | 定义 | 定义出处 |
|---|---|---|
| 1 | 中台就是“企业级能力复用平台”。 | 《白话中台战略-3:中台的定义》 |
| 2 | 中台通过集合整个集团的运营数据能力、产品技术能力,来对各前台业务形成强力支撑。 | 《大型集团性企业的中台战略—阿里的中台战略其实是个伪命题》 |
| 3 | 中台是一种需求分析的方法论,一套能力接入标准,一套运作机制,集中配置、分布执行的控制台。 | 《中台如何助力标准化业务?中台关键要快!》 |
| 4 | “中台”是强调资源整合、能力沉淀的平台体系,为“前台”的业务开展提供底层的技术、数据等资源和能力的支持。 | 《大中台 小前台》 |
| 5 | 中台是居于前台和后台之间、位于基础架构和各产品线间的业务架构。 | 《关于架构的思考-评《阿里巴巴中台战略思想与架构实践》》 |
| 6 | 数据中台是将各个业务板块多年来积累的数据,按业务特征进行横向关联和统一,按数据用途进行纵向分层,最终沉淀为公共的数据服务能力。 | 《传统企业数据中台的建设与思考》 |
| 7 | 数据中台的实质还是组件化,模块化,是设计模式与业务端的应用。 | 袋鼠云数据中台专栏(一):浅析数据中台策略与建设实践 |
| 8 | 中台是一个用技术链接大数据技术能力,用业务链接数据应用场景的能力平台。 | 《阿里中台建设全解密:包含哪些内容?如何发挥作用?》 |
数据仓库与数据中台的区别与联系
| 序号 | 数据仓库 | 数据中台 |
|---|---|---|
| 计算存储 | 基于OLAP类型的数据库构建一套数据存储体系 | 混合架构,随需搭配,满足各类数据 的计算要求 |
| 技术体系 | 传统的ETL开发和报表开发为主 | 数仓建设、数据开发IDE、任务调度、数据集成、数据治理、统一数据服务、数据资产管理、元数据管理、数据质量管理、流批计算、敏捷BI报表开发等多个功能 |
| 应用场景 | 报表为主 | 多元化场景:除了传统报表,还支持商品推荐、精准推送、客满评价等非确定场景的业务,数据服务业务、业务与数据互补,形成闭环 |
| 价值体现 | 面向管理层和业务人员的辅助决策 | 除了完成传统的业务人员辅助决策,还能面向业务系统推动优化升级、数据变现等,把数据资产变成数据服务能力。 |
数据湖
什么是数据湖
Pentaho的CTO James Dixon 在2011年提出了“Data Lake”的概念。在面对大数据挑战时,他声称:不要想着数据的“仓库”概念,想想数据 的“湖”概念。数据“仓库”概念和数据湖概念的重大区别是:数据仓库中数据在进入仓库之前需要是事先归类,以便于未来的分析。这在OLAP时代很常见,但是对于离线分析却没有任何意义,不如把大量的原始数据保存下来,而现在廉价的存储提供了这个可能。
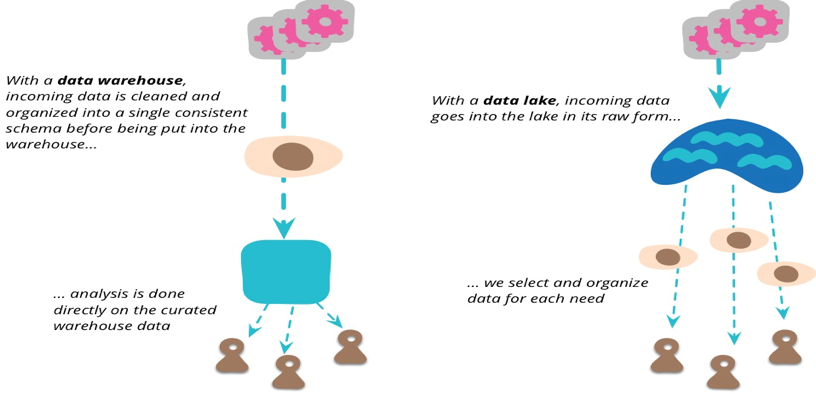
数据仓库是高度结构化的架构,数据在转换之前是无法加载到数据仓库的,用户可以直接获得分析数据。
数据湖中,数据直接加载到数据湖中,然后根据分析的需要再转换数据
数据湖产品—是一套产品组合的解决方案
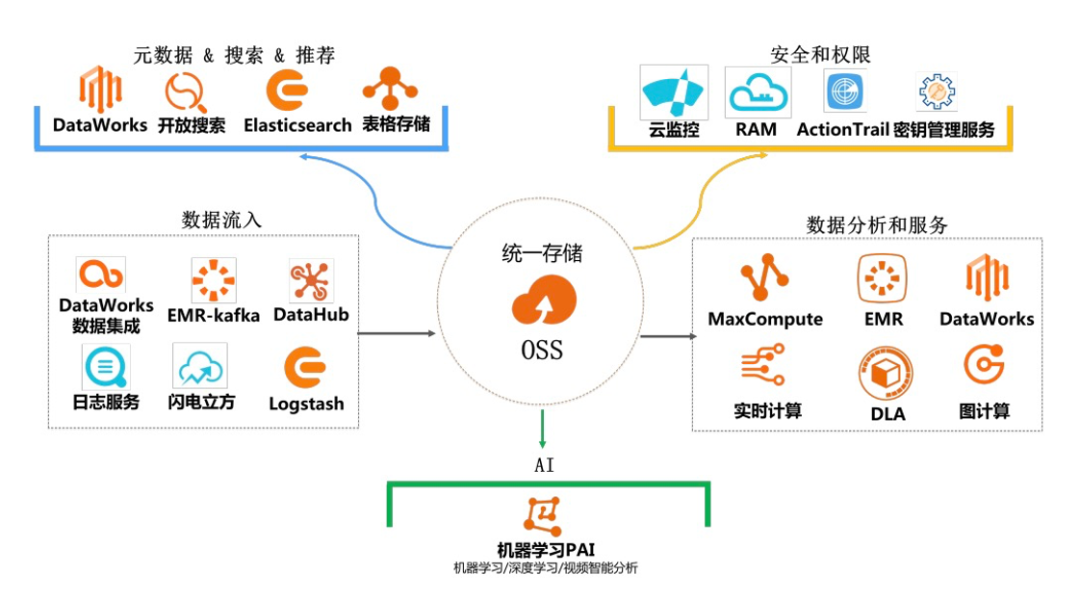
数据仓库与数据湖有什么区别与联系
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 写入型 Schema, 数据存储之前需要定义Schema, 数据集成之前需要完成大量清洗工作 ,数据的价值需要提前明确 | 读取型 Schema, 数据存储之后才需要定义Schema 提供敏捷、简单的数据集成 ,数据的价值尚未明确 |
| 扩展性 | 中等开销获得较大的容量扩展 | 低成本开销获得极大容量扩展 |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 连接方式 | 标准的SQL接口或者BI接口、ANSI SQL | 应用程序、类SQL程序、其它方法 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 复杂性 | 复杂的SQL链接 | 复杂的大数据处理 |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |
| 优势 | 高并发、快速响应、干净安全的数据、数据一次转换多次使用 | 无限扩展性、支持编程框架、数据存储成本低 |

推荐阅读
欢迎长按扫码关注「数据管道」