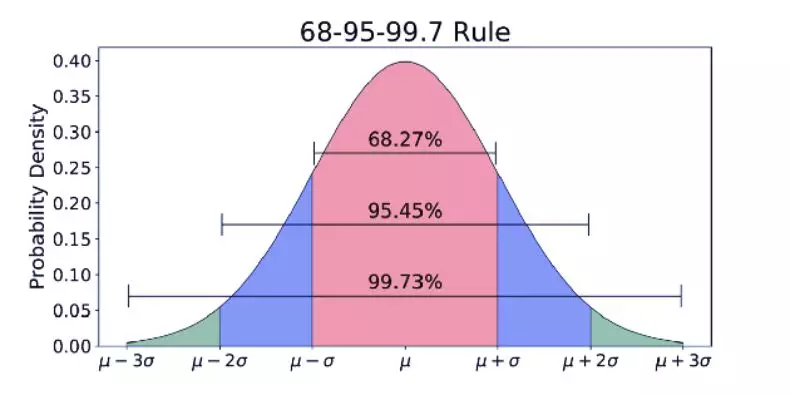
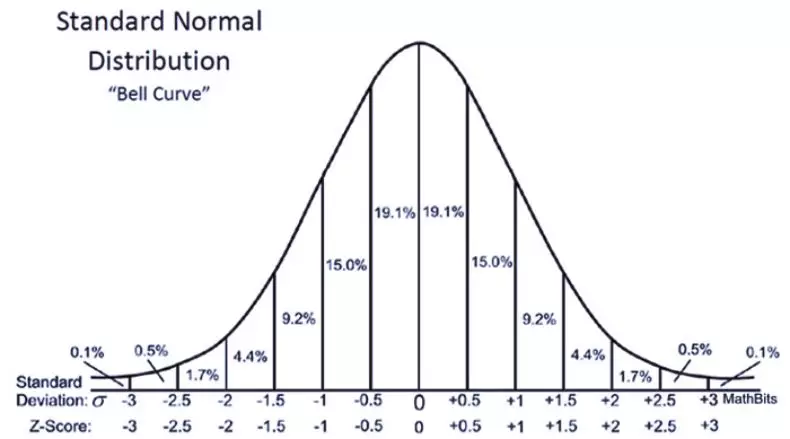
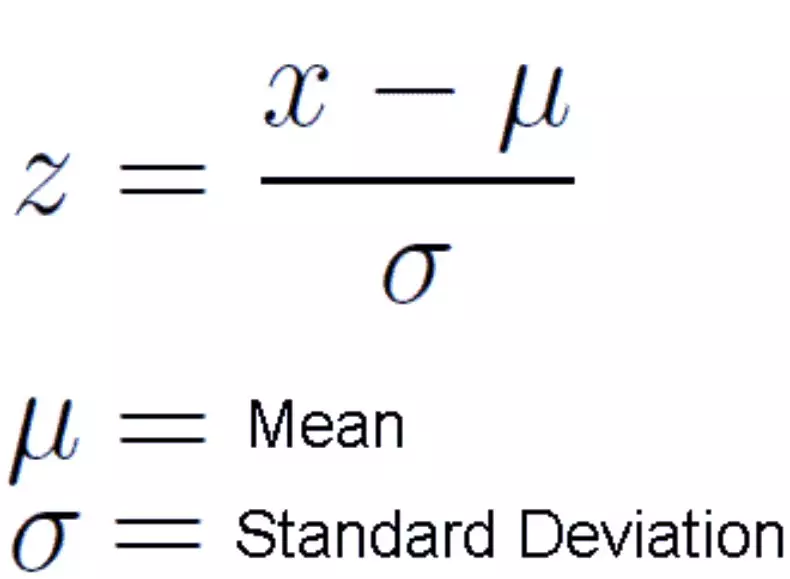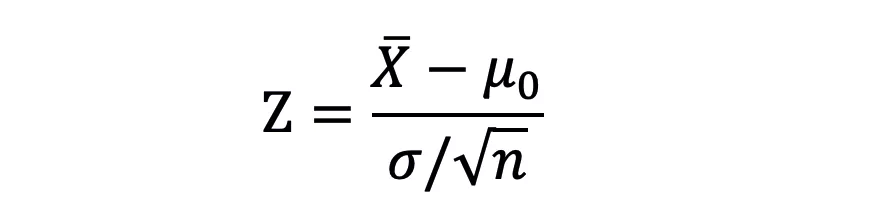还记得文章开头说的发现希格斯玻色子的「5-sigma」阈值吗?在科学家证实发现希格斯玻色子之前,5-sigma 约为数据的「99.9999426696856%」。设置这么严格的阈值是为了避免潜在的错误信号。好了。现在你可能想知道「正态分布是如何应用在假设检验中的」。因为是用 Z 检验进行假设检验的,因此要计算 Z 分数(用于检验统计量),这是数据点到平均值的标准偏差数。在本文的例子中,每个数据点都是收集到的披萨配送时间。▲计算每个数据点的 Z 分数的公式对每个披萨配送时间点计算 Z 分数,并绘制出标准正态分布曲线时,x 轴上的单位从分钟变成了标准差单位,因为已经通过计算(变量减去平均值再除以标准差,见上述公式)将变量标准化了。标准正态分布曲线是很有用的,因为我们可以比较测试结果和在标准差中有标准单位的「正态」总体,特别是在变量的单位不同的情况下。▲Z 分数的标准正态分布Z 分数可以告诉我们整个数据相对于总体平均值的位置。我喜欢 Will Koehrsen 的说法——Z分数越高或越低,结果就越不可能偶然发生,结果就越有可能有意义。但多高(低)才足以说明结果是有意义的呢?这就是解决这个难题的最后一片拼图——p值。根据实验开始前设定的显著水平(alpha)检验结果是否具有统计学意义。
Part3什么是 P 值
与其用维基百科给出的定义来解释 p 值,不如用文中的披萨配送时间为例来解释它。对披萨配送时间随机采样,目的是检查平均配送时间是否大于 30 分钟。如果最终的结果支持披萨店的说法(平均配送时间小于等于 30 分钟),那就接受零假设。否则,就拒绝零假设。因此,p 值的工作就是回答这个问题:如果我生活在披萨配送时间小于等于 30 分钟(零假设成立)的世界中,那我在真实世界中得到的证据有多令人惊讶?
p 值用数字(概率)回答了这一问题。
p 值越低,证据越令人惊讶,零假设越荒谬。
当零假设很荒谬的时候还能做什么?可以拒绝零假设并转而选择备择假设。如果 p 值低于之前定义的显著水平(人们一般将它称为 alpha,但我将它称之为荒谬阈值——别问为什么,我只是觉得这样更容易理解),那么就可以拒绝零假设。现在我们理解了 p 值是什么意思。接下来把 p 值用到文中的例子中。现在已经抽样得到了一些配送时间,计算后发现平均配送时间要长 10 分钟,p 值为 0.03。这意味着在披萨配送时间小于等于 30 分钟(零假设成立)的世界中,由于随机噪声的影响,我们有 3% 的概率会看到披萨配送时间延长了至少 10 分钟。p值越低,结果越有意义,因为它不太可能是由噪声引起的。大多数人对于 p 值都有一个常见的误解:p 值为 0.03 意味着有 3%(概率百分比)的结果是偶然决定的——这是错误的。人们都想得到确切的答案(包括我),而这也是我在很长时间内都对 p 值的解释感到困惑的原因。