
浅谈弱监督学习(Weakly Supervised Learning)
地址:https://zhuanlan.zhihu.com/p/81404885
之前看了周志华老师的《A Brief Introduction to Weakly Supervised Learning》,觉得大受启发,一直想动笔总结一下,今天终于来填坑了。
机器学习在很多任务中取得了很大的成功。众所周知,在机器学习领域,学习任务可大致划分为两类,一种是监督学习,另一种是非监督学习。通常,两者都需要从包含大量训练样本的训练数据集中学习预测模型,每个训练样本对应于事件/对象。如下图所示。
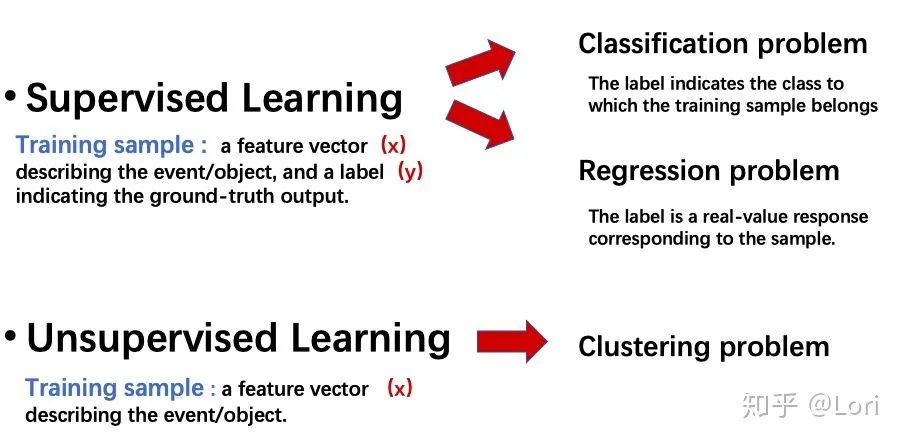
监督学习的训练数据由两部分组成:描述事件/对象的特征向量(x),以及 groud-truth 的标签(y)。
而非监督学习的训练数据只有一个部分:描述事件/对象的特征向量(x),但是没有标签(y)。
分类问题和回归问题是监督学习的代表,聚类学习是非监督学习的代表。在分类中,标签对应于训练样本属于哪一类。在回归中,标签对应于该示例的真实值响应。
那么,什么是分类问题,什么是回归问题,什么是聚类问题呢?让我们来看一个简单的例子。
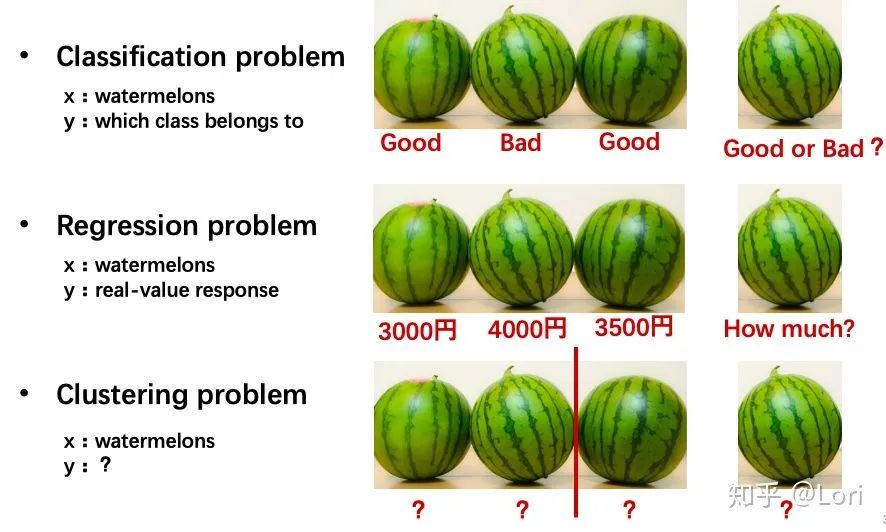
比如说,这有一些西瓜。
对于分类问题来说,x是一些西瓜,y是属于的类别,好的西瓜或者坏的西瓜。现在我们已经知道每一个西瓜是好的或坏的,如果我们有一个新的西瓜,我们需要根据之前的经验判断它是好的或者坏的。
对于回归问题来说,x是西瓜,y是真实值响应。我们知道这个西瓜是3000日元,这个西瓜是4000日元,这个西瓜是3500日元,如果我们有一个新的西瓜,我们需要根据之前的经验去预测这个西瓜多少钱。
对于聚类问题来说,我们只知道我们有这些西瓜,x是西瓜,也许他们有一些不同之处,也许是更好吃或不好吃,也许是更便宜或不便宜,我们需要计算机自己去找到一些特征,将这些相似的西瓜聚成一类,如果我们有一个新的西瓜,需要判断它属于哪一类。
尽管当前监督学习技术已经取得了巨大的成功,但是值得注意的是,由于数据标注过程的成本太高,很多任务很难获得如全部真值标签这样的强监督信息。而无监督学习由于学习过程太过困难,它的发展缓慢。因此,希望机器学习技术能够在弱监督状态下工作。南京大学周志华教授在2018年1月发表了一篇论文,叫做《A Brief Introduction to Weakly Supervised Learning》,对机器学习任务给出了一个新的趋势和思路。个人觉得总结的非常好,大受启发,有兴趣的小伙伴可以去看看原论文~

什么是弱监督学习呢?文章里说,弱监督学习可以分为三种典型的类型,不完全监督(Incomplete supervision),不确切监督(Inexact supervision),不精确监督(Inaccurate supervision)。
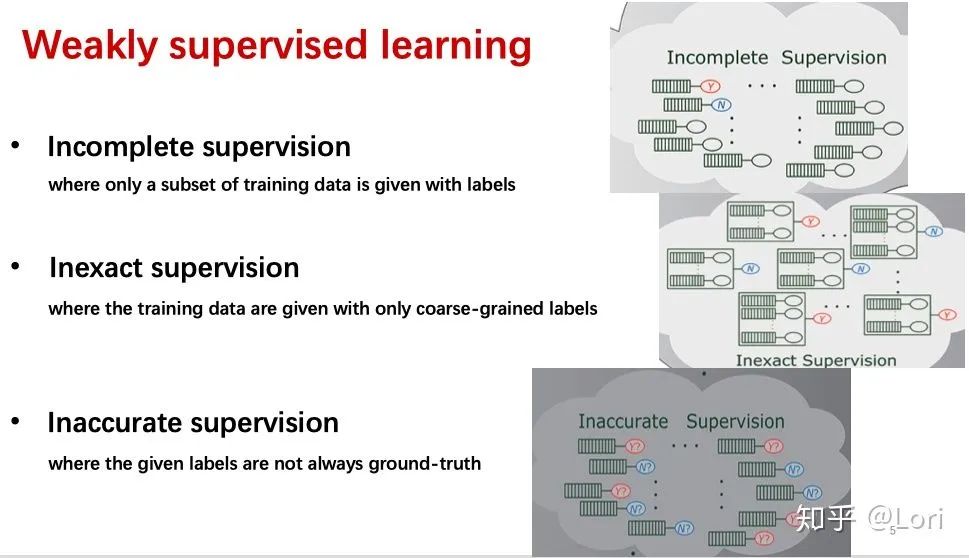
不完全监督是指,训练数据中只有一部分数据被给了标签,有一些数据是没有标签的。
不确切监督是指,训练数据只给出了粗粒度标签。我们可以把输入想象成一个包,这个包里面有一些示例,我们只知道这个包的标签,Y或N,但是我们不知道每个示例的标签。
不精确监督是指,给出的标签不总是正确的,比如本来应该是Y的标签被错误标记成了N。
我们还是用最简单的西瓜的例子来直观理解一下这三者的区别。
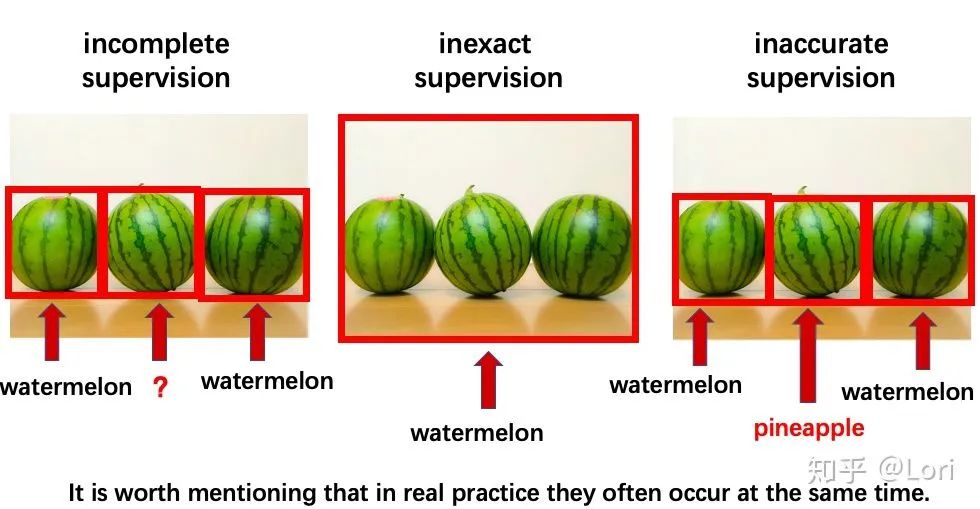
最左边是不完全监督,即我们可以看到有一些西瓜有标签,而有一些西瓜没有标签,标注并不完全。
中间的是不确切监督。对于这种情况,我们可以把这个想象成一个包,只知道这里面有西瓜,但是不知道西瓜在哪个位置,也不知道有几个,这种情况叫不确切监督。
最右边的是不精确监督。即假设我们有一些西瓜,但是有一些被错误标注为菠萝,那我们称之为不精确监督。
我们将分别对待这些类型的弱监督学习,但值得一提的是,在实际操作中,它们经常同时发生。

实际上,弱监督学习普遍存在。
比如,在图像分类任务中,训练数据的Groud-Truth标签由人类注释者给出; 虽然很容易从互联网上获取大量图像,而由于人工成本,只能注释一小部分图像。(不完全监督)
在重要目标检测中,我们常常仅有图片级标签,而没有对象级标签。(不确切监督)
在众包数据分析中,当图像标记者粗心或者疲倦时,或者有些图片很难去分类时,这将会导致一些标签被标记错误。(不精确监督)
针对这三种典型的弱监督学习,我们可以考虑使用不同的技术去进行改善和解决。如下图所示。
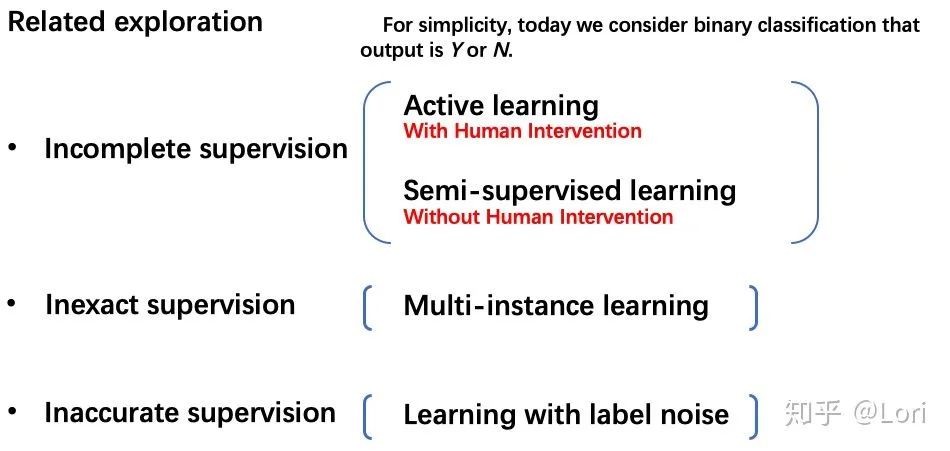
为了解决不完全监督,我们可以考虑两种主要技术,主动学习和半监督学习。一种是有人类干预的,一种是没有人类干预的。
为了解决不确切监督,我们可以考虑多示例学习。
为了解决不精确监督,我们考虑带噪学习。
下面我们稍微具体一点来谈一谈以上列举的方法。
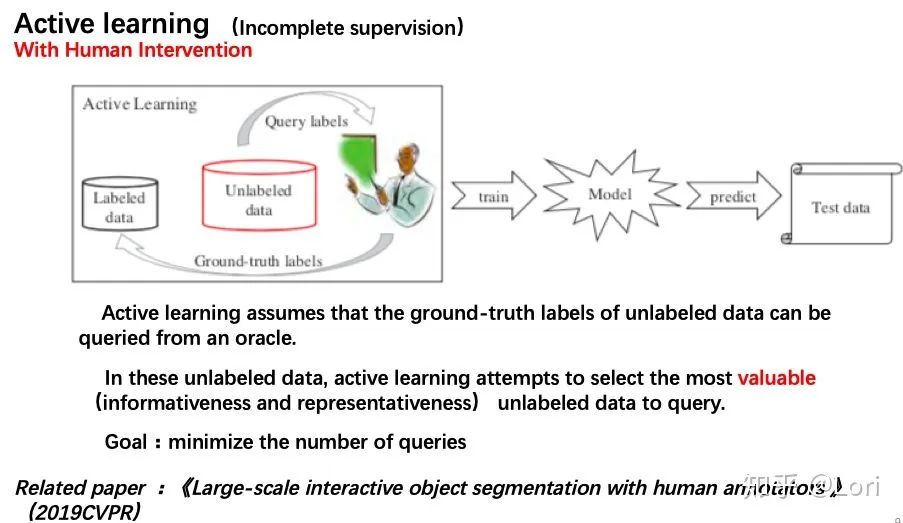
首先为了解决不完全监督,我们考虑主动学习(Active learning),这个方法是训练过程中有人工干预的。
输入是一些标注过的数据(包含x,y)和没有标注过的数据(只有x),输出是Y或者N(考虑最简单的二分类问题)。
首先,我们先训练这些标注过的数据,然后我们根据得到的经验对这些没有标注过的数据进行聚类。主动学习假设可以从oracle查询未标记实例的Groud-truth标签。
在这些未标记数据中,主动学习尝试选择最有价值的未标记实例进行查询。最有价值指的是信息性和代表性。主动学习的目标是最小化查询的数量。
2019年CVPR有一篇主动学习的相关论文,叫《Large-scale interactive object segmentation with human annotators》(如下图)。
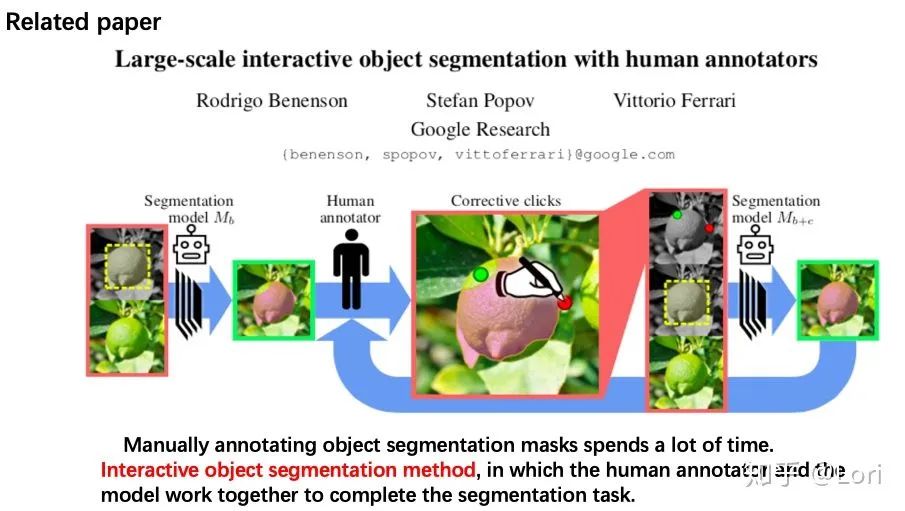
由于手动注释对象分割掩码非常耗时,所以这篇论文考虑交互式对象分割方法,其中人类注释器和机器分割模型协作完成分割任务。
接下来我们看看解决不完全监督的第二种技术,半监督学习(Semi-supervised learning),这种方法没有人类干预(如下图)。
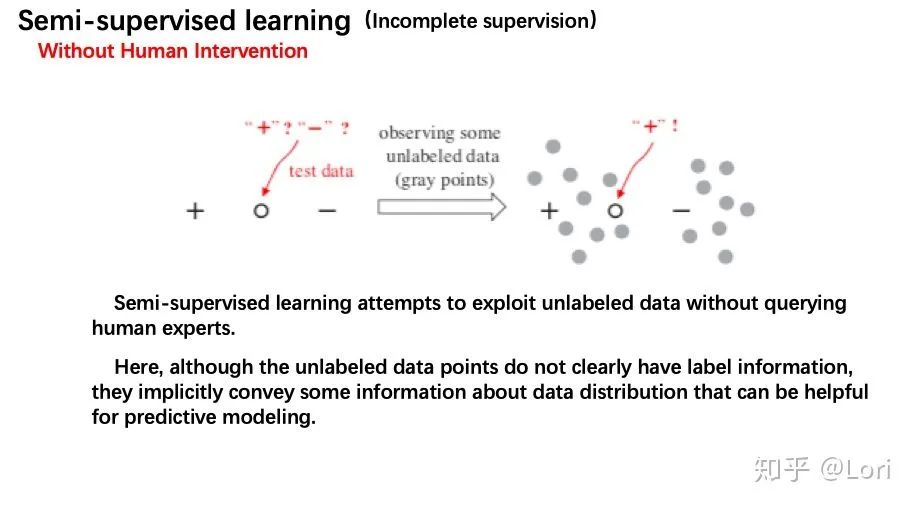
半监督学习尝试在不查询人类专家的情况下利用未标注的数据。但是为什么数据没有标签能够帮助去构建预测模型呢?
让我们看看上图的例子。如果我们已知一个数据是positive,另一个数据是negative,在两个数据点正中间有一个test data,此时我们是很难去判断这个test data到底是positive 还是negative的。但是如果我们被允许去观察一些未被标注的数据分布(右边部分的灰点),这时我们还是可以较肯定的认为test data是positive。
为了解决不确切监督,我们可以考虑多实例学习(Multi-instance learning)。

实际上,几乎所有监督学习算法都有其多实例对等体。
训练数据集中每一个数据看做一个包(Bag),每个包由多个实例(Instance)构成,每个包有一个可见的标签,在上图例子中,假设这个包大小为8*8,如果我们用size为2*2的图片包生成器(Image bag generators)去取得实例,那么我们可以得到16个实例(Instance)。
显而易见,我们这个包是有标签的(左图),老虎,包中的每个实例是没有标签的(右图)。
多实例学习假设每一个正包必须存在至少一个关键实例。这意味着,假设这个例子中关键实例是示例9,那么这个包的标签为正(positive)。多实例学习的过程就是通过模型对包及其包含的多个实例进行分析预测得出包的标签。多实例学习广泛存在在真实世界中,并且应用场景非常广泛。
最后,解决不精确监督,我们可以考虑带噪学习(Learning with label noise)。
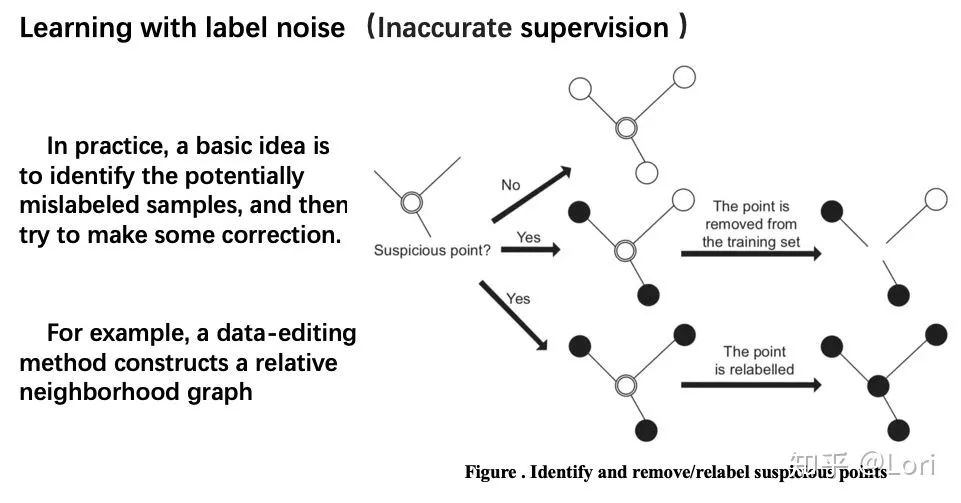
在实践中,基本的思想是识别潜在的误分类样本,然后尝试进行修正。例如,我们用数据编辑的方法去构建一个关系相邻表。然后我们判断一个点是否为可疑点。我们判断这个点和相邻的点是否一样。如果一样,那这个点就不是可疑的,将保持原样。如果这个点和相邻的点不一样,那么这个点是可疑的,这个点将被删除或者被重新标记。
顺便一提,今年的CVPR,也有很多关于弱监督学习的进展。如果你有兴趣的话,可以尝试阅读一下这些论文(虽然我还没来得及读完~)。


最后做个总结吧~

关于弱监督学习,我们谈了弱监督学习下的三种典型:不完全,不确切,不精确的监督。而且我们意识到弱监督学习是广泛并且有很多应用场景的。值得注意的是,无论什么任务或数据,弱监督学习变得越来越重要。
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》