
No Bugs!谁反对?
大家好,我是3y
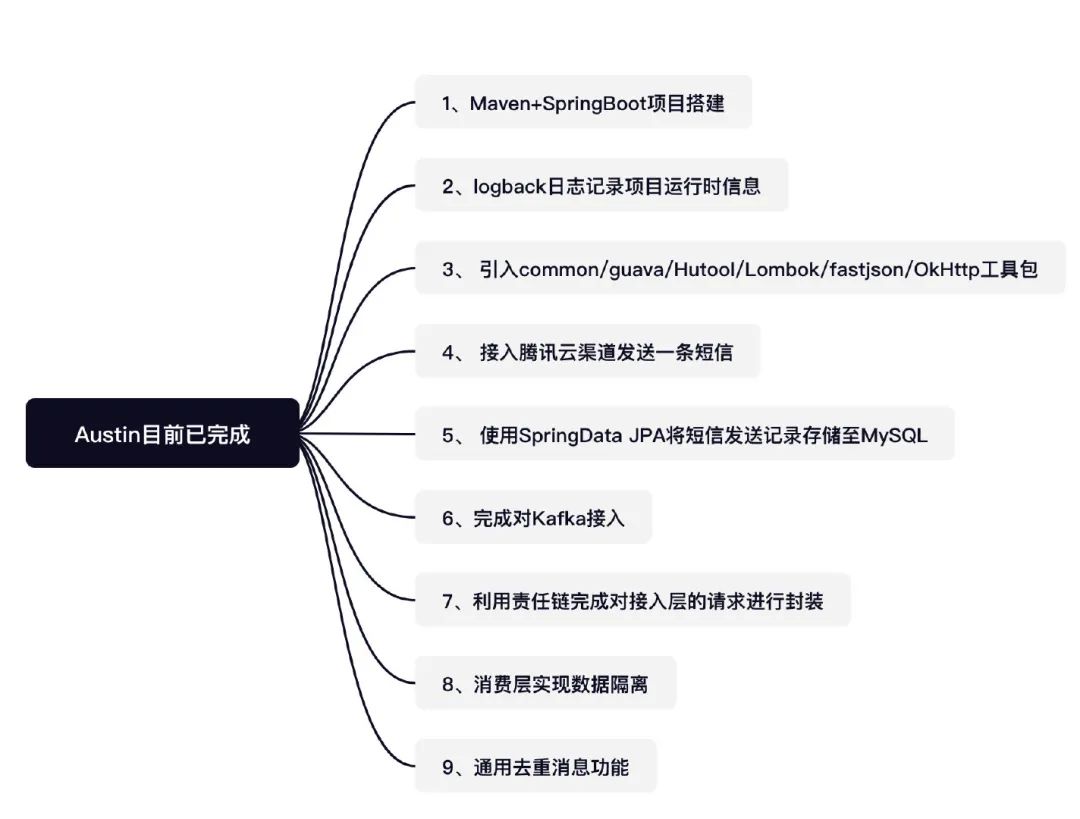
今天继续更新austin项目,如果还没看过该系列的同学可以点开我的历史文章回顾下,在看的过程中不要忘记了点赞哟!建议不要漏了或者跳着看,不然这篇就看不懂了,之前写过的知识点和业务我就不再赘述啦。
今天要实现的是handler消费消息后,实现平台性去重的功能。
01、什么是去重和幂等
这个话题我之前在《对线面试官》系列就已经分享过了,这块面试也会经常问到,可以再跟大家一起复习下
「幂等」和「去重」的本质:「唯一Key」+「存储」
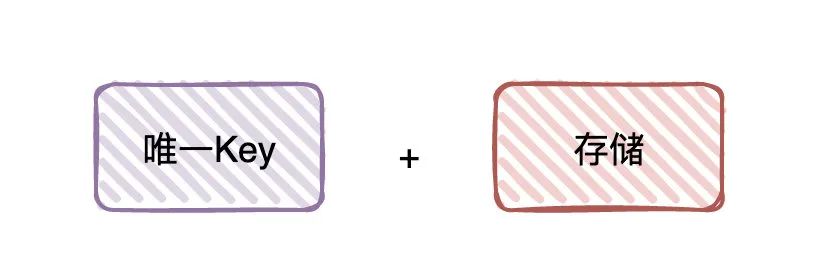
唯一Key如何构建以及选择用什么存储,都是业务决定的。「本地缓存」如果业务合适,可以作为「前置」筛选出一部分,把其他存储作为「后置」,用这种模式来提高性能。

今日要聊的Redis,它拥有着高性能读写,前置筛选和后置判断均可,austin项目的去重功能就是依赖着Redis而实现的。
02、安装Redis
先快速过一遍Redis的使用姿势吧(如果对此不感兴趣的可以直接跳到05讲解相关的业务和代码设计)
安装Redis的环境跟上次Kafka是一样的,为了方便我就继续用docker-compose的方式来进行啦。
环境:
CentOS 7.6 64bit
首先,我们新建一个文件夹redis,然后在该目录下创建出data文件夹、redis.conf文件和docker-compose.yaml文件

redis.conf文件的内容如下(后面的配置可在这更改,比如requirepass 我指定的密码为austin)
protected-mode no
port 6379
timeout 0
save 900 1
save 300 10
save 60 10000
rdbcompression yes
dbfilename dump.rdb
dir /data
appendonly yes
appendfsync everysec
requirepass austin
docker-compose.yaml的文件内容如下:
version: '3'
services:
redis:
image: redis:latest
container_name: redis
restart: always
ports:
- 6379:6379
volumes:
- ./redis.conf:/usr/local/etc/redis/redis.conf:rw
- ./data:/data:rw
command:
/bin/bash -c "redis-server /usr/local/etc/redis/redis.conf "
配置的工作就完了,如果是云服务器,记得开redis端口6379
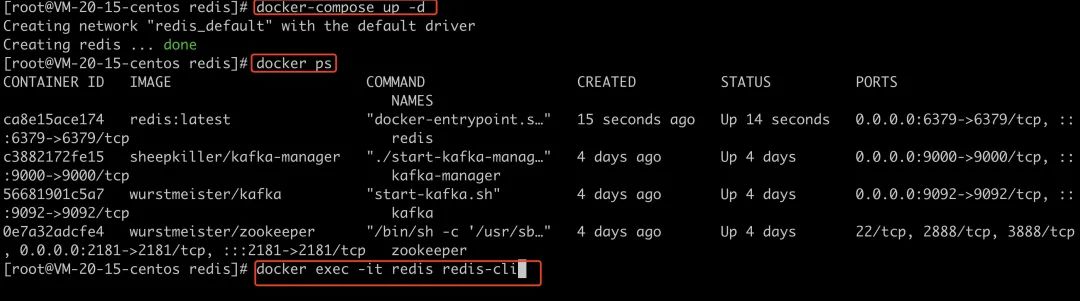
03、启动Redis
启动Redis跟之前安装Kafka的时候就差不多啦
docker-compose up -d
docker ps
docker exec -it redis redis-cli
进入redis客户端了之后,我们想看验证下是否正常。(在正式输入命令之前,我们需要通过密码校验,在配置文件下配置的密码是austin)
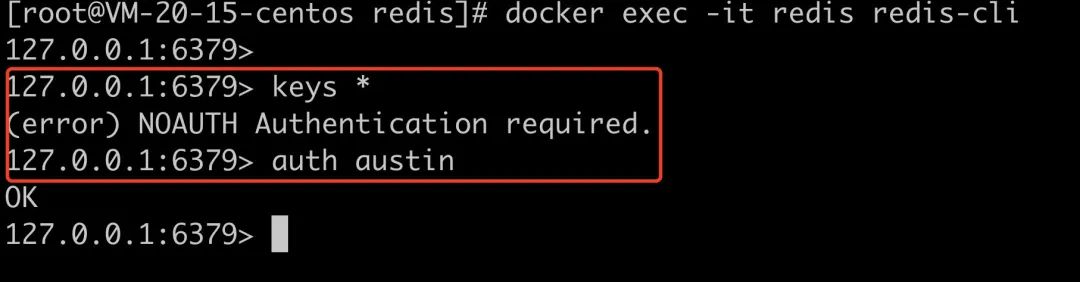
然后随意看看命令是不是正常就OK啦
04、Java中使用Redis
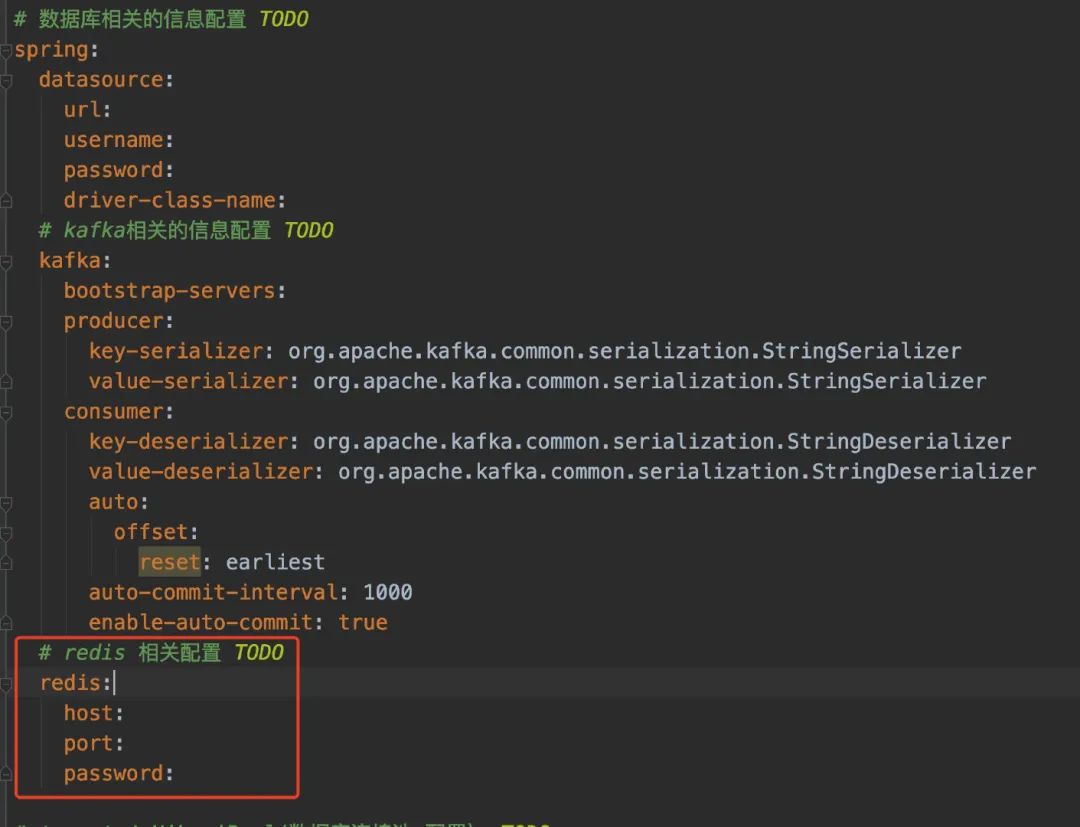
在SpringBoot环境下,使用Redis就非常简单了(再次体现出使用SpringBoot的好处)。我们只需要在pom文件下引入对应的依赖,并且在配置文件下配置host/port和password就搞掂了。

对于客户端,我们就直接使用RedisTemplate就好了,它是对客户端的高度封装,已经挺好使的了。
05、去重功能业务
任何的功能代码实现都离不开业务场景,在聊代码实现之前,先聊业务!平时在做需求的时候,我也一直信奉着:先搞懂业务要做什么,再实现功能。
去重该功能在austin项目里我是把它定位是:平台性功能。要理解这点很重要!不要想着把业务的各种的去重逻辑都在平台上做,这是不合理的。
这里只能把共性的去重功能给做掉,跟业务强挂钩应由业务方自行实现。所以,我目前在这里实现的是:
5分钟内相同用户如果收到相同的内容,则应该被过滤掉。实现理由:很有可能由于MQ重复消费又或是业务方不谨慎调用,导致相同的消息在短时间内被austin消费,进而发送给用户。有了该去重,我们可以可以在一定程序下减少事故的发生。 一天内相同的用户如果已经收到某渠道内容5次,则应该被过滤掉。实现理由:在运营或者业务推送下,有可能某些用户在一天内会多次收到推送消息。避免对用户带来过多的打扰,从总体定下规则一天内用户只能收到N条消息。
不排除随着业务的发展,还有些需要我们去做的去重功能,但还是要记住,我们这里不跟业务强挂钩。

当我们的核心功能依赖其他中间件的时候,我们尽可能避免由于中间件的异常导致我们核心的功能无法正常使用。比如,redis如果挂了,也不应该影响我们正常消息的下发,它只能影响到去重的功能。

06、去重功能代码总览
在之前,我们已经从Kafka拉取消息后,然后把消息放到各自的线程池进行处理了,去重的功能我们只需要在发送之前就好了。
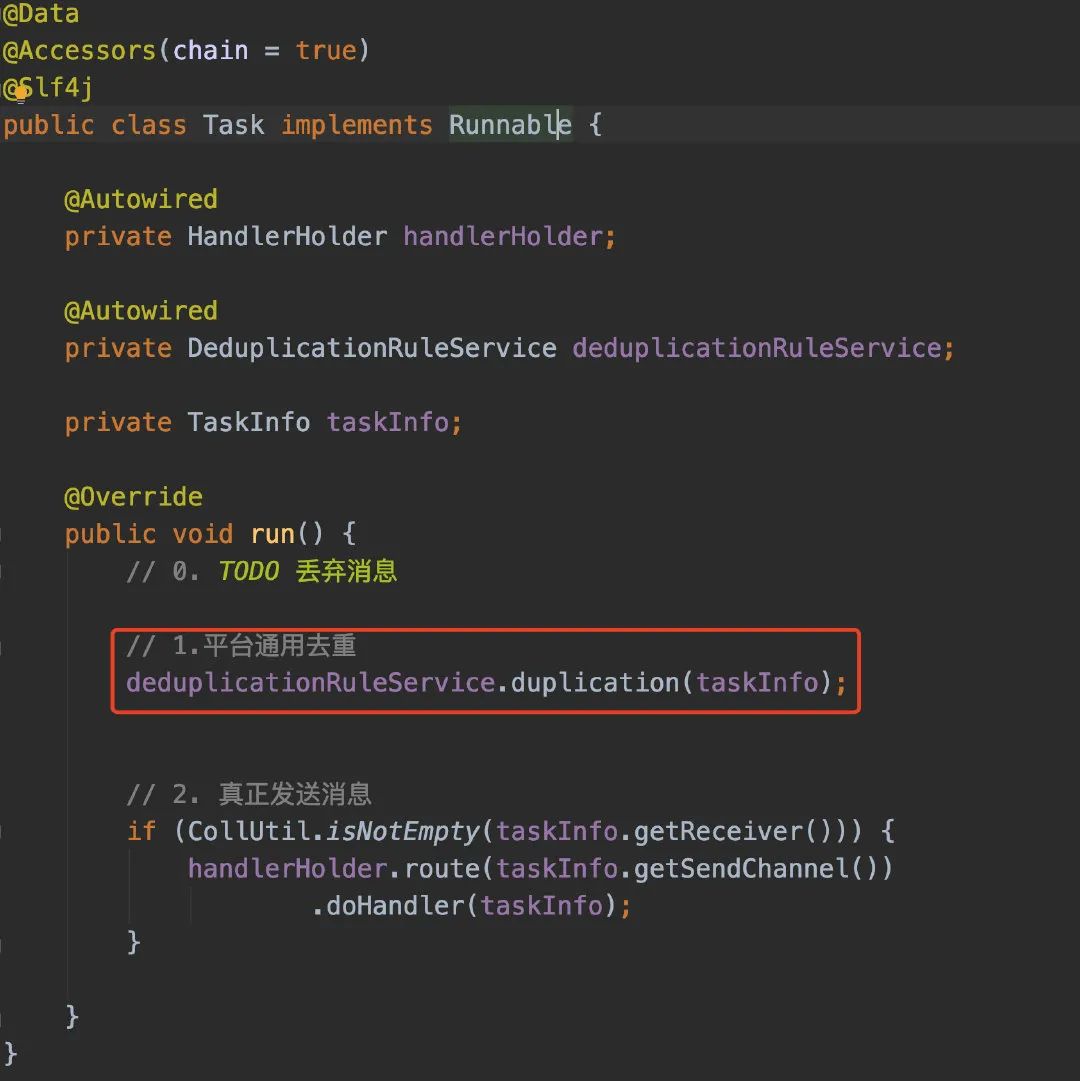
我将去重的逻辑统一抽象为:在X时间段内达到了Y阈值。去重实现的步骤可以简单分为:
从Redis获取记录 判断Redis存在的记录是否符合条件 符合条件的则去重,不符合条件的则重新塞进Redis
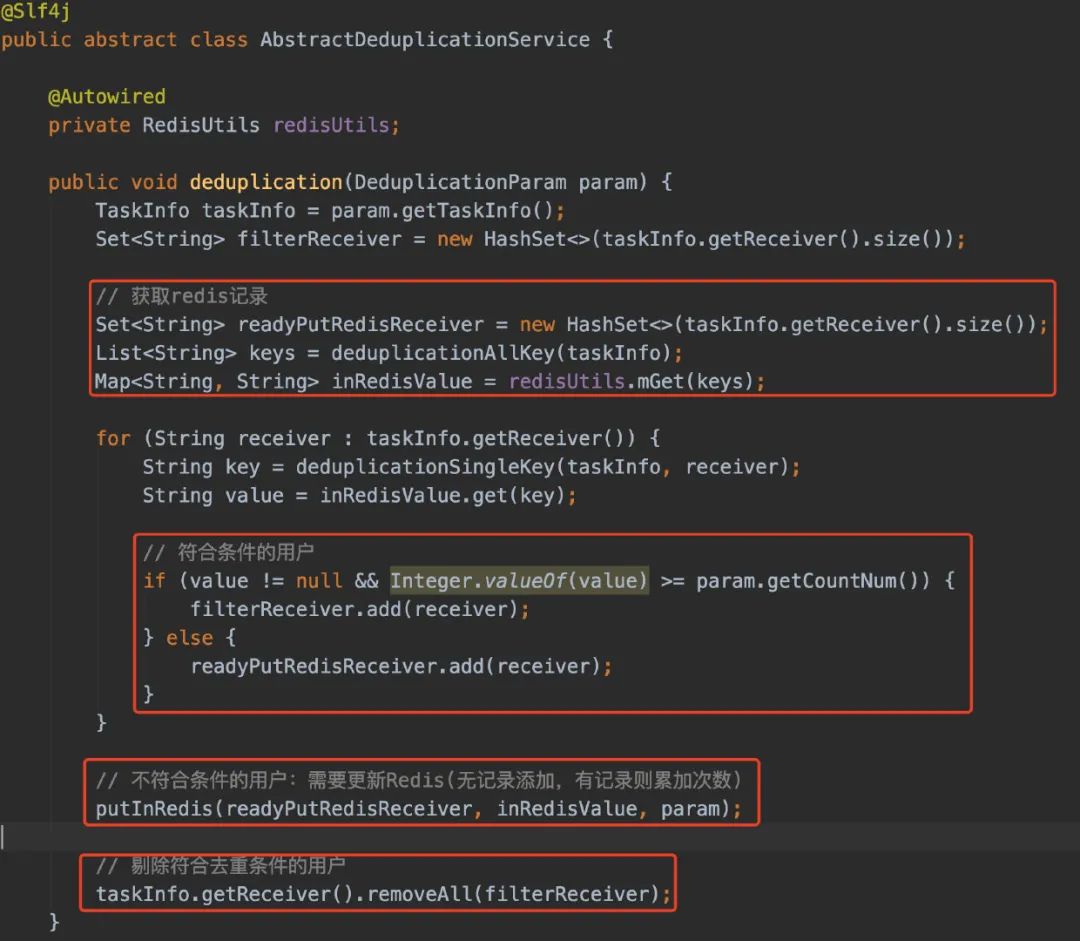
这里我使用的是模板方法模式,deduplication方法已经定义好了定位,当有新的去重逻辑需要接入的时候,只需要继承AbstractDeduplicationService来实现deduplicationSingleKey方法即可。
比如,我以相同内容发送给同一个用户的去重逻辑为例:
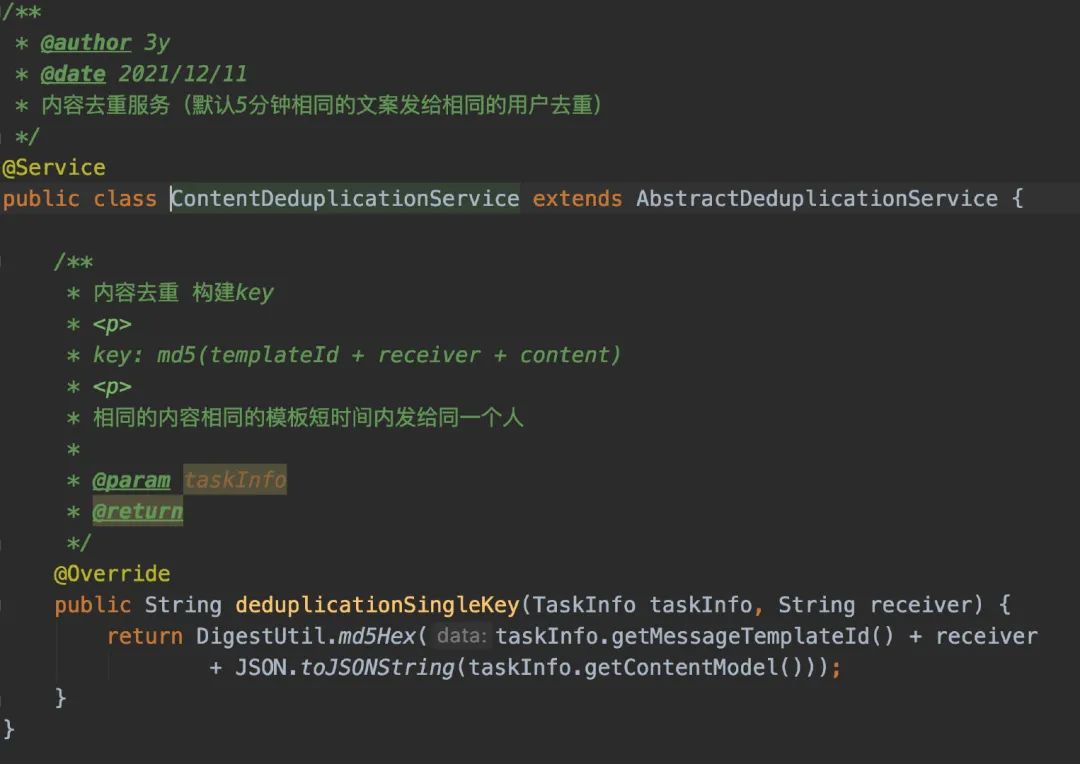
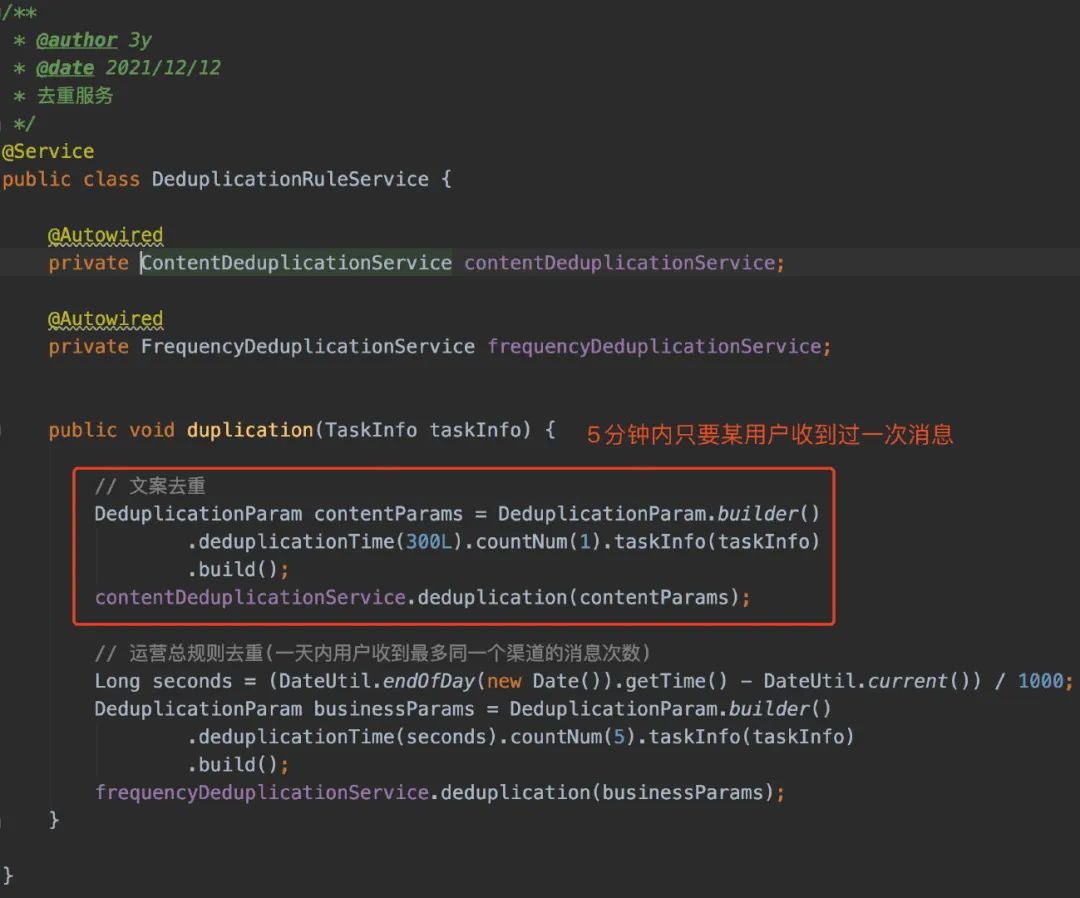
07、去重代码具体实现
在这场景下,我使用Redis都是用批量操作来减少请求Redis的次数的,这对于我们这种业务场景(在消费的时候需要大量请求Redis,使用批量操作提升还是很大的)
由于我觉得使用的场景还是蛮多的,所以我封装了个RedisUtils工具类,并且可以发现的是:我对操作Redis的地方都用try catch来包住。即便是Redis出了故障,我的核心业务也不会受到影响。
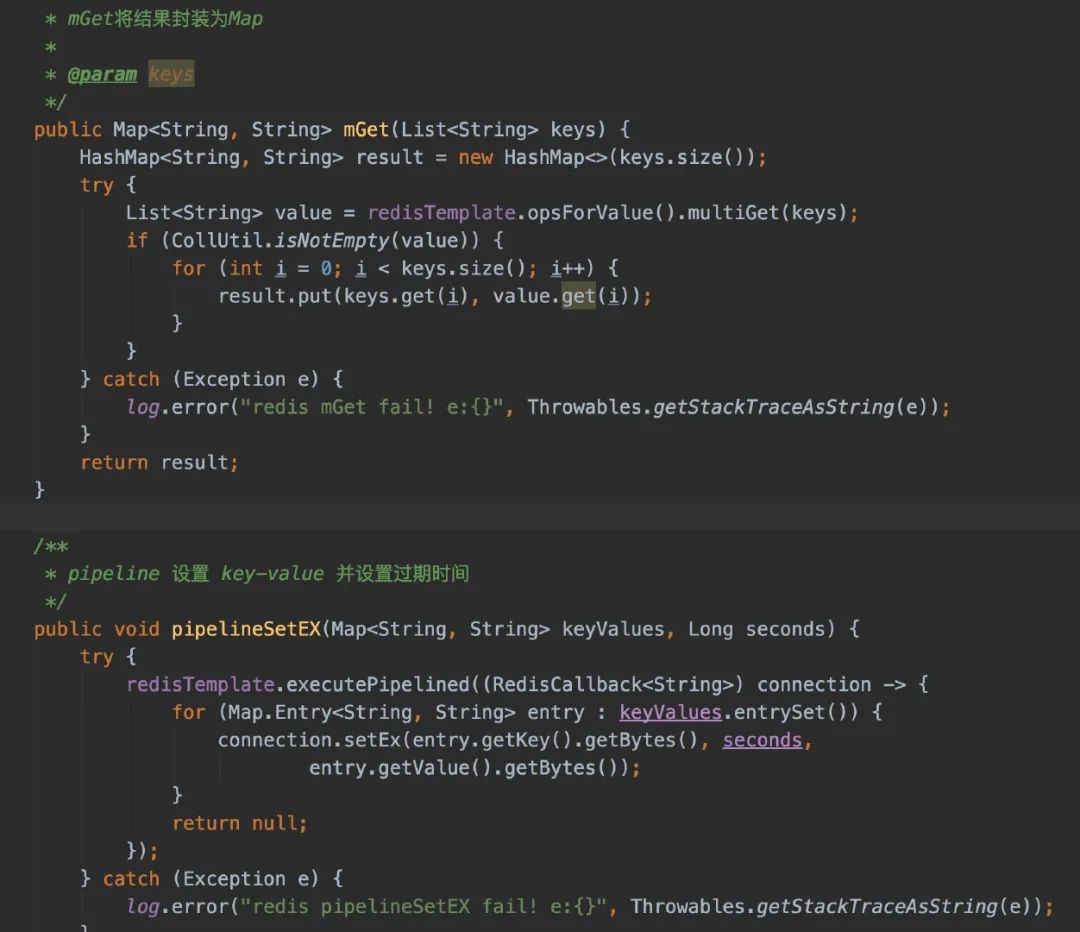
08、你的代码有Bug!
不知道看完上面的代码你们有没有看出问题,有喜欢点赞的帅逼就很直接看出两个问题:
你的去重功能为什么是在发送消息之前就做了?万一你发送消息失败了怎么办? 你的去重功能存在并发的问题吧?假设我有两条一样的消息,消费的线程有多个,然后该两条线程同时查询Redis,发现都不在Redis内,那这不就有并发的问题吗
没错,上面这两个问题都是存在的。但是,我这边都不会去解决。
先来看第一个问题:

对于这个问题,我能扯出的理由有两个:
假设我发送消息失败了,在该系统也不会通过回溯MQ的方式去重新发送消息(回溯MQ重新消费影响太大了)。我们完全可以把发送失败的
userId给记录下来(后面会把相关的日志系统给完善),有了userId以后,我们手动批量重新发就好了。这里手动也不需要业务方调用接口,直接通过类似excel的方式导入就好了。在业务上,很多发送消息的场景即便真的丢了几条数据,都不会被发现。有的消息很重要,但有更多的消息并没那么重要,并且我们即便在调用接口才把数据写入Redis,但很多渠道的消息其实在调用接口后,也不知道是否真正发送到用户上了。

再来看第二个问题:

如果我们要仅靠Redis来实现去重的功能,想要完全没有并发的问题,那得上lua脚本,但上lua脚本是需要成本的。去重的实现需要依赖两个操作:查询和插入。查询后如果没有,则需要添加。那查询和插入需要保持原子性才能避免并发的问题
再把视角拉回到我们为什么要实现去重功能:
当存在事故的时候,我们去重能一定保障到绝大多数的消息不会重复下发。对于整体性的规则,并发消息发送而导致规则被破坏的概率是非常的低。
09、总结
这篇文章简要讲述了Redis的安装以及在SpringBoot中如何使用Redis,主要说明了为什么要实现去重的功能以及代码的设计和功能的具体实现。
技术是离不开业务的,有可能我们设计或实现的代码对于强一致性是有疏漏的,但如果系统的整体是更简单和高效,且业务可接受的时候,这或许是一种好的设计。
这是一种trade-off权衡,要保证数据不丢失和不重复一般情况是需要编写更多的代码和损耗系统性能等才能换来的。我可以在消费消息的时候实现at least once语义,保证数据不丢失。我可以在消费消息的时候,实现真正的幂等,下游调用的时候不会重复。
但这些都是有条件的,要实现at least once语义,需要手动ack。要实现幂等,需要用redis lua或者把记录写入MySQL构建唯一key并把该key设置唯一索引。在订单类的场景是必须的,但在一个核心发消息的系统里,可能并没那么重要。
No Bug,All Feature!

《对线面试官》公众号还在持续分享面试题,没关注的同学可以关注一波!这是austin项目的上一个系列,质量杆杆的
austin项目Gitee链接:https://gitee.com/zhongfucheng/austin
austin项目GitHub链接:https://github.com/ZhongFuCheng3y/austin