
Python办公自动化,光速对比两份Word/Excel中的不同元素
比较Excel
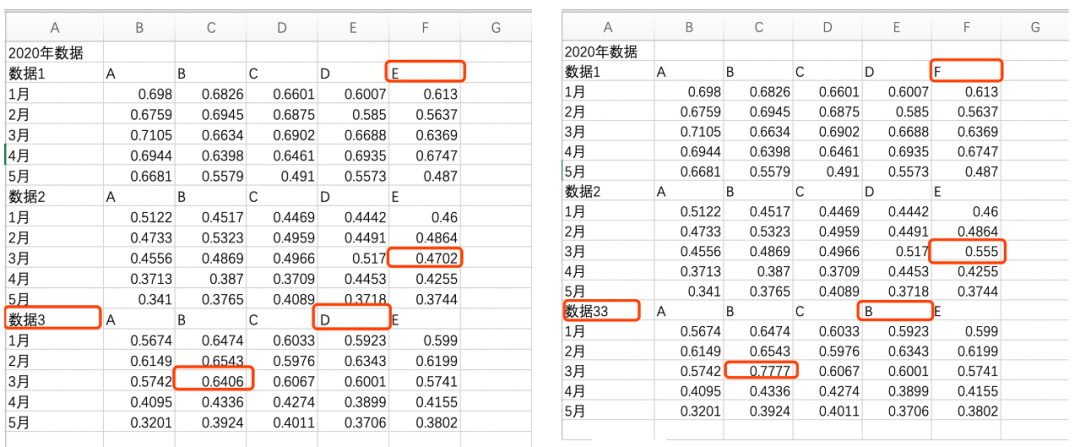
import pandas as pd
import numpy as np
df1 = pd.read_excel('data1.xlsx')
df2 = pd.read_excel('data2.xlsx')其实在Pandas中一行代码就能找到两个DataFrame的不同
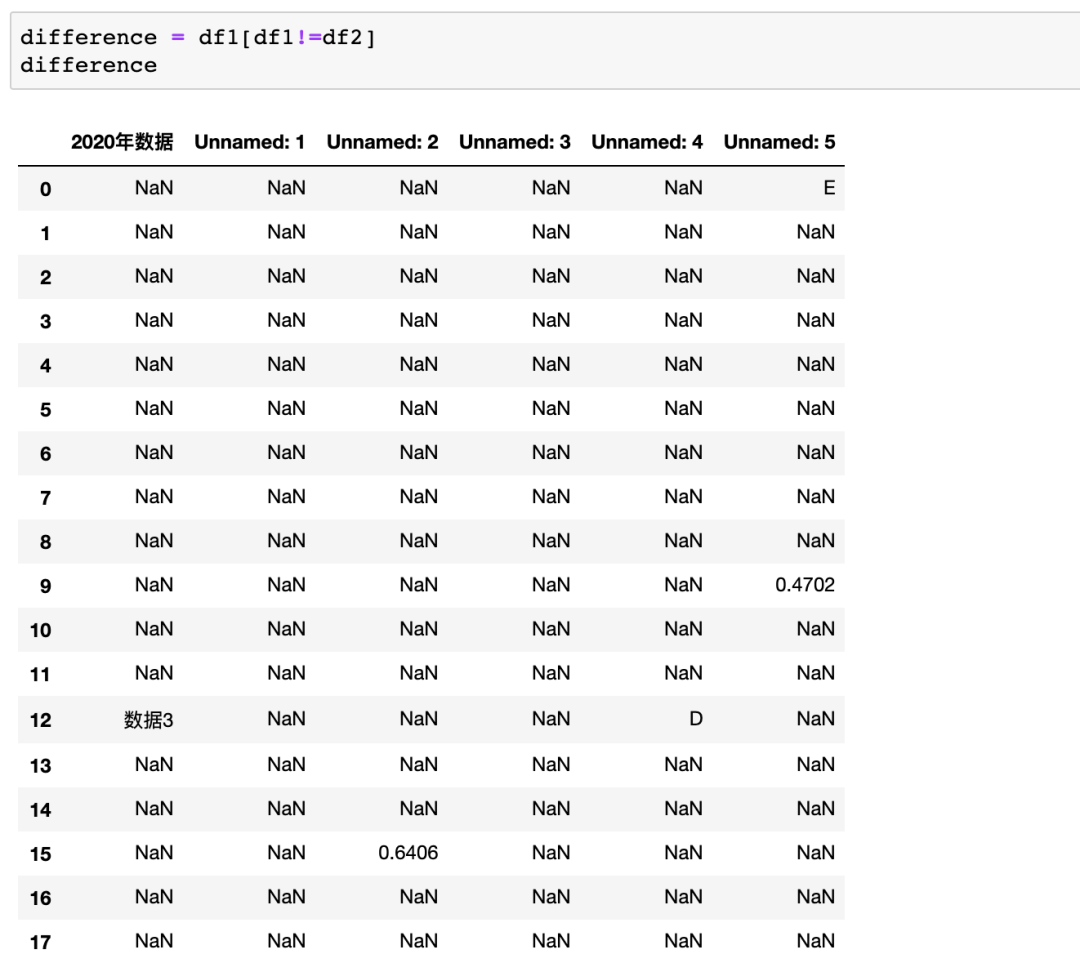
可以看到,如果一样的数据就是NaN,而变化的数据则以它的值存储,但是如果这么做的话,我们仅仅找到数据不同的位置,并且数据量大的话盯着找到不同也挺消耗时间的,所以我们进一步研究。先换一种方式找到不同的值
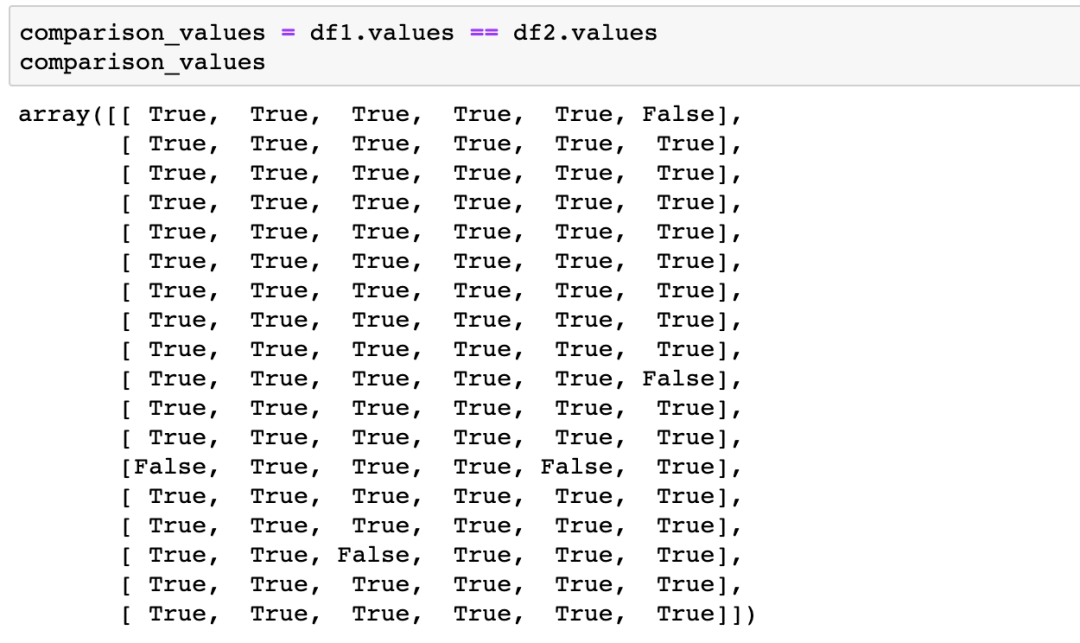
接着再使用NumPy根据True/False定位元素位置,同时将值的改变写入原表格并保存
rows,cols=np.where(comparison_values==False)
for item in zip(rows,cols):
df1.iloc[item[0], item[1]] = '{} --> {}'.format(df1.iloc[item[0], item[1]],df2.iloc[item[0], item[1]])
df1.to_excel('diff.xlsx',index=False,header=True)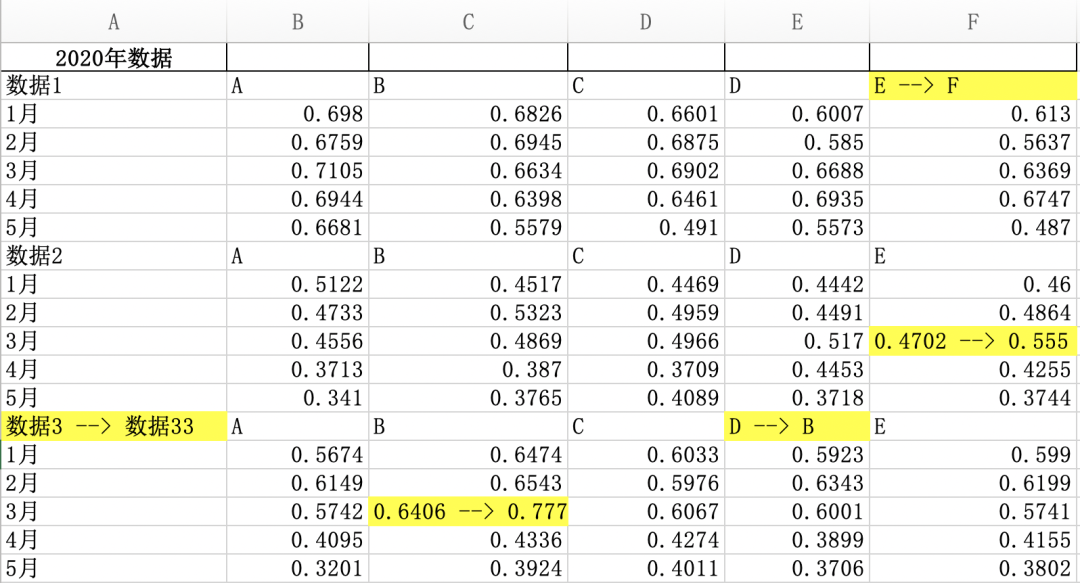
这样看起来就舒服了很多(高亮是手动的 ),当然在进行两个Excel比较的时候一定要注意这两个Excel的数据格式要差不多!
),当然在进行两个Excel比较的时候一定要注意这两个Excel的数据格式要差不多!
比较Word
两份Word比较起来相对于Excel就困难一点。首先我们还是创建两份有区别的Word文档,内容取自百度百科中的Python介绍[1]

左边的为原始word右边的word是我修改了几处的文档, 现在我们用Python来快速找到两份文档的不同。读取文件使用到的是docx库[2] ,因为涉及到中文所以我们需要先读取docx文件,然后分段再根据标点符号分句,具体代码如下
def getText(wordname):
'''
提取文字
'''
d = Document(wordname)
texts = []
for para in d.paragraphs:
texts.append(para.text)
return texts
def is_Chinese(word):
'''
识别中文
'''
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
def msplit(s, seperators = ',|\.|\?|,|。|?|!|、'):
'''
根据标点符号分句
'''
return re.split(seperators, s)
def readDocx(docfile):
'''
读取文档
'''
print(f"======正在读取{docfile}======")
paras = getText(docfile)
segs = []
for p in paras:
temp = []
for s in msplit(p):
if len(s) > 2:
temp.append(s.replace(' ', ""))
if len(temp) > 0:
segs.append(temp)
return segs
可以看到我们的word文件已经按照不同段落分好句存在两层list中,所以接下来的问题就转换为比较两个list,而这又是我们熟悉的👇
def comparsion(doc1,doc2,p,s):
if doc1 == doc2:
print('两个word完全一致')
else:
if doc1[p][s] != doc2[p][s]:
print(f"第{p+1}段,第{s+1}句不相同: {doc1[p][s]} ----> {doc2[p][s]}")上面的判断为最简单的形式:两个word中仅有文字改变,而段落、句子数量均没有改变,我们来试一下效果
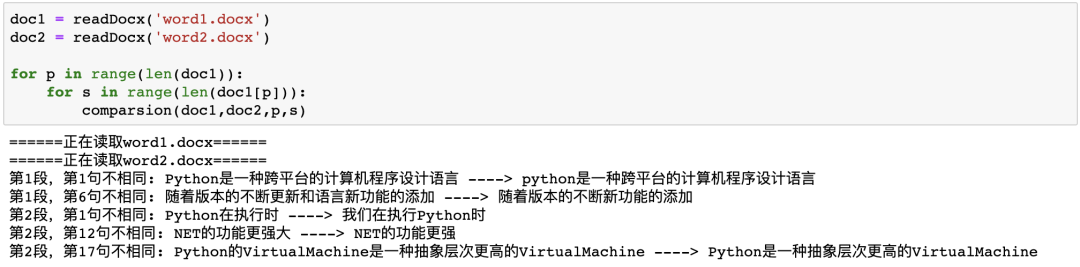
只要一秒,Python就找到了两份word文档之间的不同之处并定位!
结束语
通过介绍如何使用Python来对两个Excel/Word文件进行比较,我想你应该体会到了Python的强大之处,其实思路无非就是读取文件、定位之处并标记。但更重要的是你在日常工作学习时是否可以想到用Python去解决那些繁琐费力的流程,学会使用Python合理偷懒才是我写办公自动化系列的目的,拜拜,我们下个案例见~
注1: 本文使用的数据与源码可在后台回复0512获取
注2: 以上代码需在Python3环境下运行
如果喜欢Python自动化系列请点击在看并多多转发~
参考资料
百度百科: https://baike.baidu.com/item/Python/407313?fr=aladdin
[2]CSDN: https://blog.csdn.net/weixin_43145361/article/details/103798581
最后给大家分享我写的SQL两件套:《SQL基础知识第二版》和《SQL高级知识第二版》的PDF电子版。里面有各个语法的解释、大量的实例讲解和批注等等,非常通俗易懂,方便大家跟着一起来实操。
有需要的读者可以下载学习,在下面的公众号「数据前线」(非本号)后台回复关键字:SQL,就行
数据前线
后台回复关键字:1024,获取一份精心整理的技术干货
后台回复关键字:进群,带你进入高手如云的交流群
推荐阅读

