
Elasticsearch ILM 索引生命周期管理常见坑及避坑指南
之前的博文和视频都讲过 ILM 索引生命周期管理。但从近期的反馈和我自己的实战经验看,依然会有很多坑。
现将我自己和大家遇到的常见坑汇集如下,希望能让后来小伙伴少走弯路。
少啰嗦,直接上干货。
坑1:刷新频率按需设置
这里指的刷新频率不是:refresh_interval 数据写入段的刷新频率,而是:indices.lifecycle.poll_interval。
indices.lifecycle.poll_interval 指的是:索引生命周期管理检查符合 policy 策略标准的索引的频率,本质上是检查是否满足 rollover 的周期频率值。
poll_interval 默认 10 分钟,也就是每间隔10分钟检查一次。
大家如果用过老版本的 rollover 实现——每次执行前都需要手动执行一次 rollover,就能更好的理解 poll_interval 的妙处,本质上减少人工触发,系统自动定期运行。
如果大家是demo 阶段自己验证 ILM,一般建议这个值调小。
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
坑2:提前划分好节点角色
这里要区分一下版本
| 版本 | 7.9版本之前 | 7.9+版本之后 |
|---|---|---|
| 是否区分节点角色 | 没有区分 | 已经区分 |
7.9 之前的早期版本没有节点角色的概念,冷热温节点角色的划分需要新配置属性,配置类似如下:
node.attr.hotwarm_type: warm
而 7.9+ 版本之后,全部通过节点角色搞定。

仅数据层面的节点角色做了如下细分:
data_hot 热节点 data_warm 暖节点 data_cold 冷节点 data_content 数据内容节点 data:原有数据节点
在配置节点角色时,建议data_hot、data_warm、data_cold 节点角色 要和 data_content 一起配置。
且 data_hot/data_warm/data_cold 不要和原有的 data 角色节点一起配置。
A node can belong to multiple tiers, but a node that has one of the specialized data roles cannot have the generic data role.
如果仅配置data_hot 角色不设置 data_content 角色会导致集群数据写入后无法落地。
我的理解:data_hot, data_warm, data_cold 是标识性的节点,实际落地存储还得靠 data_content 角色。
坑3:冷热架构要考虑非时序数据
继续针对第2点的节点角色展开讨论。一些特定业务场景不见得每条索引数据都有日期或时间字段,举例:
企业业务数据
电子商务数据
用户信息数据库数据
对于上述类型数据,如果节点角色仅划分了:data_hot、data_warm、data_cold 角色,会导入数据无法写入。
破解之道就是:混合设置 data_hot / data_warm / data_cold 与 data_content 角色。
三节点的样例冷热集群架构集群节点角色划分如下:
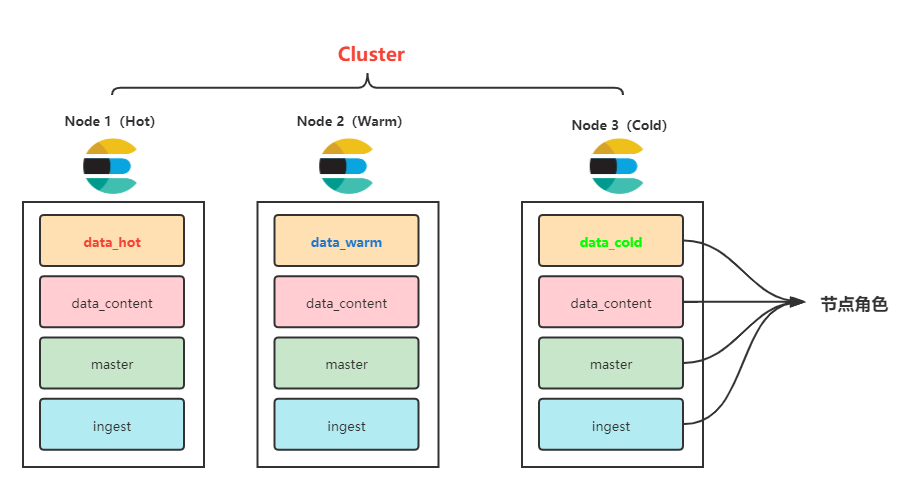
elasticsearch.yml 配置文件如下:
node.roles: [ data_hot, data_content, master, ingest ]
4、坑4:配置了节点角色的热温冷节点数据迁移不再需要配置分片分配策略
Elasitcsearch 7.9 之前早期版本,需要配置分片分配策略机制。举例如下:
"allocate":
{
"require":
{
"box_type": "warm"
}
7.9+之后新版本相当于我们提前预设定了冷热集群架构的节点不同的角色,后台会帮我们自动迁移。
我们只需要设置好不同的横向:phrase 和 每个phrase 下的不同的 action(rollover, freeze, number_of_replicas delete forcemerge 操作)就可以了,其他的我们不需要关注了。

后台会有定时任务轮询完整数据各个 phrase 阶段的更迭。
总之,7.9+版本的ILM 结合了节点的角色和自动分配迁移机制,变得更灵活、更省心、更方便。
5、坑5:ILM 配置没问题,但不生效,如何排查?
GET 索引名称/_ilm/explain
结果出来,了无秘密。

6、坑6:对于 min_age 的正确理解?
官方 How to prepare 视频中有这么一道样题:
“Define a new data stream on cluster1 that satisfies the following requirements: the index pattern is logs-my.app-production the corresponding index template is named task3 the data is hot for 3 minutes, then immediately rolls over to warm the data is warm for 5 minutes, then rolls over to cold 10 minutes after rolling over, the data is deleted
min_age 在这里该如何设置?
球友类似如下问题问过 5 次以上。
你好, 问一个关于ilm配置的问题,一直想不明白他每个阶段配置的min_age的含义是针对的什么?是索引创建多久后移动到这个阶段吗?还是在上个阶段停留多长时间后到这个阶段?——来自死磕Elasticsearch 知识星球
我们先把官方对:min_age 的解释全都汇聚在这里,然后逐步给出答案。
6.1 min_age 定义
在 ILM 中,索引基于 min_age 参数进入一个阶段(phrase)。
min_age通常是指从索引被创建时算起的时间。在索引生命周期管理检查min_age并过渡到下一个阶段之前,前一个阶段的操作必须完成。
还是云里雾里,对吧?来吧,看个例子:
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": {
"min_age": "1d",
"actions": {
"allocate": {
"number_of_replicas": 1
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
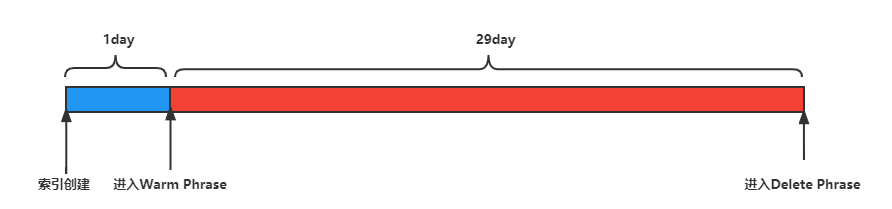
上面的示例配置了一个策略:
在 1 天后将索引移动到 warm 暖阶段。在此之前,索引处于等待状态。 进入 warm 暖阶段后,它将等到 30 天后才进入删除 delete 阶段并删除索引。
https://www.elastic.co/cn/blog/control-ilm-phase-transition-timings-using-origination-date
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/_timing.html
6.2 未指定 min_age 会怎么样?
如果创建的策略Policy 具有未指定 min_age 的热阶段,min_age 默认为 0 ms。
表示该阶段中的操作完成后,索引将立即从一个阶段过渡到下一个阶段,也就意味着索引会在应用策略(policy)时立即进入热阶段。
6.3 更新 min_age 会怎么样?
如果随后更新策略将指定热阶段的 min_age 为 1 天,这对已经处于热阶段的索引没有影响。policy 更新后创建的索引在一天之内不会进入hot 阶段。
也就是说,只对新写入数据生效,老数据不生效。
https://www.elastic.co/guide/en/elasticsearch/reference/master/update-lifecycle-policy.html
6.4 官方题目该如何解读?
the data is hot for 3 minutes, then immediately rolls over to warm the data is warm for 5 minutes, then rolls over to cold 10 minutes after rolling over, the data is deleted
上图:
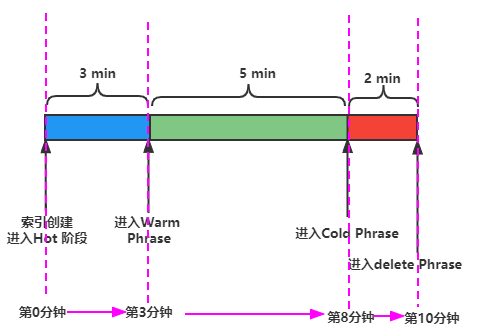
有了这张图,一切都变得非常清晰。
Hot Phrase:索引创建后立即进入 Hot 阶段,保持 3 分钟。
Warm Phrase:索引创建 3 分钟后进入 Warm 阶段,保持 5分钟。
Cold Phrase:索引创建 8 分钟后进入 Cold 阶段,保持 2 分钟。
Delete Phrase:索引创建 10 分钟后进入 Delete 阶段。
上答案:
PUT _ilm/policy/ece_policy_20220116
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_primary_shard_size": "50gb",
"max_age": "3d",
"max_docs": 5
},
"set_priority": {
"priority": 100
},
"alias":{
"hot_alias":{}
}
}
},
"warm": {
"min_age": "3m",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"set_priority": {
"priority": 55
},
"allocate": {
"number_of_replicas": 0
}
}
},
"cold": {
"min_age": "8m",
"actions": {
"freeze": {},
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "10m",
"actions": {
"delete": {}
}
}
}
}
}
7、小结
本文结合实战环境解读了 ILM 使用环节常见的坑,并一一给出了解决方案或者完全解读。
ILM 索引生命周期管理,你在实战环境中用起来了吗?
有没有遇到什么问题,欢迎留言交流。
参考
https://www.elastic.co/cn/blog/elasticsearch-data-lifecycle-management-with-data-tiers
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/ilm-explain-lifecycle.html
推荐
更短时间更快习得更多干货!
已带领88位球友通过 Elastic 官方认证!
