
深入探讨:自监督学习的退化解是什么,到底如何避免?

极市导读
本文以如何避免形成推化解作为中心问题出发,从自监督学习的含义开始介绍,解释了InfoNCE公式,最后引出本文的核心问题并进行了回答。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
之所以想要写这篇文章主要是由于很多blog都没有讲明白什么是退化解,以及主流的Self-supervised Learning是如何解决这个问题的,感觉完全没有写到点子上(避重就轻),然而我认为如何避免形成退化解才是Self-Supervised Learning最有意思的点。
以下通过三个问题,层层拨开退化解的迷雾。
什么是Self-Supervised Learning?
InfoNCE如何理解?
如何避免形成退化解?
什么是Self-Supervised Learning?
非常多blog介绍过Self-Supervised Learning这个概念了,但是我觉得大多数解释的太繁琐了,我喜欢简单直接一点。一张图理解什么是Self-Supervised Learning。
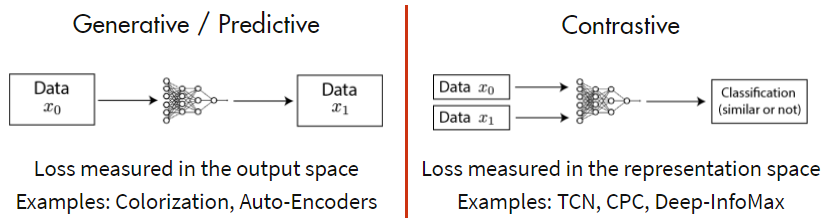
Self-Supervised Learning分成两种方法:一种是生成式模型,一种是判别式模型。以输入图片信号为例,生成式模型,输入一张图片,通过Encoder编码和Decoder解码还原输入图片信息,监督信号是输入输出尽可能相似。判别式模型,输入两张图片,通过Encoder编码,监督信号是判断两张图是否相似(例如,输入同一个人的两张照片,判断输入相似,输出1;输入两个人的照片,判断输入不相似,输出0)。
自从MoCo横空出世横扫7个榜单之后,判别式模型逐渐成为了Self-Supervised Learning的主流。
InfoNCE如何理解?
Self-Supervised Learning的判别式模型一般称为Contrastive Learning,很容易理解,通过对比两个输入是否相似得到输出结果。Contrastive Learning通常使用InfoNCE作为损失函数来训练模型,可以说理解了InfoNCE就基本上能够很好的掌握self-supervised的核心思想。InfoNCE的一般表示如下:
假定给定的 是一对positive pair,比如同一个人的两张照片,同时你还有很多个负样本 ,比如其他人的照片,和x构成 negative pair。这里需要一个数学先验知识,a向量与b向量同向,a.b=|a||b|;a向量与b向量垂直,a.b=0;a向量与b向量反向,a.b=-|a||b|。所以当positive pair的方向尽可能相似,negative pair的方向尽可能不相似时,InfoNCE的值趋近于0。上面是通过数学公式来理解InfoNCE的行为,下面通过unit hypersphere来理解InfoNCE的行为。
InfoNCE公式可以推导成两个部分,alignment和uniformity。
如上图所示,alignment部分只跟positive pair相关,希望positive pair的feature拉近,uniformity部分只跟negative pair相关,希望所有点的feature尽可能均匀分布在unit hypersphere上。

使不同的feature尽可能均匀的分布在unit hypersphere上带来的一个好处是非常容易的对不同类别聚类并且线性可分。
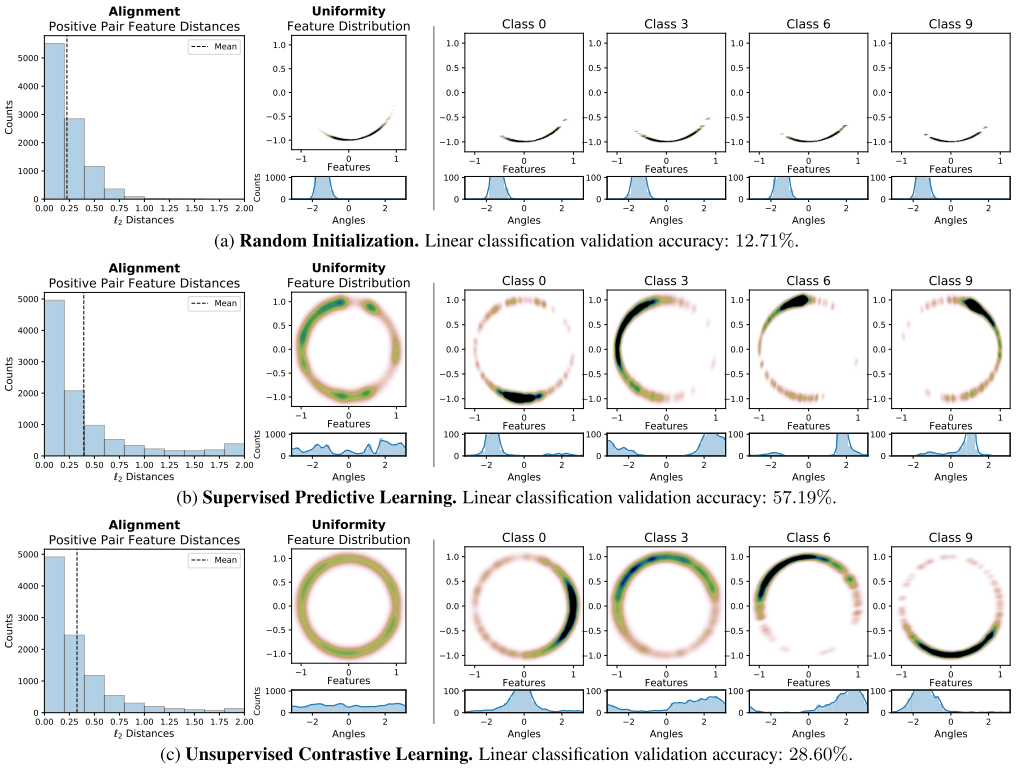
作者在CIFAR-10上分别对Random Initialization、Supervised Predictive Learnging和Unsupervised Contrastive Learning三种模型进行实验,观察到了上述unit hypersphere的实验结论,Random Initialization没有将不同类别的feature均匀的分开,导致alignment的平均距离很小,但是判别力很差;Supervised Predictive Learnging因为监督信号的引导,不同类别的feature既散开又集中,又因为引入了标注偏见,导致alignment的平均距离介于Random Initialization和Unsupervised Contrastive Learning之间;而Unsupervised Contrastive Learning的feature非常均匀连续的散开,alignment的平均距离是最小的,说明Unsupervised Contrastive Learning确实能够得到非常强判别力的特征。
如何避免形成退化解?
从数学公式上看,InfoNCE的alignment和uniformity两部分理论上来说是缺一不可的。如果只有uniformity,没有alignment,那么模型没有聚类的能力;如何只有alignment,没有uniformity,那么容易使得模型将所有的输入输出相同表示,也就是形成退化解。最近一些主流的Self-Supervised方法对于如何避免形成退化解进行了大量的探索,以下主要介绍一下SimCLR/BYOL/SwAV/SimSiam四种SSL算法是如何避免形成退化解的。(ps:示意图源自SimSiam)
SimCLR
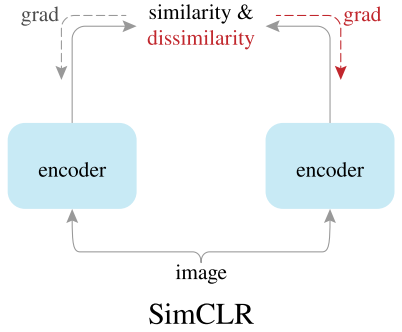 SimCLR先将输入图片通过两种不同的数据增强生成x和y,然后通过相同的encoder和projection(上图没有画出)分别生成x‘和y',然后使用同时考虑alignment和uniformity的InfoNCE来对encoder进行梯度更新,并且梯度同时对两个分支进行更新。
SimCLR先将输入图片通过两种不同的数据增强生成x和y,然后通过相同的encoder和projection(上图没有画出)分别生成x‘和y',然后使用同时考虑alignment和uniformity的InfoNCE来对encoder进行梯度更新,并且梯度同时对两个分支进行更新。
SimCLR避免形成退化解的方式非常的直接,因为InfoNCE同时包含alignment和uniformity,那么只需要同时构造出positive pair和negative pair,将positive pair的feature尽可能的拉近,negative pair的feature尽可能的均匀分布。
BYOL
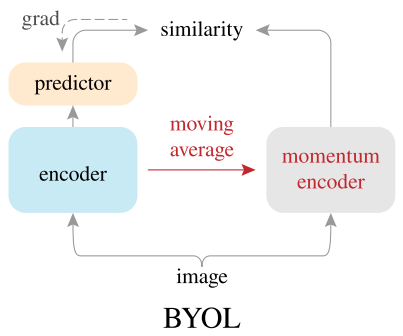
BYOL的想法非常的天马行空,第一个提出只使用positive pair的Self-supervised算法。BYOL将右边的分支看成是target branch,左边的分支看成online branch(非常像知识蒸馏,可以分别看成teacher和student),target branch的encoder通过online branch的encoder参数滑动更新,称为momentum encoder,同时online branch还需要一个predictor,将encoder的输出进行一个变换,target branch不需要进行梯度更新stop gradient,BYOL最核心的点是InfoNCE只考虑alignment部分。
BYOL因为只考虑positive pair,导致非常容易出现退化解,BYOL针对退化解问题,提出了三个主要部分momentum encoder、predictor和stop gradient来避免退化解的形成。我的理解是模型的初始化是随机的,一开始feature就散的很开,然后通过momentum encoder和stop gradient使得target branch的feature变化缓慢,而online branch的feature变化更快,最后online branch通过predictor使变换得到的feature接近target branch的feature,predictor组件大大降低了positive pair拉近的难度,并且增加了feature变换的多样性,防止退化解的产生。BYOL的predictor不同于SimCLR的projection,SimCLR的projection主要作用是为了得到非线性映射,而BYOL的predictor主要作用是为了防止形成退化解。
SwAV
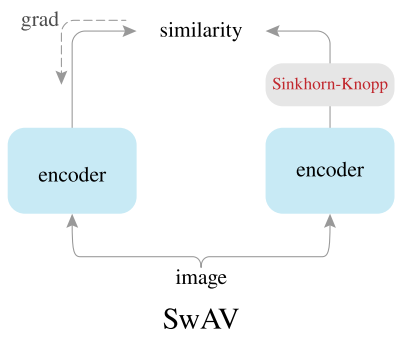 SwAV很特别,引入了聚类的方法。SwAV预先定义了k个聚类中心,然后将teacher和student两个分支的输入通过Sinkhorn-Knopp算法映射到k个聚类中心的特征空间上,然后通过InfoNCE的alignment部分,对两个分支的映射codes进行拉近。
SwAV很特别,引入了聚类的方法。SwAV预先定义了k个聚类中心,然后将teacher和student两个分支的输入通过Sinkhorn-Knopp算法映射到k个聚类中心的特征空间上,然后通过InfoNCE的alignment部分,对两个分支的映射codes进行拉近。
SwAV通过聚类的方法,大大降低了特征空间的维度,减少计算量。从形式上来看,貌似SwAV只使用了alignment部分,很有可能会出现退化解,实际上映射到k个聚类中心的特征空间的过程中隐含着uniformity部分,因为映射得到的codes是soft label,codes同时蕴含着不同聚类中心的信息,间接避免了退化解的形成。
SimSiam
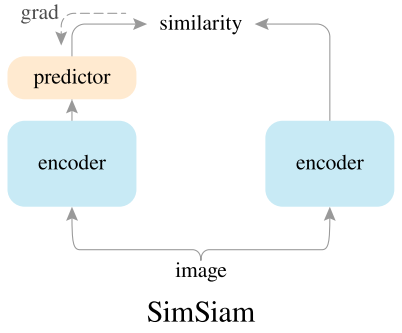
SimSiam在BYOL的基础上进一步进行实验,分别对momentum encoder、predictor和stop gradient等关键组件进行消融实验,最终发现stop gradient才是避免形成退化解的关键。
SimSiam去掉了momentum,去掉了negative,去掉了teacher branch的gradient,在极简的情况下,依然能够避免形成退化解,核心在于stop gradient,teacher branch因为stop gradient导致与student branch的更新不同步,teacher branch相对于student branch是不变的,避免退化解的产生。
总结
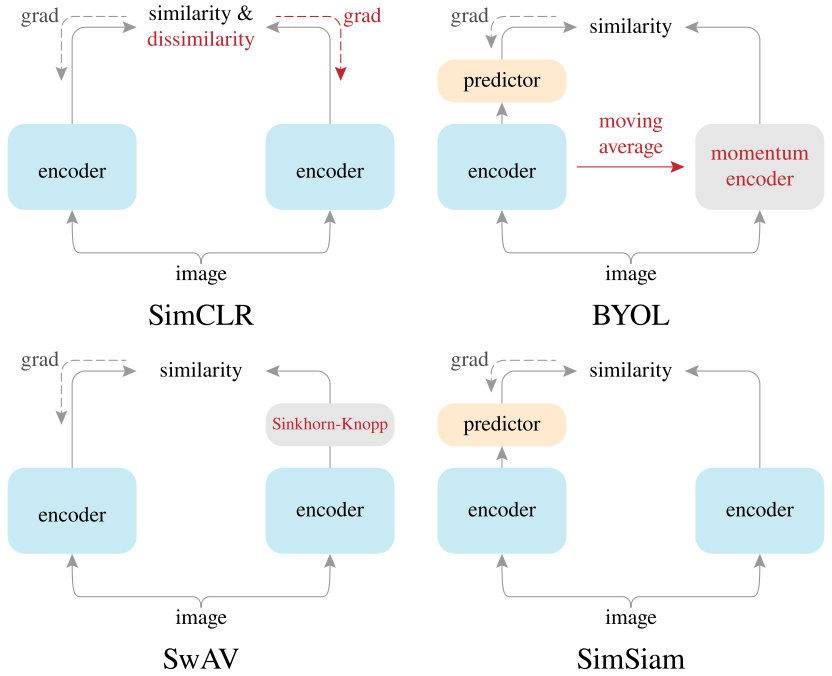
将上述4种方法汇总到一张图片,很容易比对出,四种方法的差异非常之小,基本上只改变了其中一个核心组件,但是都能达到不错的效果。SimSiam可以认为是没有negative的SimCLR,没有online clustering的SwAV,没有momentum encoder的BYOL。
如何避免形成退化解,无外乎同时考虑alignment和uniformity(即需要positive pair也需要negative pair),只考虑alignment(只需要positive pair)和只考虑uniformity(只需要negative pair)三种情况,现在大多数方法都是在探索第一种和第二种。未来可能会逐渐的研究清楚退化解出现的充要条件到底是什么,进而设计出更合理的Self-Supervised算法,学习到更好的特征表示。
Reference
[1] https://ankeshanand.com/blog/2020/01/26/contrative-self-supervised-learning.html
[2] https://zhuanlan.zhihu.com/p/129076690
[3] https://www.zhihu.com/question/402452508/answer/1294166177
[4] Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
[5] A Simple Framework for Contrastive Learning of Visual Representations
[6] Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
[7] Unsupervised Learning of Visual Features by Contrasting Cluster Assignments[8] Exploring Simple Siamese Representation Learning
亮点提要:
1.Self-Supervised Learning两种方法:生成式模型;判别式模型。
2.InfoNCE公式可以推导成两个部分:alignment和uniformity。
3.只有Unsupervised Contrastive Learning能够得到非常强判别力的特征。
4.避免形成退化解的三种情况:1.同时考虑alignment和uniformity(即需要positive pair也需要negative pair),2.考虑alignment(只需要positive pair),3.只考虑uniformity(只需要negative pair)
△点击卡片关注极市平台,获取最新CV干货
推荐阅读
2021-04-14
2021-04-13

2021-04-06

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
