
从RPC预热转发看服务端性能调优
为了更好的体验和更优的性能,其实RPC悄悄的做了很多工作,本篇就带大家来看下RPC的一些高级特性和其背后的原因。(还是以开源的dubbo和sofa为例来说明)
Part1RPC为了性能做了哪些努力
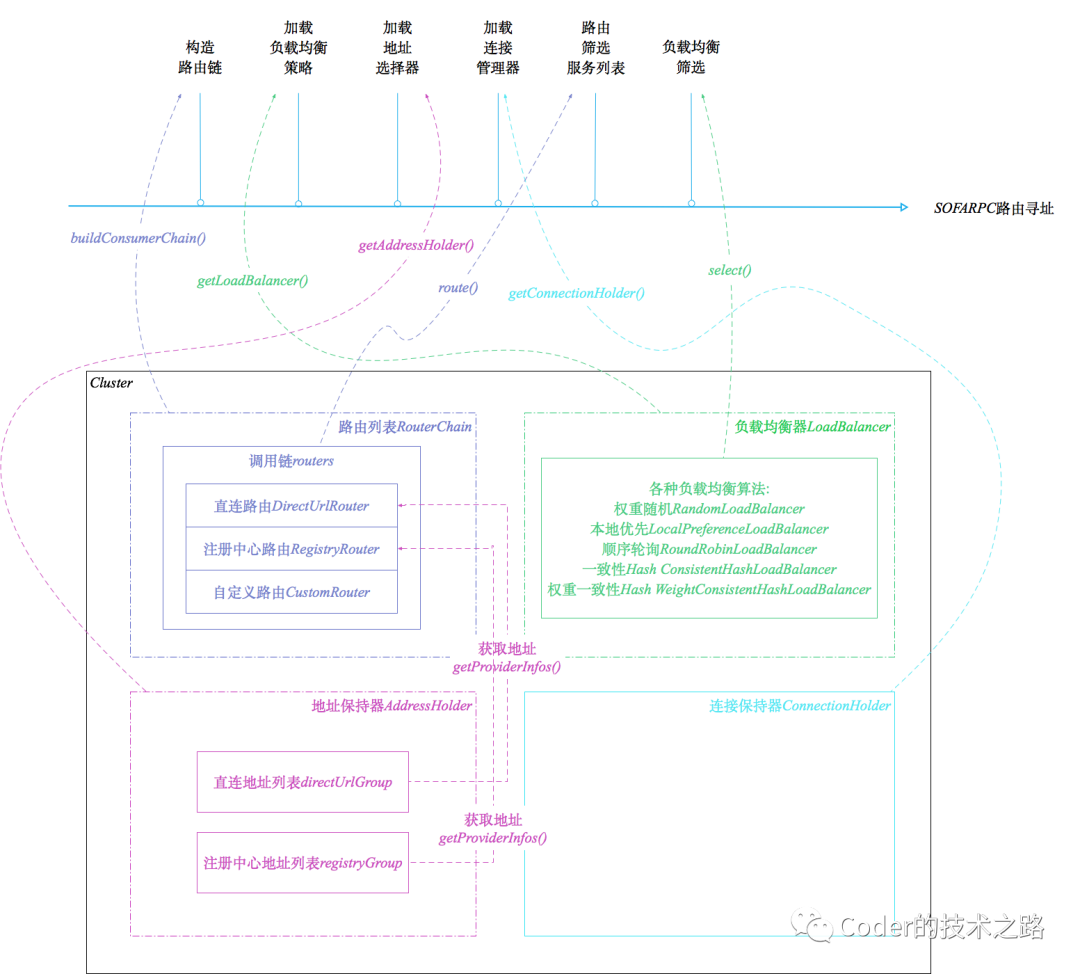
1.1Provider分组和直连
路由寻址,负载均衡是很好,可以保证流量均匀从而保护服务节点稳定。
但是,我们有的时候其实不希望我们的请求乱跑,最好能打到指定的机器上。比如联调和测试的时候,直连功能就显得很重要了。
只有经历过多方合作联调时请求到处乱跑的痛,才知道分组和直连的功能对开发是多么的友好。
//以sofa为例
@Extension(value = "directUrl", order = -20000)
@AutoActive(consumerSide = true)
public class DirectUrlRouter extends Router {
//...
}
我们可以看到直连路由策略的order属性,被赋予了一个极小的值,变成了优先级最高的路由策略,所以只要配置的直连列表,则会优先走配置中的列表地址。
1.2异步调用
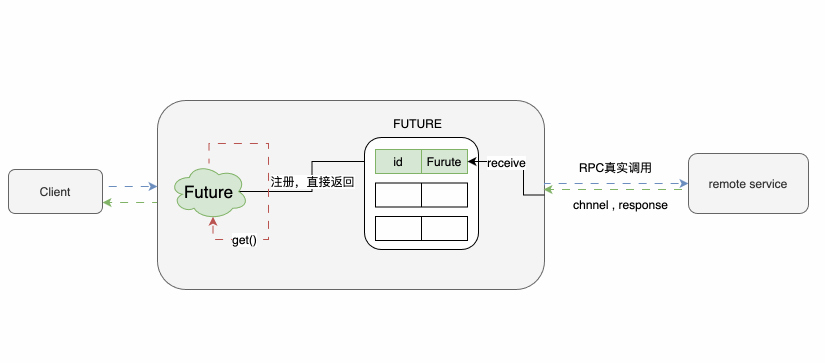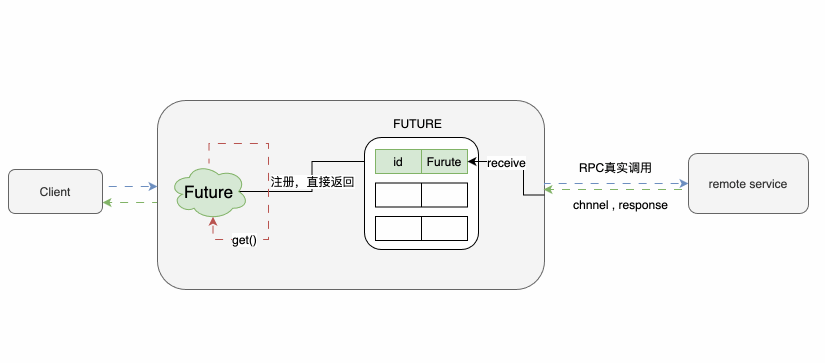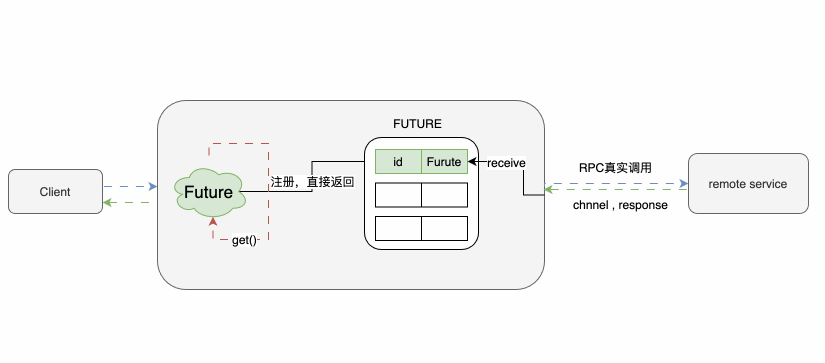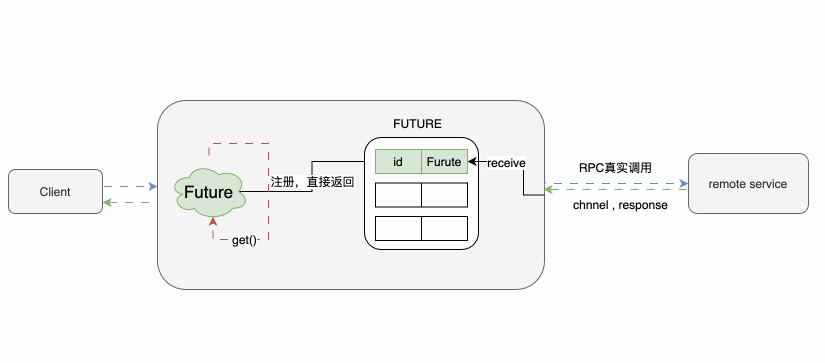
异步调用对服务性能和并发的支持起到很大的作用。
一般异步调用有Futurn和callback等方式,这里我们说下Future的原理:
调用下游之后,先返回一个Future,上游通过Future.get()方法对结果进行获取,如果结果未返回则会让出CPU资源进入等待,直到结果到达或超时后触发回调方法才被唤醒。由于篇幅问题,Future的核心逻辑的相关注释就不放了,之前的消息消费顺序保障的文章中也有叙述,有兴趣的同学可以看下~
1.3本地优先、远程优先
很多时候,我们会遇到消费端和服务端可能都是自己的情况。这个时候,在常规的路由寻址之外,又提供给我们一种调用的可能性,就是直接调用当前服务器上的程序,这样做的好处比较明显,省去了网络传输等时间损耗,效率更高。
List<ProviderInfo> localProviderInfo = new ArrayList<ProviderInfo>();
// 解析IP,看是否和本地一致
for (ProviderInfo providerInfo : providerInfos) {
if (localhost.equals(providerInfo.getHost())) {
localProviderInfo.add(providerInfo);
}
}
// 命中本机的服务端
if (CommonUtils.isNotEmpty(localProviderInfo)) {
return super.doSelect(invocation, localProviderInfo);
} else {
// 没有命中本机上的服务端
return super.doSelect(invocation, providerInfos);
}
当然,也需要看业务和内部服务路由的实际情况,比如在阿里的单元化部署下,需要根据用户ID路由到对应的zone进行处理,如果还是优先本机,那就可能在操作数据库的时候涉及到跨zone调用,比走远程rpc更加耗时。因此这种情况下就需要禁用本机优先策略。
1.4延迟暴露
很多时候,我们的服务需要依赖一些其他内容才可以正常提供服务,比如缓存预热、线程池预热等等,所以,在服务真正就绪之后再注册到配置中心是很有必要的。
//服务注册之前,先延迟
public void export() {
// 根据配置延迟加载
if (providerConfig.getDelay() > 0) {
Thread thread = factory.newThread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(providerConfig.getDelay());
} catch (Throwable ignore) {
}
//真正的服务注册逻辑
doExport();
}
});
thread.start();
} else {
doExport();
}
}
1.5粘滞连接
问: 我们需要每次都进行路由寻址和负载均衡来确定服务地址么?
答: 大部分情况是有利的,不过有些特殊的场景,更希望多次请求连接到同一台服务器。
比如,有状态的服务(很多带数据功能的服务都是有状态的,比如很久之前的带登陆session的Tomcat服务、存储集群服务等),其实希望每次请求都连接到相同的服务器。
这就用到了粘滞连接功能。
protected ProviderInfo select(...)throws SofaRpcException {
// 判断isSticky 粘滞连接配置
if (consumerConfig.isSticky()) {
//如果最后一次使用的provider不为空,则使用
if (lastProviderInfo != null) {
ProviderInfo providerInfo = lastProviderInfo;
//获取对应连接
ClientTransport lastTransport = connectionHolder.getAvailableClientTransport(providerInfo);
if (lastTransport != null && lastTransport.isAvailable()) {
checkAlias(providerInfo, message);
return providerInfo;
}
}
}
...
}
1.6预热转发
前面扯了那么多,其实,这个才是我们今天想说的重点。
预热转发是针对服务节点的负载均衡来说的。因为在服务刚启动的时候,如果请求过多可能会影响机器性能和正常业务,如果将处于预热期的机器的请求转发到集群内其它机器,过了预热期之后再恢复正常,则可以保证服务节点的性能和服务整体的可用性。
那么这个功能是怎么实现的呢?--带权重的随机负载均衡。

//累加总权重totalWeight,代码忽略。。。
//在总权重内随机得到一个值
int offset = random.nextInt(totalWeight);
//确定随机值落在哪个片断上
for (int i = 0; i < size; i++) {
offset -= getWeight(providerInfos.get(i));
if (offset < 0) {
providerInfo = providerInfos.get(i);
break;
}
}
配置示例:
core_proxy_url=weightStarting:0.2,during:60,weightStarted:0.2,address:x.x.x.x,uniqueId:core_unique
如上,预热权重20%,预热持续时长60s。这样,按照上述计算方式,权重小的服务节点被选到的几率就相对小,以此达到权重随机的效果。
那么,为什么刚发布的服务需要预热呢?预热可以起到什么作用呢?
Part2什么是JIT优化
都说C++快,Java慢,都是高级语言,是什么导致了运行速度的差别呢?
这个涉及到了两种执行方式:解释执行 和 编译执行。
相对于C++直接将代码编译成机器码运行的方式,Java为了实现跨平台、高度抽象等特性,增加了虚拟机层来实现Java代码到机器码的转换,Java程序先是被编译成符合虚拟机规范的.class字节码逐条将字节码翻译成机器码然后执行,所以,速度上就慢一些。
虽然,JVM的加入,给Java的运行速度增加了不少损耗,但是好处也很多,除了跨平台,还为我们实现了诸如内存管理、垃圾回收等容器级通用功能,让研发人员可以更加聚焦业务。
不过,Java也是要面子的,我允许自己慢,但我不允许自己慢那么多!
怎么办呢?遵循二八原则,是不是可以找寻程序当中的贡献了大部分调用量的核心代码,把这部分编译成机器码,提升其速度,不就把整体的速度提上去了么,JVM也是这么做的~
所以,JVM兼容了解释执行和编译执行两种方式,也就是我们常说的即时编译。
前面的问题到这里其实就可以回答了。为什么需要预热转发呢?是为了用小流量对程序进行预热,目的是为了让核心代码进行及时编译,提高峰值运行速率,提升服务响应~
下面让我们详细看下JIT。
2.1即时编译器
为了权衡编译时间和执行效率,JVM设置了多种即时编译器:
C1(Client 编译器):基于字节码完成部分优化,如方法内联、常量传递,相对于C2,速度快,但性能稍差。 C2(Server 编译器):耗时较长的全局优化,如无用代码消除、重排序、循环展开、公共子表达式替代、常量传播等等。 Graal(新的JIT编译器):侧重于性能和语言操作性。在一些负载上提供比传统编译器更好的峰值性能;用 Graal 执行的语言可以互相调用,可以使用来自其他语言的库。
2.2JIT优化触发条件
前面我们说过,JVM其实是希望找到承担更多调用请求的代码块进行优化,那,怎么来确认哪些代码时优化目标呢?--热点探测
基于采样的热点探测:
周期采样,检测各线程栈顶方法,经常出现的方法即为热点方法。好处是简单高效,缺点是不精确,容易受线程运行状态的影响。
基于计数的热点探测:
(包括方法调用计数器和回边计数器)每个方法建立计数器,用来统计调用次数。如果该方法执行次数超过阈值,则该方法被认定为热点方法。好处是足够精确。缺点是空间损耗大,且实现较难。
另外,可以通过如XX:CompileThreshold等参数来修改阈值,不过,没有绝对把握,还是不要动为好。
Part3JIT指导代码优化
3.1方法内联
为什么我们在刚写代码的时候,总是被建议不要写很大的方法体?方法内联的JIT优化策略就是其中一个重要的原因。(还有GC友好等原因)
JVM内的每一次方法调用,都是栈帧在内存中出栈入栈的过程,方法多了性能损耗自然大,所以要进行方法内联,即把方法执行逻辑直接复制到调用方内部,避免方法调用。
但是,方法内联是有方法大小限制的,超过了一定大小的方法,没法做内联优化。所以,平常应该注意,尽量避免写很大很冗长的方法。
让我们来举个栗子实际感受一下~
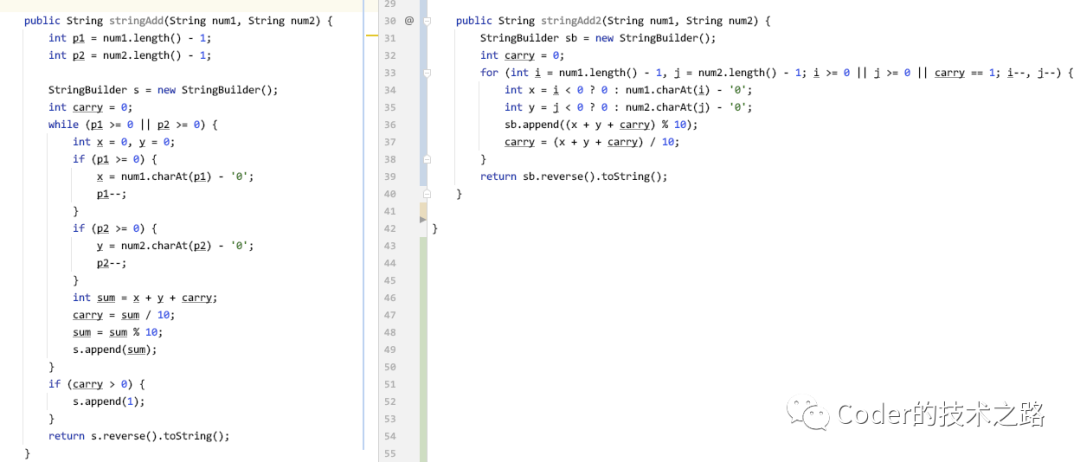
如上图所示,两个字符串型整数相加,都能实现功能,前一种写法,把中间过程全都拆开,罗列在的方法内,整个方法虽然理解起来稍微方便些,但整体显得冗长;第二种方法,把各个条件都囊括在了for循环条件内,三行代码完成整体操作。
如果要去评价,我觉得大部分人都会说第二种写的好,但是,第二种的好难道真的局限于优雅么?
//添加JVM启动参数,用于打印代码执行过程中的编译详情
//-XX:+PrintCompilation
String num1 = "12345";
String num2 = "23456";
//循环15000次,因为1.8分层编译下,各层阈值不一样,我们取最大阈值
for (int i=0;i<15001;i++) {
rejectionLB1.stringAdd(num1, num2);
//rejectionLB1.stringAdd2(num1, num2);
}

(图中编译层次这一列中,3代表C1编译,4代表C2编译)
我们看到,随着代码的执行次数的增加,一些方法,进行了C1编译,如我们的主方法stringAdd,而少数方法,从C1编译提升到了C2编译,如AbstractStringBuilder::append方法。

我们看到了什么,stringAdd2 居然在进行到运行后期执行了C2编译,而且很明显,方法二的C2编译的方法,比方法一要多不少。所以,平常写代码该注意些什么,是不是显而易见了。。。
3.2其他优化
方法内联虽然只是一种简单优化,但是,是后续其他优化的基石。
而JVM的分层优化涉及的点非常多[1]:
局部优化:关注局部数据流分析,数组越界检查消除;寄存器优化,优化跳转、循环、异常处理等;代码简化,如公共表达式提取等等等。
控制流优化:专注于代码重排序、循环缩减、循环展开、异常定位优化等等等。
全局优化:主要关注冗余消除,如方法调用、锁;逃逸分析;GC和内存分配优化等等等。
Part4总结
本篇从RPC的预热转发功能,引出了其背后的理论依据--JIT优化。阐述了JIT的基本概念,并用一个实例说明了代码编写风格对JIT优化的实际影响。
JIT相关的优化实现起来非常难,不过其原理和作用对我们普通研发也不是特别难理解,学习JIT优化的目的,在于了解JVM底层的运行逻辑和实现,让我们可以更加信任托管,聚焦业务逻辑,同时在编写代码时,尽量用JVM友好的方式进行,从而达到更好看、更高效的目的。
参考资料
JIT 编译器如何优化代码: "https://www.ibm.com/docs/zh/sdk-java-technology/8?topic=compiler-how-jit-optimizes-code"