
【Python办公自动化】50多个Excel数据的对比查询
前言
最近公司在进行某项专项检查工作,要求各单位(公司近60个单位)自查后按要求报表过来,然后将收到的50多张Excel与之前的供应商信息表进行比对查询。一估算,有超过上万行的数据,靠人力去查找不知道猴年马月才能完成,一时没人能搞定,结果我接到了这个令人头痛的电话,领导最终把这个苦差事落到了我的头上,咱也不敢拒绝,毕竟领导掌握着我的生杀大权,只求领导记得月底给我加个鸡腿。
需求分析
这个问题,主要体现在数据量比较庞大,其实处理起来没那么复杂,还好最近跟蚂蚁老师学习了Pandas的一些知识,这里推荐一下,蚂蚁老师的课真的是纯干货,课程讲解都是以实用为主。经过一番思考,已经有了一个大概的思路:
处理各单位的报表、汇总 处理供应商信息表 查找结果。
分步实现
1.处理各单位的报表、汇总
先看一下收到的汇总表: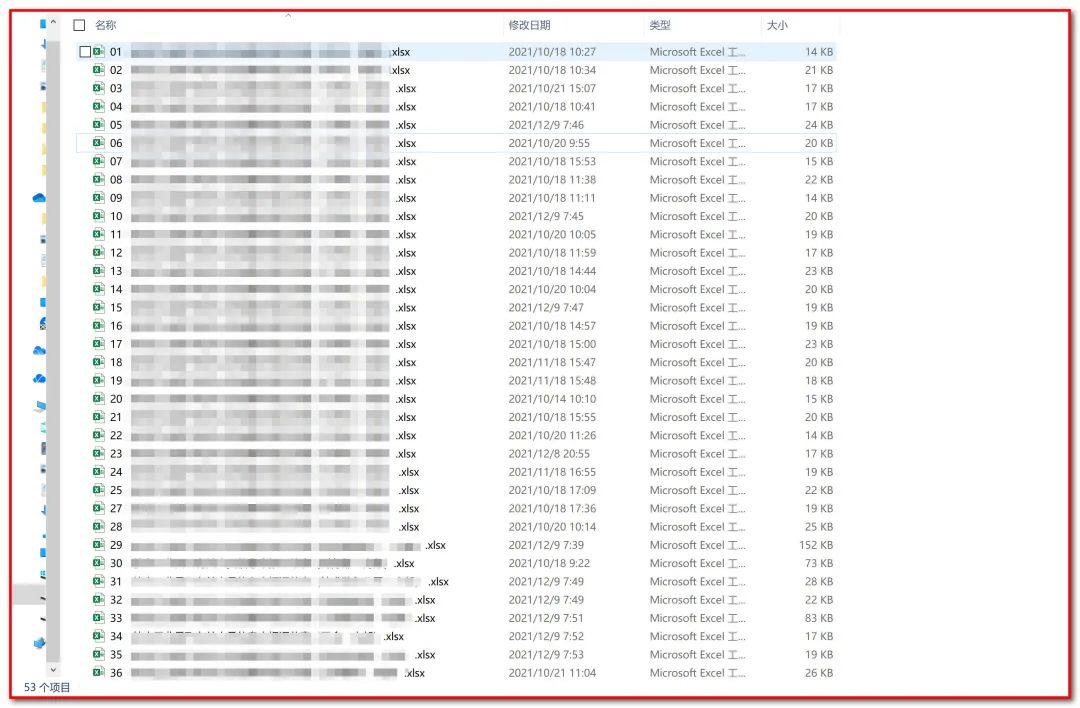
一共53张,这里只截取了一部分,这里要感谢Y老师细心的将每个Excel命名格式给统一了。然后全部打开,检查格式,补全内容,寻找规律。
import os
import xlwings as xw
app = xw.App(visible=True, add_book=False)
path = "./原始文件"
fnames = os.listdir(path)
for fname in fnames[32:]:
fpath = path+"/"+fname
app.books.open(fpath)
虽然之前工作开展的时候,有固定的模板,但是做过相应工作的人都知道,总有人会改动模板。快速的过了一遍,所幸这次改动的没几个人,少量的补全后,开始观察规律。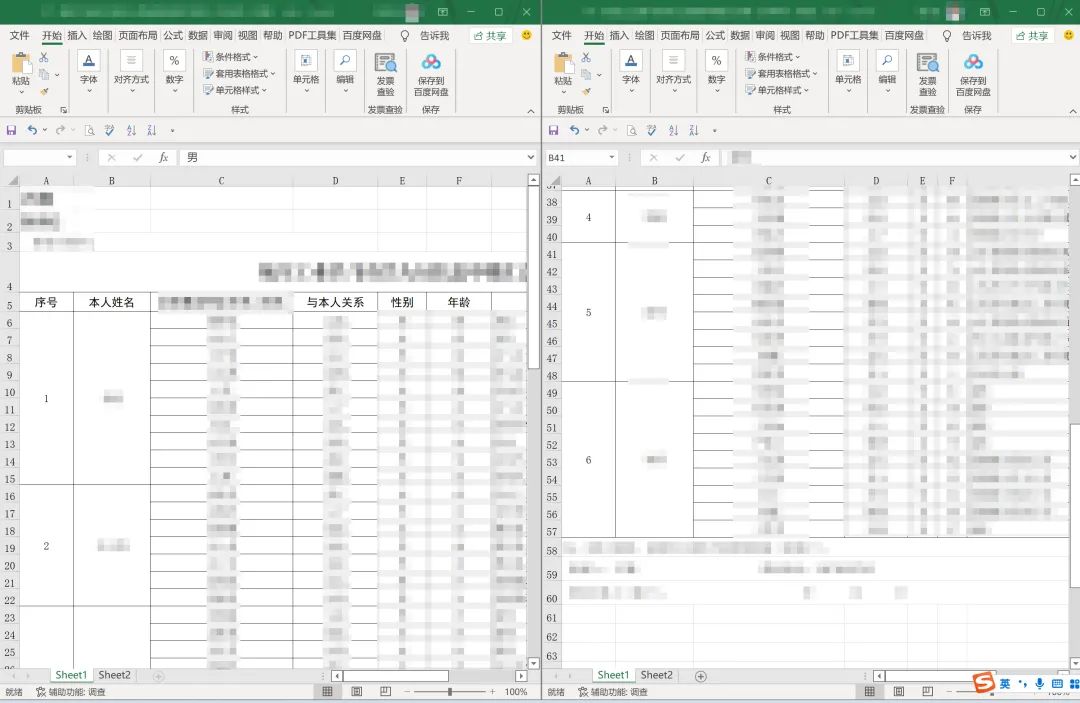
通过观察发现:每个表的前面4行和后面3行是不需要的信息,这里已经有了第一步的思路,读取每一个Excel,忽略前4行,遍历index,取出最后3行删掉,再合并所有的Dataframe,代码实现:
def get_collect(self):
'''
第一步:整理各单位报表,数据清洗,形成汇总表
:return: Dataframe
'''
fnames = os.listdir(self.path_1)
data_list = []
for fname in fnames:
#*是需要替换的内容
new_fnamne = fname.replace("**************(","")[2:-9]
fpath = self.path_1 +"/"+fname
print(fpath)
df = pd.read_excel(fpath,skiprows=4,sheet_name="Sheet1") #打开文件,忽略前四行
del_row_list = [i for i in df.index][-3:] #遍历索引,列表取值取出最后三个
df.drop([j for j in del_row_list],inplace=True) #删除最后三行
df.drop("序号",axis=1,inplace=True) #删除序号列
df.loc[:,"本人姓名"] = df["本人姓名"].fillna(method="ffill") #向下填充
df.loc[:,"填报单位"] = new_fnamne #新增列
data_list.append(df)
df_all = pd.concat(data_list,ignore_index=True)
df_all.to_excel("汇总表.xlsx")
return df_all
没有问题,开着手处理第二步
2.处理供应商信息表
有了第一步的良好开端,我们照例还是先打开表格观察规律: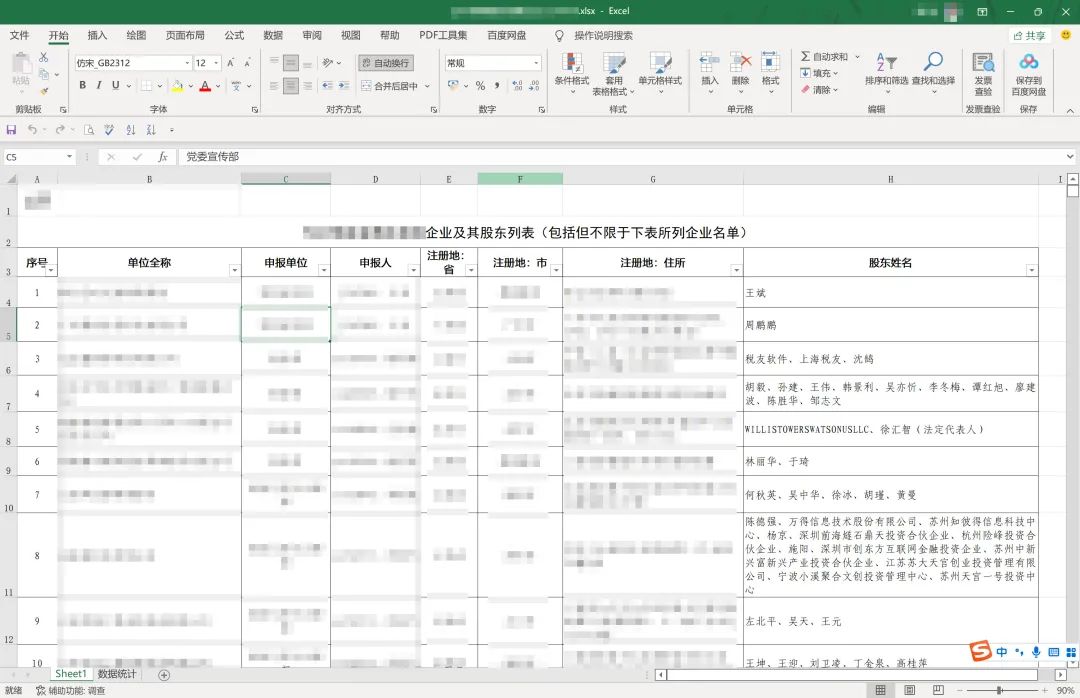
观察发现:前面2行和其他列都是正常的,唯独“股东姓名”列是一行多人,而且是用“、”隔开的,这里暂时没有学到,开始万能的百度,“pandas一行变多行”,最终处理如下:
def get_proexcel(self):
'''
第二步:清洗供应商信息表,一行变多行
:return:Dataframe
'''
fnames = os.listdir(self.path_2)
for fname in fnames:
if len(fnames) != 0:
fpath = self.path_2+"/"+fname
df = pd.read_excel(fpath,skiprows=2,sheet_name="Sheet1") #打开文件,忽略前两行
df.loc[:, "股东姓名"] = df["股东姓名"].map(lambda x: x.split("、")) #将股东姓名按“、”拆分
df_new = df.explode("股东姓名") #一行变多行
df_new.to_excel("整理后供应商表.xlsx", index=False)
# print(df_new)
return df_new
else:
pass
运行,没有问题,到这里基本上已经成功大半了,如果数据较少的话已经可以手动去对比了。但是咱既然选择了自动处理,那本着“能坐着绝不站着,能躺着绝不坐着”的先进思路,一定要进行第三步的。
3.查找结果
开始第三步merge两个Dataframe,形成最终的比对检查结果,形成最终汇总的Excel。
def get_merge(self):
'''
第三步:merge两个Dataframe
:return:
'''
#选择供应商表需要merge的列
df_sinfo = self.get_proexcel()[["单位全称", "申报单位", "申报人","注册地:省","注册地:市","注册地:住所","股东姓名"]]
#merge两个Dataframe
df_merge = pd.merge(left=self.get_collect(), right=df_sinfo, left_on="*******", right_on="股东姓名")
df_merge.to_excel("查询结果汇总.xlsx")
全部代码
import pandas as pd
import os
'''用pandas处理excel,上万行数据的查找,比对。
'''
class Dataexcel():
def __init__(self,path_1,path_2):
self.path_1 = path_1
self.path_2 = path_2
def get_collect(self):
'''
第一步:整理各单位报表,数据清洗,形成汇总表
:return: Dataframe
'''
fnames = os.listdir(self.path_1)
data_list = []
for fname in fnames:
#*是需要替换的内容
new_fnamne = fname.replace("********(","")[2:-9]
fpath = self.path_1 +"/"+fname
print(fpath)
df = pd.read_excel(fpath,skiprows=4,sheet_name="Sheet1") #打开文件,忽略前四行
del_row_list = [i for i in df.index][-3:] #遍历索引,列表取值取出最后三个
df.drop([j for j in del_row_list],inplace=True) #删除最后三行
df.drop("序号",axis=1,inplace=True) #删除序号列
df.loc[:,"本人姓名"] = df["本人姓名"].fillna(method="ffill") #向下填充
df.loc[:,"填报单位"] = new_fnamne #新增列
data_list.append(df)
df_all = pd.concat(data_list,ignore_index=True)
df_all.to_excel("汇总表.xlsx")
return df_all
def get_proexcel(self):
'''
第二步:清洗供应商信息表,一行变多行
:return:Dataframe
'''
fnames = os.listdir(self.path_2)
for fname in fnames:
if len(fnames) != 0:
fpath = self.path_2+"/"+fname
df = pd.read_excel(fpath,skiprows=2,sheet_name="Sheet1") #打开文件,忽略前两行
df.loc[:, "股东姓名"] = df["股东姓名"].map(lambda x: x.split("、")) #将股东姓名按“、”拆分
df_new = df.explode("股东姓名") #一行变多行
df_new.to_excel("整理后供应商表.xlsx", index=False)
# print(df_new)
return df_new
else:
pass
def get_merge(self):
'''
第三步:merge两个Dataframe
:return:
'''
#选择供应商表需要merge的列
df_sinfo = self.get_proexcel()[["单位全称", "申报单位", "申报人","注册地:省","注册地:市","注册地:住所","股东姓名"]]
#merge两个Dataframe
df_merge = pd.merge(left=self.get_collect(), right=df_sinfo, left_on="*******", right_on="股东姓名")
df_merge.to_excel("查询结果汇总.xlsx")
if __name__ == '__main__':
dataexcel = Dataexcel("./原始文件","./客商汇总")
dataexcel.get_merge()
最终结果
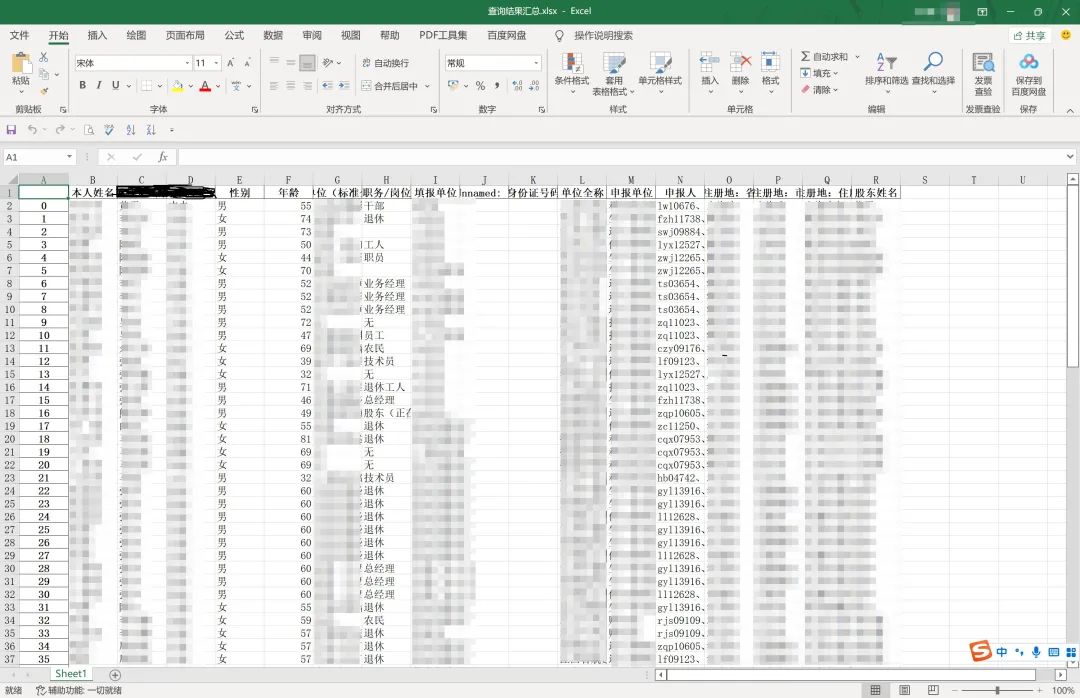
写在最后
其实这次是的代码已经是2.0版了,之前用xlrd处理过一版,数据出来有误,而且读取相当的不方便,还要再考虑写入问题。网上有人说用set,但是Excel,尤其是含有人名数据的时候,set会自动去重,结果会有误。后来学习了蚂蚁老师的pandas相关内容,还是pandas相当nice。
最后,推荐蚂蚁老师的《零基础入门到数据分析实战》课程,极其干货!还有蚂蚁老师的答疑服务(微信:ant_learn_python)
点击下方《阅读原文》可以到达课程页!