点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
前言
排序是我们在写项目中经常用的sql语句的关键字。往往order by 用不好的话也会对sql性能有一定的影响。我们现在就来介绍一下他的执行过程,并介绍一下优化。
正言
首先我们来举个例子,假设你要查询城市是”杭州“的所有人的名字,并且按照姓名排序返回前1000个人的姓名、年龄。
表定义:

这时,你的sql语句可以这么写:

这个语句看上去逻辑很清晰,我们还是需要看看他的sql执行过程。
执行过程一:全字段索引
我们需要在city上添加一个索引。我们在执行explain命令来看看这个语句的执行情况。

Extra这个字段中的”Using filesort“ 表示的就是需要排序,MySql会给每个线程分配分配一块内存用于排序,称为sort_buffer。
下面是图示:

从图中可以看到,满足city=‘杭州’条件的行,是从ID_X到ID_(X+N)的这些记录。
通常情况下,这个语句执行流程如下所示:
初始化sort_buffer, 确定放入name、city、age这三个字段;
从索引city找到第一个满足city=“杭州” 条件的主键id,也就是图中的ID_X;
到主建id索引取出整行,取name、city、age 三个 字段的值,存入sort_buffer中;
从索引city取下一个记录的主键id ;
重复步骤3、4直到city的值不满足查询条件为止,对应的主键id也就是图中的ID_Y;
对sort_buffer 中的数据按照字段name做快译排序;
按照排序结果取前1000行返回给客户端;
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图
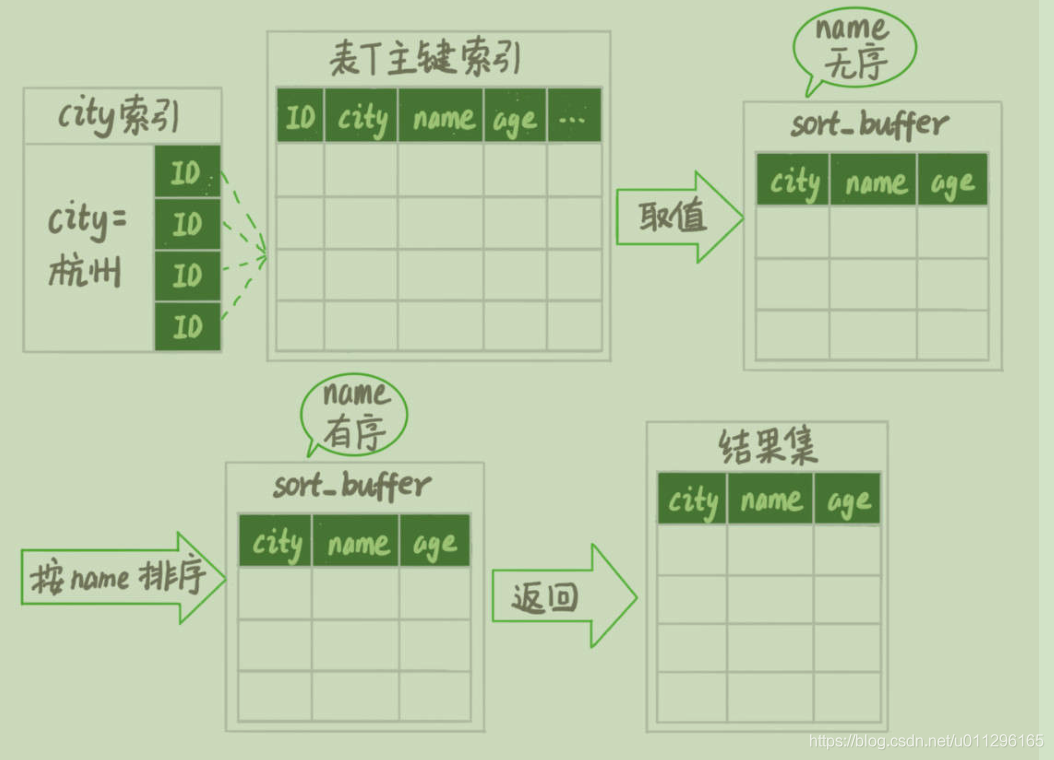
图中“按name排序 ”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size;
routId 排序
在上面这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的。但这个算法有一个问题,如果查询返回的数据字段多,那么内存中放的数据就要分成多个临时文件,排序的性能就会很差。
修改参数 max_length_for_sort_data,是MySql中专门控制用于排序的行数据的长度的一个参数,它的意思是,如果单行的长度超过这个值 ,MySQL就认为单行太大,要换一个算法。

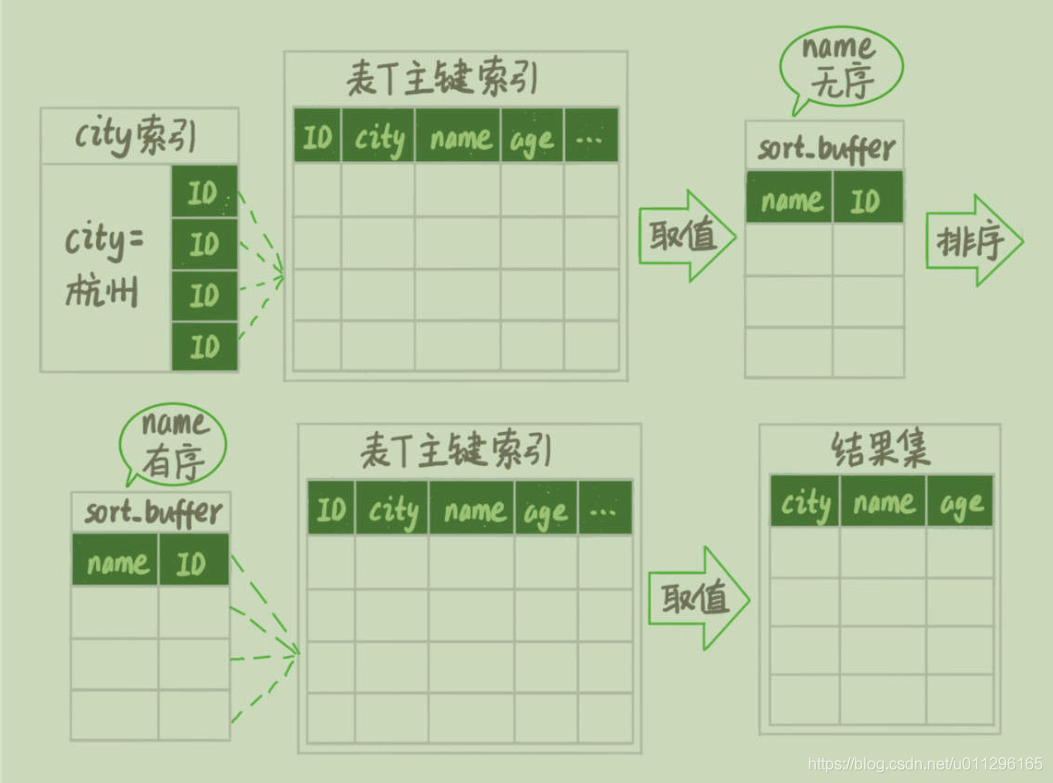
city,name,age这三个字段的定义总长度是36,我把max_length_for_sort_data设置为16,那么放入sort_buffer的字段只有要排序的列(即 name 字段 是order by 后面的关键字)和主键id。
但这时,排序的结果就因为少了city和age字段的值 ,不能直接返回了,整个执行的流程就变成 如下所示的样子:
初始化sort_buffer,确定放入两个字段,即name和id;
从索引city找到第一个满足city='上海’条件的主键,也就是图中的ID_X;
到主键id索引取出整行,取name、id这两个字段,存入sort_buffer中;
从索引city取下一个记录的主键id;
重复3、4步骤,直到找到不city!=‘上海’;
对sort_buffer中的数据按照name进行排序;
遍历排序结果,取前1000行,并按照id的值回到原表中的city、name和age三个字段返回给客户端。
对排序进行优化
alter table t add index_city(city,name);
这样数据的索引就有按照name进行排序。这样整个排序过程就变成了下面这样。
从索引(city,name)找到第一个满足city="杭州"条件的主键id;
到主键id索引取出整行,取name、city、age三个字段的值,作为结果集的一部分直接返回。
从当前索引取出一个索引值,id.
重复2、3步。

在使用explain 来分析这个sql

可以看到extra字段中没有Using filesort了,也就是不需要排序了。
由于覆盖索引的原则,我们可以在进行优化。
alter table t add index_city(city,name,age);
在使用explain 对sql进行分析

发现使用Using index,表示的就是使用了覆盖索引,性能上会快很多。
总结
创建索引在添加和修改数据的时候是会对性能有损耗的, 在优化的时候要考虑使用的场景。
文中的内容借鉴了,极客时间中的Mysql的内容。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:
https://blog.csdn.net/u011296165/article/details/89855549


