
万万没想到,BERT学会写SQL了

文 | Giant
编 | NLP情报局
大家好,我是Giant,这是我的第2篇文章。
文本-SQL转化任务,是将用户的自然语言转化为SQL继而完成数据库查询的工作。
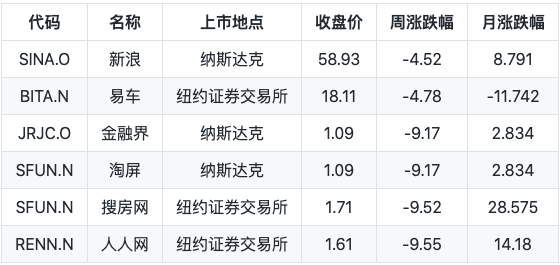
例如根据下表,用户输入一个问题,模型将其转换为 SQL,查询数据库得到结果:"-4.52, -9.55"
Query:新浪和人人网的周涨跌幅分别是多少?
SQL:SELECT 周涨跌幅 FROM 表 WHERE 名称=‘新浪’ OR 名称=‘人人网’
原本要辛辛苦苦写SQL,现在我用大白话告诉机器想看的内容,就能从数据库中拿到答案,这就是Text2SQL。
本文将解读Text2SQL领域最新论文,BERT从中学会了如何编写SQL语言。原文发表在EMNLP 2020会议上。
论文题目:
Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
论文链接:
https://arxiv.org/pdf/2012.12627v2.pdf
开源代码:
https://github.com/salesforce/TabularSemanticParsing
想快速获取论文的小伙伴也可以在订阅号【NLP情报局】后台回复关键词【0119】下载。
01 Text2SQL定义
Text2SQL解决的是将自然语言映射到数据库查询语句SQL的问题。论文中将跨领域的text-to-SQL任务定义如下:
给定自然语言问句
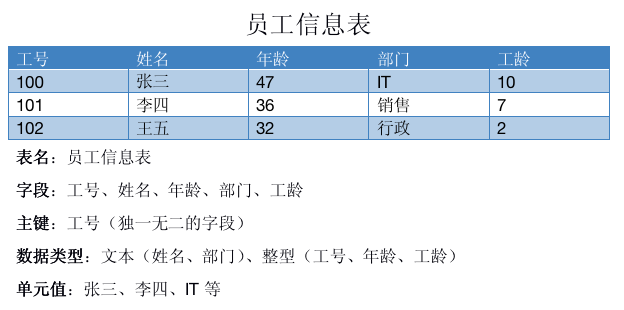
我们知道,一个数据库中可能包含很多张表,一张表又包含多个字段,所以
表中的单元值包含了真实数据信息,例如前文的“人人网”和“新浪”。
明白了什么是Q和S,我们来思考如何搭建模型。
02 模型架构
论文提出的模型BRIDGE采用了主流的Seq2Seq架构,把Text2SQL视作翻译问题(原序列:text,目标序列:SQL),包含编码器和解码器。
编码器
编码器的目的是对Q和S分别做向量编码,同时对两者之间的关系充分交互。
论文中,作者将Q和S拼接为一个混合的问题-模式序列
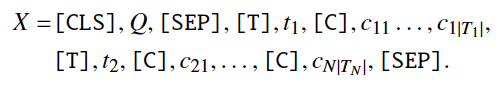
每一个表名、字段名分别用字符[T]和[C]分隔。问题Q和S之间用字符[SEP]分隔。最后,在开始位置插入[CLS]字符。
这样的序列既符合BERT的输入格式,从而优雅地编码跨模态信息,又能快速获取任意字段的编码向量(提取[T]/[C]对应特征即可)。

Meta-data Features
相比于表名,字段名多了主键、外键等属性。为了利用这些特征(meta-data),论文中用了一层前馈网络对表名、字段名进一步编码。
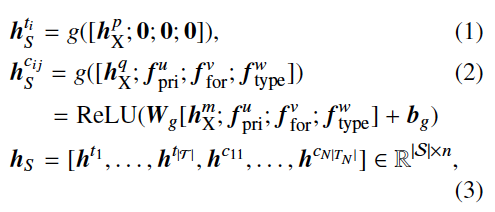
这里的
表名没有额外特征,后三个维度均用零向量替代。各个表名、字段名都进行g函数转化,纵向拼接得到模式的最终编码
Bridging
截至目前,仅仅完成了Q和S的各自编码。读者可能会疑惑,交互在哪呢?
为了解决这个问题,作者使用锚文本(anchor text)将问题Q中包含的单元值与数据库字段链接起来。
具体实现上,作者将问题Q中的每一个token,与数据库表中每一列的所有value值进行字符串模糊匹配,匹配上的value值将被插入到序列X中。
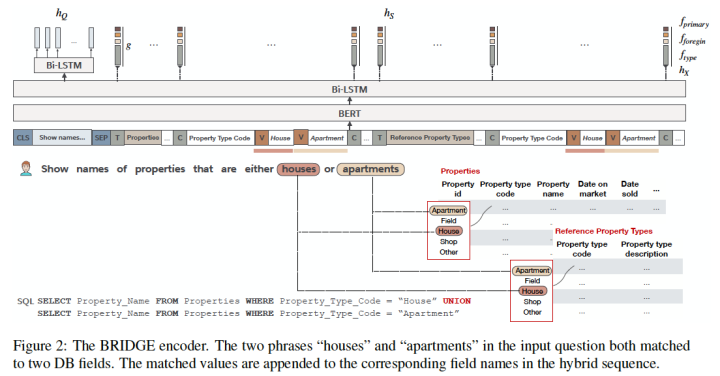
如上图所示,问题Q和表格“Properties”、“Reference Property Types”相关联。其中Q包含的两个单词“houses”和“apartments”与两张表中的同名字段“Property type code”有重合单元值。
字段名“Property type code”本身没有在问题Q中出现,让模型直接推理出“houses”、“apartments”和“Property type code”相关,难度很大。

所以作者在
作者把这种方式称为“bridging”,即模型BRIDGE的由来。
解码器
解码器的目的是从编码特征中还原出相应SQL。
相比于前人的工作(RAT-SQL[2]、IRNet[3]等),BRIDGE解码器设计非常简洁,仅使用了一层带多头注意力机制[4]的LSTM指针生成网络。
在每一个step中,解码器从如下动作中选择1种:
1、从词汇表V中选择一个token(SQL关键字)
2、从问题Q中复制一个token
3、从模式S中复制一个组件(字段名、表名、单元值)
从数学定义上分析,在每一个时刻
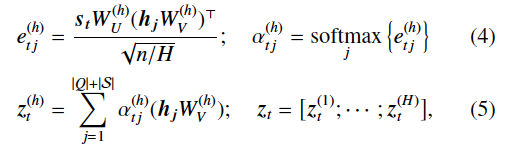
紧接着,作者给出了由V和输出分布产生的概率定义:
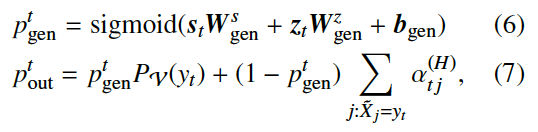
03 数据集与评价指标
作者在WikiSQL、Spider[5]两份数据集上测试了效果。
Spider是耶鲁大学发布的数据集,训练/验证/测试集数据库不重叠,涵盖了几乎所有SQL语法,被公认是难度最大的Text2SQL数据集。

预测评价指标上,作者选择了完全匹配准确率(Exact Set Match)。模型输出SQL的各个子句(select、from、where)需要和标注SQL一一匹配。

04 实验分析
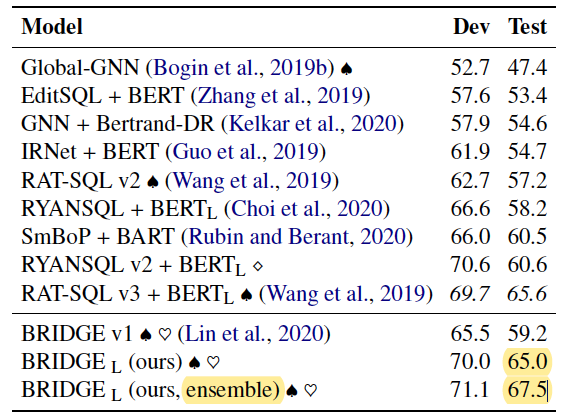
实验部分,作者端到端的训练并测试了模型在Spider上的表现。
模型训练
参数设置部分,作者用交叉熵loss、Adam-SGD优化器、uncased BERT-large训练模型。为确保训练的稳定性,使用了L-inv学习率衰减函数。

最终训练得到的
集成版本的
消融实验
为了证明BRIDGE各个子模块的有效性,作者做了消融分析实验。
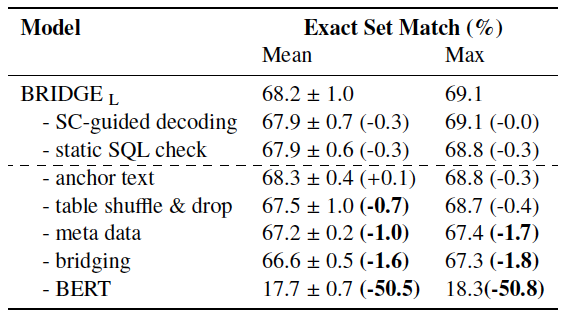
BERT对于最终表现有至关重要的影响,带来3倍以上的提升效果。
此外,在训练过程中随机打乱db中table顺序(防止过拟合)、引入meta-data、bridging机制都有一定的积极作用。
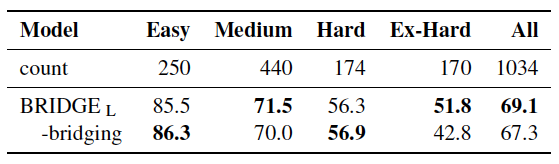
其中,bridging机制对于Ex-Hard难度的样本有显著的提升效果(9%)。
05 错误分析
误差都去哪了呢?作者用最优的BRIDGE模型,随机选择dev上50条预测错误的样本进行了分析。
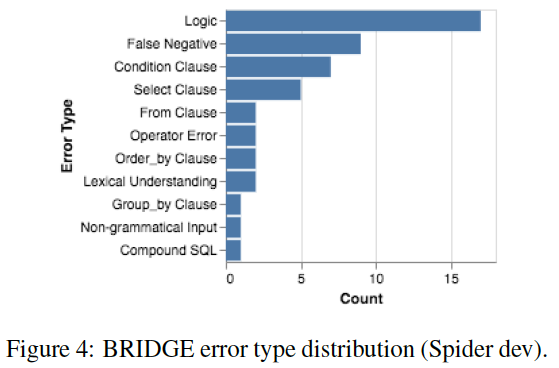
有9条样本属于假负样本(False Negative)。原因在于同一句话可以翻译成不同的SQL,E-SM指标不能发现这种差异。
# 例如“oldest age”,可以用两种SQL表示MAX(age)ORDER BY age DESC LIMIT 1
剩余错误中,36%属于逻辑错误。由于模型的泛化能力不足,或没有结合上下文“死记”训练集出现的固定模式,导致在select、where子句等处预测错误。
当输入的文本包含未见过的单词时,模型容易不知所措,不能准确推理这个词在数据库中的含义。作者认为“持续学习“是一种有效的解决方案。
最后,部分文本在推理时需要结合常识才能完成。例如“older than 21”,结合常识才能推理出
06 总结
这篇论文提出了BRIDGE模型,与BERT结合取得了奇效(提升300%)。
作者也在论文中对比、总结了许多前人的工作。应该说这是一篇SQL解析方向非常Robust的paper!
[1] Xi Victoria Lin, Richard Socher, Caiming Xiong. Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing. Findings of theAssociation for Computational Linguistics: EMNLP, 2020: 4870–4888.
[2] Bailin Wang, Richard Shin, Xiaodong Liu, et al. RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers[C]. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ACL, 2020: 7567–7578.
[3] Jiaqi Guo, Zecheng Zhan, Yan Gao, et al. Towards complex text-to-SQL in cross-domain database with intermediate representation[C]. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. ACL, 2019: 4524–4535.
[4] Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. Attention Is All You Need[C]. Proceedings of the 31st International Conference on Neural Information Processing. NIPS, 2017: 6000-6010.
[5] Tao Yu, Rui Zhang, Kai Yang, et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross- Domain Semantic Parsing and Text-to-SQL Task[C]. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. EMNLP, 2018: 3911–3921.

