
Hive基于UDF进行文本分词
本文大纲
UDF 简介
Hive作为一个sql查询引擎,自带了一些基本的函数,比如count(计数),sum(求和),有时候这些基本函数满足不了我们的需求,这时候就要写hive hdf(user defined funation),又叫用户自定义函数。编写Hive UDF的步骤:
添加相关依赖,创建项目,这里我用的管理工具是maven,所以我创建的也是一个maven 项目(这个时候你需要选择合适的依赖版本,主要是Hadoop 和 Hive,可以使用
hadoop version和hive --version来分别查看版本)继承
org.apache.hadoop.hive.ql.exec.UDF类,实现evaluate方法,然后打包;使用
add方法添加jar 包到分布式缓存,如果jar包是上传到$HIVE_HOME/lib/目录以下,就不需要执行add命令了;通过
create temporary function创建临时函数,不加temporary就创建了一个永久函数;在SQL 中使用你创建的UDF;
UDF分词
这个是一个比较常见的场景,例如公司的产品有每天都会产生大量的弹幕或者评论,这个时候我们可能会想去分析一下大家最关心的热点话题是什么,或者是我们会分析最近一段时间的网络趋势是什么,但是这里有一个问题就是你的词库建设的问题,因为你使用通用的词库可能不能达到很好的分词效果,尤其有很多网络流行用语它是不在词库里的,还有一个就是停用词的问题了,因为很多时候停用词是没有意义的,所以这里我们需要将其过滤,而过滤的方式就是通过停用词词表进行过滤。
这个时候我们的解决方案主要有两种,一种是使用第三方提供的一些词库,还有一种是自建词库,然后有专人去维护,这个也是比较常见的一种情况。
最后一个就是我们使用的分词工具,因为目前主流的分词器很多,选择不同的分词工具可能对我们的分词结果有很多影响。
分词工具
1:Elasticsearch的开源中文分词器 IK Analysis(Star:2471)
IK中文分词器在Elasticsearch上的使用。原生IK中文分词是从文件系统中读取词典,es-ik本身可扩展成从不同的源读取词典。目前提供从sqlite3数据库中读取。es-ik-plugin-sqlite3使用方法:1. 在elasticsearch.yml中设置你的sqlite3词典的位置:ik_analysis_db_path: /opt/ik/dictionary.db
2:开源的java中文分词库 IKAnalyzer(Star:343)
IK Analyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目
3:java开源中文分词 Ansj(Star:3019)
Ansj中文分词 这是一个ictclas的java实现.基本上重写了所有的数据结构和算法.词典是用的开源版的ictclas所提供的.并且进行了部分的人工优化 分词速度达到每秒钟大约200万字左右,准确率能达到96%以上。
目前实现了.中文分词. 中文姓名识别 . 词性标注、用户自定义词典,关键字提取,自动摘要,关键字标记等功能。
可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目.
4:结巴分词 ElasticSearch 插件(Star:188)
elasticsearch官方只提供smartcn这个中文分词插件,效果不是很好,好在国内有medcl大神(国内最早研究es的人之一)写的两个中文分词插件,一个是ik的,一个是mmseg的
5:Java分布式中文分词组件 - word分词(Star:672)
word分词是一个Java实现的分布式的中文分词组件,提供了多种基于词典的分词算法,并利用ngram模型来消除歧义。能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词
6:Java开源中文分词器jcseg(Star:400)
Jcseg是什么?Jcseg是基于mmseg算法的一个轻量级开源中文分词器,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了最新版本的lucene, solr, elasticsearch的分词接口, Jcseg自带了一个 jcseg.properties文件…
7:中文分词库Paoding
庖丁中文分词库是一个使用Java开发的,可结合到Lucene应用中的,为互联网、企业内部网使用的中文搜索引擎分词组件。Paoding填补了国内中文分词方面开源组件的空白,致力于此并希翼成为互联网网站首选的中文分词开源组件。Paoding中文分词追求分词的高效率和用户良好体验。
8:中文分词器mmseg4j
mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法(http://technology.chtsai.org/mmseg/ )实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使…
9:中文分词Ansj(Star:3015)
Ansj中文分词 这是一个ictclas的java实现.基本上重写了所有的数据结构和算法.词典是用的开源版的ictclas所提供的.并且进行了部分的人工优化 内存中中文分词每秒钟大约100万字(速度上已经超越ictclas) 文件读取分词每秒钟大约30万字 准确率能达到96%以上 目前实现了….
10:Lucene中文分词库ICTCLAS4J
ictclas4j中文分词系统是sinboy在中科院张华平和刘群老师的研制的FreeICTCLAS的基础上完成的一个java开源分词项目,简化了原分词程序的复杂度,旨在为广大的中文分词爱好者一个更好的学习机会。
代码实现
第一步:引入依赖
这里我们引入了两个依赖,其实是两个不同分词工具
org.ansj
ansj_seg
5.1.6
compile
com.janeluo
ikanalyzer
2012_u6
在开始之前我们先写一个demo 玩玩,让大家有个基本的认识
@Test
public void testAnsjSeg() {
String str = "我叫李太白,我是一个诗人,我生活在唐朝" ;
// 选择使用哪种分词器 BaseAnalysis ToAnalysis NlpAnalysis IndexAnalysis
Result result = ToAnalysis.parse(str);
System.out.println(result);
KeyWordComputer kwc = new KeyWordComputer(5);
Collection keywords = kwc.computeArticleTfidf(str);
System.out.println(keywords);
}
输出结果
我/r,叫/v,李太白/nr,,/w,我/r,是/v,一个/m,诗人/n,,/w,我/r,生活/vn,在/p,唐朝/t
[李太白/24.72276098504223, 诗人/3.0502185968368885, 唐朝/0.8965677022546215, 生活/0.6892230219652541]
第二步:引入停用词词库
因为是停用词词库,本身也不是很大,所以我直接放在项目里了,当然你也可以放在其他地方,例如HDFS 上
第三步:编写UDF
代码很简单我就不不做详细解释了,需要注意的是GenericUDF 里面的一些方法的使用规则,至于代码设计的好坏以及还有什么改进的方案我们后面再说,下面两套实现的思路几乎是一致的,不一样的是在使用的分词工具上的不一样
ansj的实现
/**
* Chinese words segmentation with user-dict in com.kingcall.dic
* use Ansj(a java open source analyzer)
*/
// 这个信息就是你每次使用desc 进行获取函数信息的时候返回的
@Description(name = "ansj_seg", value = "_FUNC_(str) - chinese words segment using ansj. Return list of words.",
extended = "Example: select _FUNC_('我是测试字符串') from src limit 1;\n"
+ "[\"我\", \"是\", \"测试\", \"字符串\"]")
public class AnsjSeg extends GenericUDF {
private transient ObjectInspectorConverters.Converter[] converters;
private static final String userDic = "/app/stopwords/com.kingcall.dic";
//load userDic in hdfs
static {
try {
FileSystem fs = FileSystem.get(new Configuration());
FSDataInputStream in = fs.open(new Path(userDic));
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String line = null;
String[] strs = null;
while ((line = br.readLine()) != null) {
line = line.trim();
if (line.length() > 0) {
strs = line.split("\t");
strs[0] = strs[0].toLowerCase();
DicLibrary.insert(DicLibrary.DEFAULT, strs[0]); //ignore nature and freq
}
}
MyStaticValue.isNameRecognition = Boolean.FALSE;
MyStaticValue.isQuantifierRecognition = Boolean.TRUE;
} catch (Exception e) {
System.out.println("Error when load userDic" + e.getMessage());
}
}
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length < 1 || arguments.length > 2) {
throw new UDFArgumentLengthException(
"The function AnsjSeg(str) takes 1 or 2 arguments.");
}
converters = new ObjectInspectorConverters.Converter[arguments.length];
converters[0] = ObjectInspectorConverters.getConverter(arguments[0], PrimitiveObjectInspectorFactory.writableStringObjectInspector);
if (2 == arguments.length) {
converters[1] = ObjectInspectorConverters.getConverter(arguments[1], PrimitiveObjectInspectorFactory.writableIntObjectInspector);
}
return ObjectInspectorFactory.getStandardListObjectInspector(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
boolean filterStop = false;
if (arguments[0].get() == null) {
return null;
}
if (2 == arguments.length) {
IntWritable filterParam = (IntWritable) converters[1].convert(arguments[1].get());
if (1 == filterParam.get()) filterStop = true;
}
Text s = (Text) converters[0].convert(arguments[0].get());
ArrayList result = new ArrayList<>();
if (filterStop) {
for (Term words : DicAnalysis.parse(s.toString()).recognition(StopLibrary.get())) {
if (words.getName().trim().length() > 0) {
result.add(new Text(words.getName().trim()));
}
}
} else {
for (Term words : DicAnalysis.parse(s.toString())) {
if (words.getName().trim().length() > 0) {
result.add(new Text(words.getName().trim()));
}
}
}
return result;
}
@Override
public String getDisplayString(String[] children) {
return getStandardDisplayString("ansj_seg", children);
}
}
ikanalyzer的实现
@Description(name = "ansj_seg", value = "_FUNC_(str) - chinese words segment using Iknalyzer. Return list of words.",
extended = "Example: select _FUNC_('我是测试字符串') from src limit 1;\n"
+ "[\"我\", \"是\", \"测试\", \"字符串\"]")
public class IknalyzerSeg extends GenericUDF {
private transient ObjectInspectorConverters.Converter[] converters;
//用来存放停用词的集合
Set stopWordSet = new HashSet();
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length < 1 || arguments.length > 2) {
throw new UDFArgumentLengthException(
"The function AnsjSeg(str) takes 1 or 2 arguments.");
}
//读入停用词文件
BufferedReader StopWordFileBr = null;
try {
StopWordFileBr = new BufferedReader(new InputStreamReader(new FileInputStream(new File("stopwords/baidu_stopwords.txt"))));
//初如化停用词集
String stopWord = null;
for(; (stopWord = StopWordFileBr.readLine()) != null;){
stopWordSet.add(stopWord);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
converters = new ObjectInspectorConverters.Converter[arguments.length];
converters[0] = ObjectInspectorConverters.getConverter(arguments[0], PrimitiveObjectInspectorFactory.writableStringObjectInspector);
if (2 == arguments.length) {
converters[1] = ObjectInspectorConverters.getConverter(arguments[1], PrimitiveObjectInspectorFactory.writableIntObjectInspector);
}
return ObjectInspectorFactory.getStandardListObjectInspector(PrimitiveObjectInspectorFactory.writableStringObjectInspector);
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
boolean filterStop = false;
if (arguments[0].get() == null) {
return null;
}
if (2 == arguments.length) {
IntWritable filterParam = (IntWritable) converters[1].convert(arguments[1].get());
if (1 == filterParam.get()) filterStop = true;
}
Text s = (Text) converters[0].convert(arguments[0].get());
StringReader reader = new StringReader(s.toString());
IKSegmenter iks = new IKSegmenter(reader, true);
List list = new ArrayList<>();
if (filterStop) {
try {
Lexeme lexeme;
while ((lexeme = iks.next()) != null) {
if (!stopWordSet.contains(lexeme.getLexemeText())) {
list.add(new Text(lexeme.getLexemeText()));
}
}
} catch (IOException e) {
}
} else {
try {
Lexeme lexeme;
while ((lexeme = iks.next()) != null) {
list.add(new Text(lexeme.getLexemeText()));
}
} catch (IOException e) {
}
}
return list;
}
@Override
public String getDisplayString(String[] children) {
return "Usage: evaluate(String str)";
}
}
第四步:编写测试用例
GenericUDF 给我们提供了一些方法,这些方法可以用来构建测试需要的环境和参数,这样我们就可以测试这些代码了
@Test
public void testAnsjSegFunc() throws HiveException {
AnsjSeg udf = new AnsjSeg();
ObjectInspector valueOI0 = PrimitiveObjectInspectorFactory.javaStringObjectInspector;
ObjectInspector valueOI1 = PrimitiveObjectInspectorFactory.javaIntObjectInspector;
ObjectInspector[] init_args = {valueOI0, valueOI1};
udf.initialize(init_args);
Text str = new Text("我是测试字符串");
GenericUDF.DeferredObject valueObj0 = new GenericUDF.DeferredJavaObject(str);
GenericUDF.DeferredObject valueObj1 = new GenericUDF.DeferredJavaObject(0);
GenericUDF.DeferredObject[] args = {valueObj0, valueObj1};
ArrayList我们看到加载停用词没有找到,但是整体还是跑起来了,因为读取不到HDFS 上的文件

但是我们第二个样例是不需要从HDFS 上加载停用词信息,所以可以完美的测试运行

注 后来为了能在外部更新文件,我将其放在了HDFS 上,和AnsjSeg 中的代码一样
第五步:创建UDF 并使用
add jar /Users/liuwenqiang/workspace/code/idea/HiveUDF/target/HiveUDF-0.0.4.jar;
create temporary function ansjSeg as 'com.kingcall.bigdata.HiveUDF.AnsjSeg';
select ansjSeg("我是字符串,你是啥");
-- 开启停用词过滤
select ansjSeg("我是字符串,你是啥",1);
create temporary function ikSeg as 'com.kingcall.bigdata.HiveUDF.IknalyzerSeg';
select ikSeg("我是字符串,你是啥");
select ikSeg("我是字符串,你是啥",1);

上面方法的第二个参数,就是是否开启停用词过滤,我们使用ikSeg函数演示一下
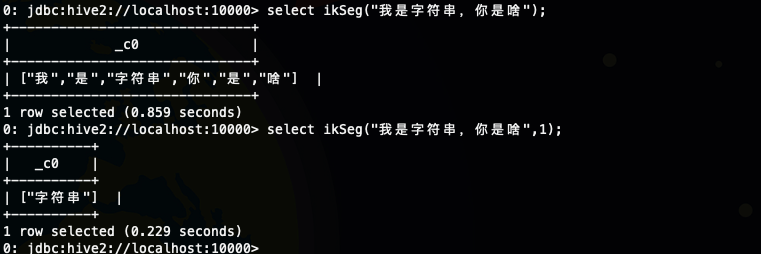
下面我们尝试获取一下函数的描述信息
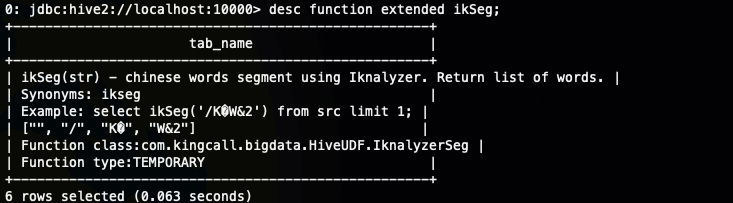
如果没有写的话,就是下面的这样的
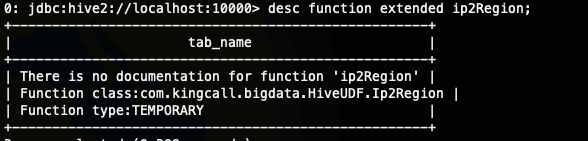
其它应用场景
通过编写Hive UDF可以轻松帮我们实现大量常见需求,其它应该场景还有:
ip地址转地区:将上报的用户日志中的ip字段转化为国家-省-市格式,便于做地域分布统计分析;使用
Hive SQL计算的标签数据,不想编写Spark程序,可以通过UDF在静态代码块中初始化连接池,利用Hive启动的并行MR任务,并行快速导入大量数据到codis中,应用于一些推荐业务;还有其它
sql实现相对复杂的任务,都可以编写永久Hive UDF进行转化;
总结
这一节我们学习了一个比较常见的UDF,通过实现
GenericUDF抽象类来实现,这一节的重点在于代码的实现以及对GenericUDF类中方法的理解上面的代码实现上有一个问题,那就是关于停用词的加载,就是我们能不能动态加载停用词呢?