
Hive 实践 | 如何对Hive表小文件进行合并
HDFS不适合大量小文件的存储,因namenode将文件系统的元数据存放在内存中,因此存储的文件数目受限于 namenode的内存大小。HDFS中每个文件、目录、数据块占用150Bytes。如果存放的文件数目过多的话会占用很大的内存甚至撑爆内存。HDFS适用于高吞吐量,而不适合低时间延迟的访问。如果同时存入大量的小文件会花费很长的时间。本篇文章主要介绍在CDP7.1.6集群中如何对Hive表小文件进行合并。
测试环境
1.操作系统Redhat7.6
2.CDP7.1.6
3.使用root用户操作
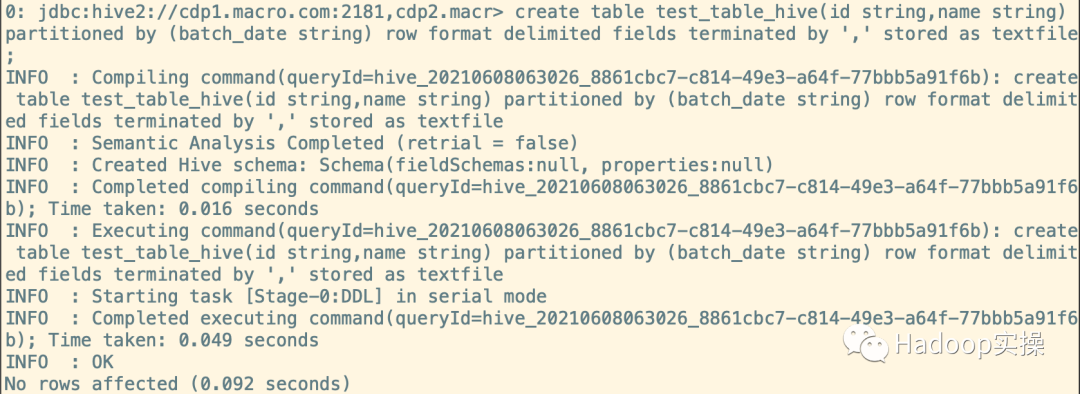
1.创建分区测试表
create table test_table_hive(id string,name string) partitioned by (batch_date string) row format delimited fields terminated by ',' stored as textfile;
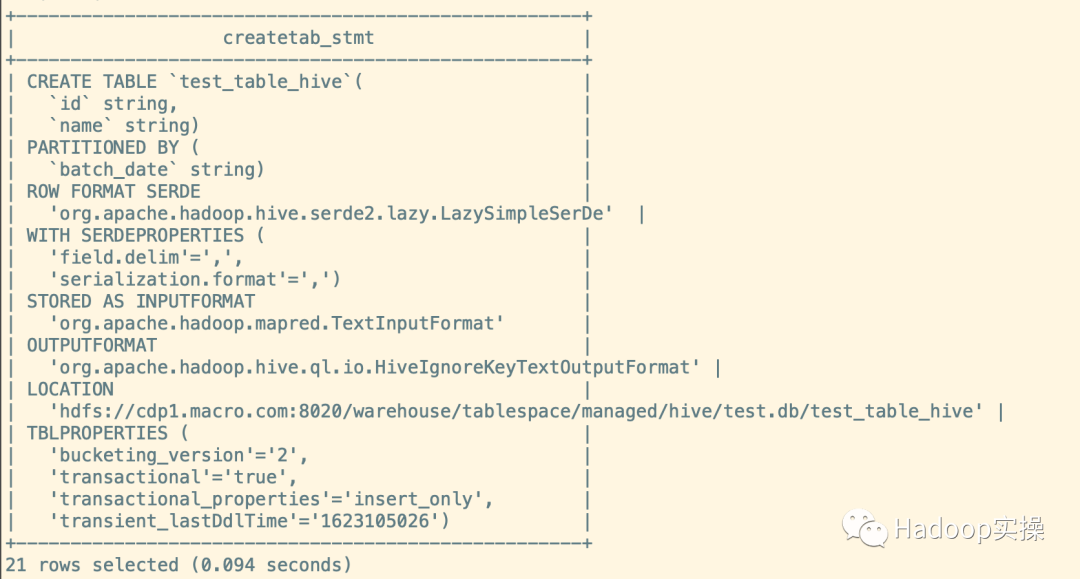
2.查看表结构
show create table test_table_hive;
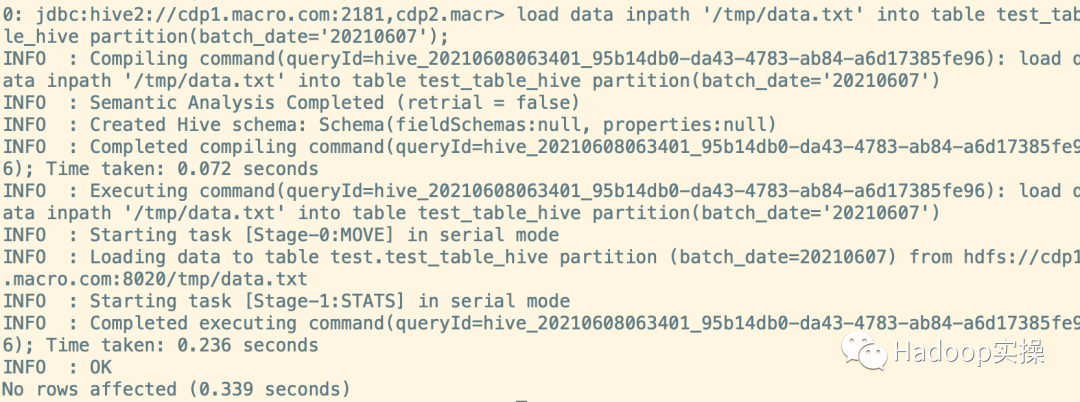
3.像表中导入数据,并创建分区。(为了让小文件数量和分区数达到合并效果,本文进行了多次导入)
load data inpath '/tmp/data.txt' into table test_table_hive partition(batch_date='20210607');
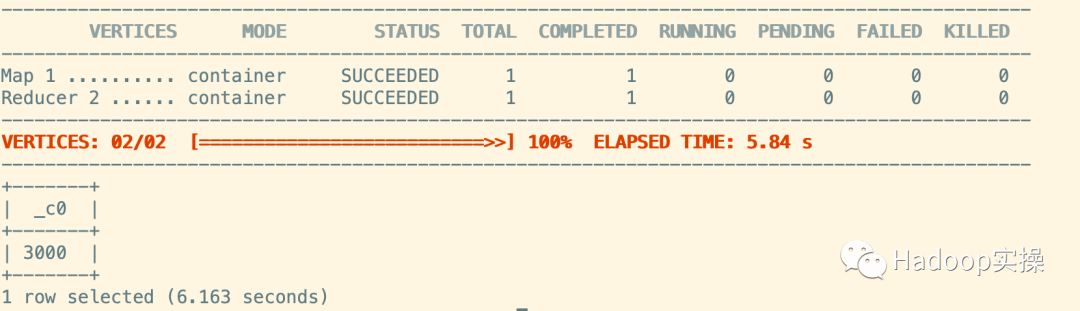
4.查看数据量
select count(*) from test_table_hive;
5.查看总分区数(可以看到共12个分区)
hdfs dfs -ls /warehouse/tablespace/managed/hive/test.db/test_table_hive/
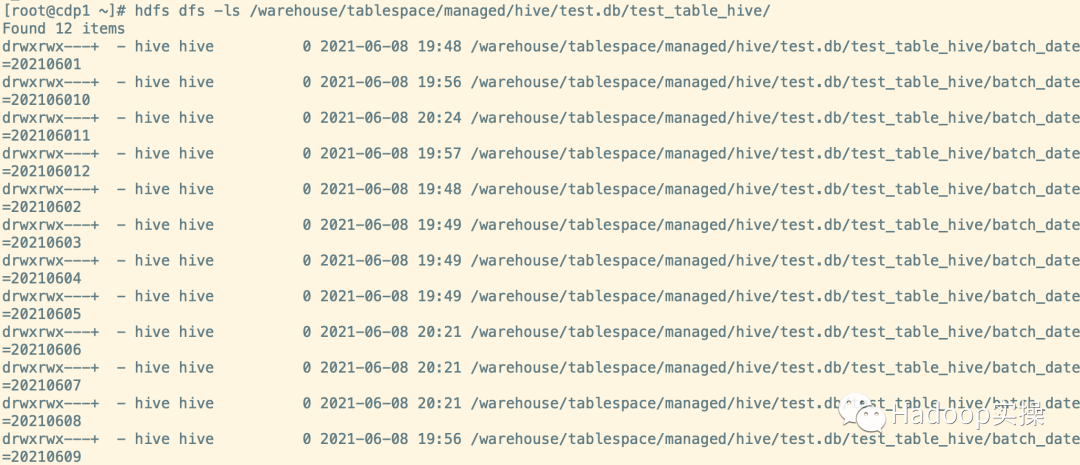
6.总的小文件数量,和batch_date=20210608分区的文件数量
hdfs dfs -count /warehouse/tablespace/managed/hive/test.db/test_table_hive
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive/batch_date=20210608|wc -l
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive/batch_date=20210608
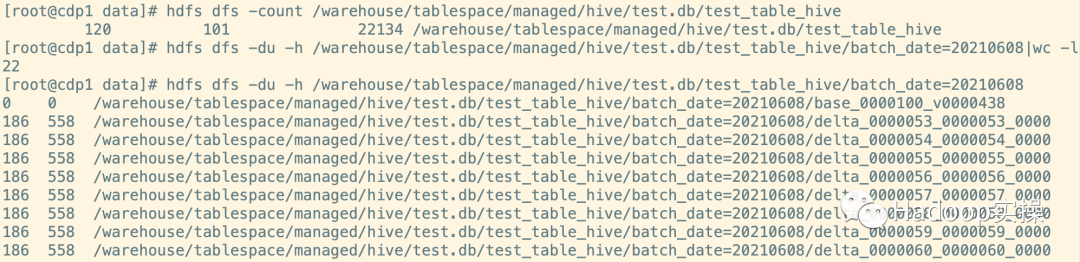
1.创建临时表(创建临时表时需和原表的表结构一致)
create table test.test_table_hive_merge like test.test_table_hive;
2.设置合并文件相关会话参数(参数概述见总结部分)
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=3000;
SET hive.exec.max.dynamic.partitions.pernode=500;
SET hive.merge.tezfiles=true;
SET hive.merge.smallfiles.avgsize=128000000;
SET hive.merge.size.per.task=128000000;
3.合并文件至临时表中
INSERT OVERWRITE TABLE test.test_table_hive_merge partition(batch_date) SELECT * FROM test.test_table_hive;
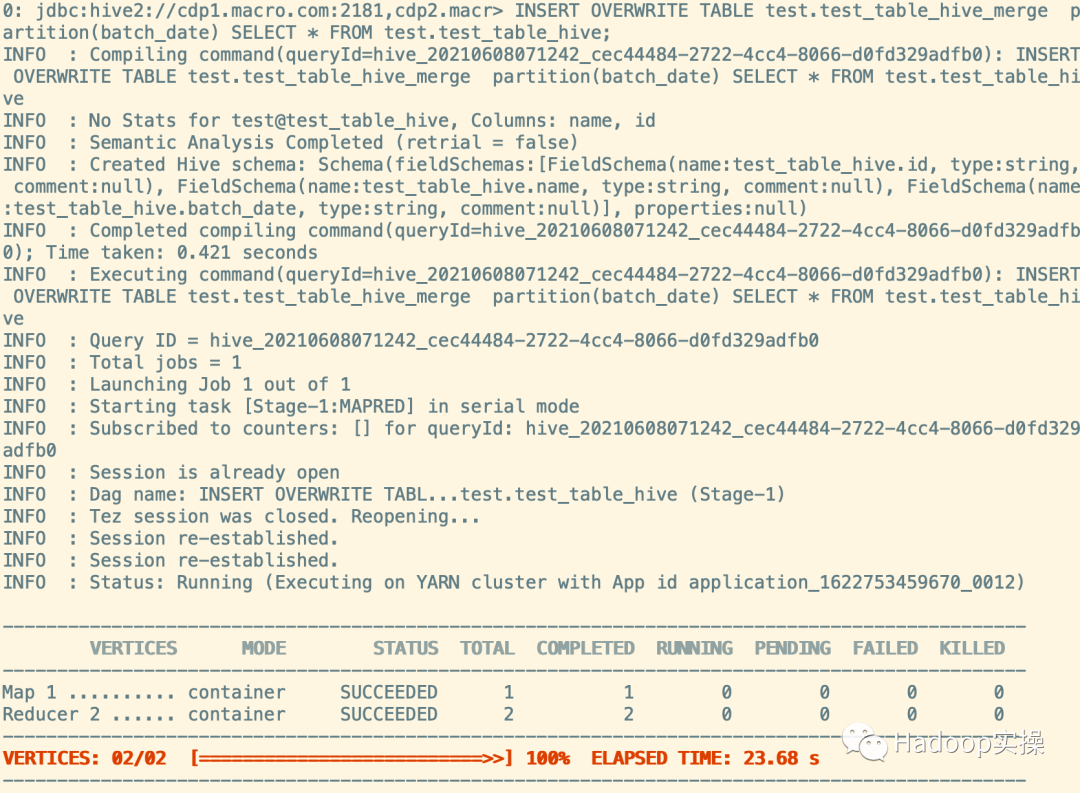
4.查看原表和临时表数据量
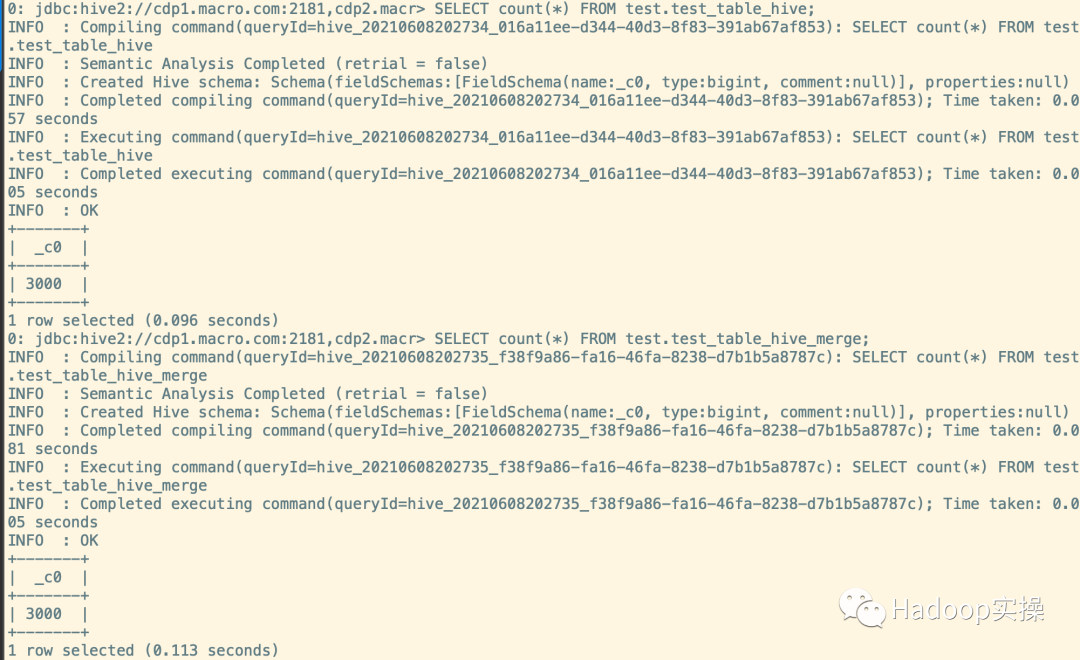
SELECT count(*) FROM test.test_table_hive;
SELECT count(*) FROM test.test_table_hive_merge;
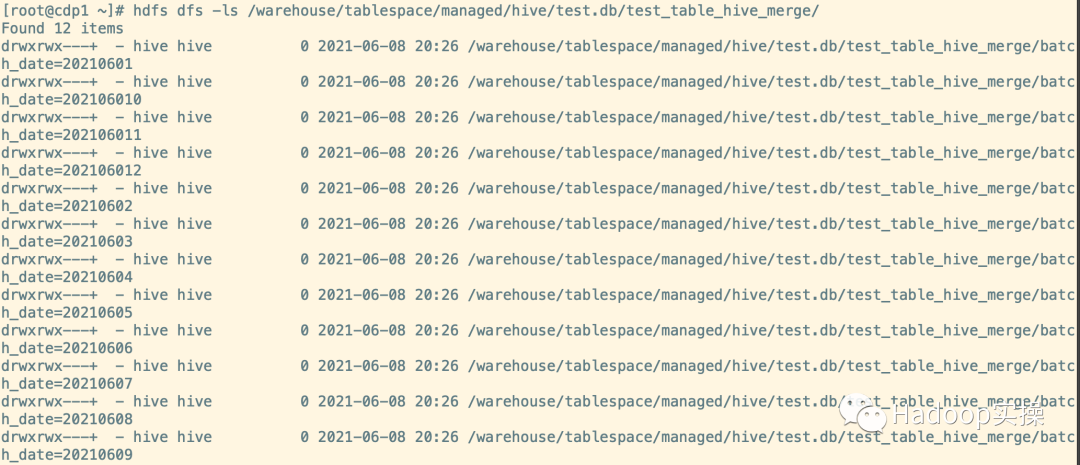
5.查看总分区数
hdfs dfs -ls /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/
6.查看合并后的分区数和小文件数量
hdfs dfs -count /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/batch_date=20210608
hdfs dfs -du -h /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/batch_date=20210608|wc -l

如上图101个文件数合并为12个,共12个分区,每个分区下的文件被合并为了一个
1.创建备份目录,把原表数据放入备份目录,并迁移临时表数据到原表。
hdfs dfs -mkdir -p /tmp/hive/test_table_hive_data_backups
hdfs dfs -mv /warehouse/tablespace/managed/hive/test.db/test_table_hive/* /tmp/hive/test_table_hive_data_backups/
hdfs dfs -cp -f /warehouse/tablespace/managed/hive/test.db/test_table_hive_merge/* /warehouse/tablespace/managed/hive/test.db/test_table_hive/

2.查看合并后的原表小文件数量
hdfs dfs -count -v -h /warehouse/tablespace/managed/hive/test.db/test_table_hive

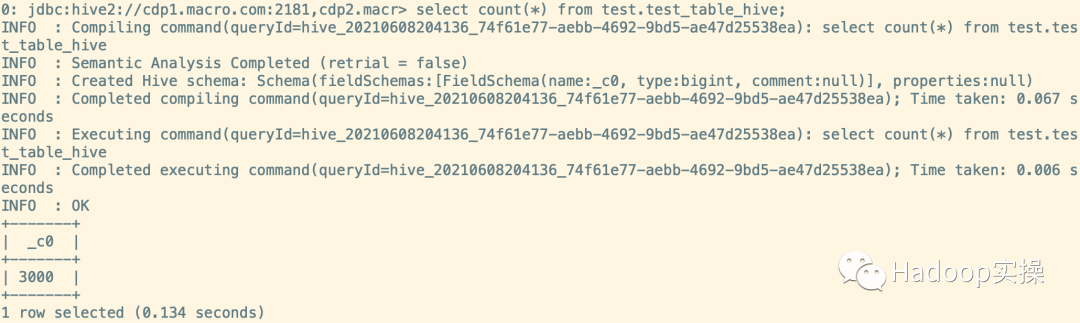
3.查看合并后的原表数据
select count(*) from test_table_hive;
4.清理临时表
drop table test.test_table_hive_merge;
5.清理备份数据(确认合并后数据无异常后清理,建议数据保留一周)
hdfs dfs -rm -r /tmp/hive/test_table_hive_data_backups

1.本文原表中共12个分区,101个小文件,合并后共12个文件,其每个分区中一个。
2.在CDP中因为Hive的底层执行引擎是TEZ,,所以相比CDH需要修改以前的合并参数“SET hive.merge.mapfiles=true”为“SET hive.merge.tezfiles=true;”。
3.合并完后清理原表备份的数据建议保留一周。
4.参数含义
SET hive.exec.dynamic.partition=true;
#使用动态分区
SET hive.exec.dynamic.partition.mode=nonstrict;
#默认值为srticat,nonstrict模式表示允许所有分区字段都可以使用动态分区
SET hive.exec.max.dynamic.partitions=3000;
#在所有执行MR的节点上,共可以创建多少个动态分区
SET hive.exec.max.dynamic.partitions.pernode=500;
#在执行MR的单节点上,最大可以创建多少个分区
SET hive.merge.tezfiles=true;
#tez任务结束时合并小文件
SET hive.merge.smallfiles.avgsize=1280000000;
#当输出文件平均大小小于该值时。启用独立的TEZ任务进行文件合并
SET hive.merge.size.per.task=1280000000;
#合并文件大小128M