
基于ChatGPT的视频智能摘要实战

向AI转型的程序员都关注了这个号👇👇👇
随着在 YouTube 上提交的大量新视频,很容易感到挑战并努力跟上我想看的一切。我可以与我每天将视频添加到“稍后观看”列表中的经历联系起来,只是为了让列表变得越来越长,实际上并没有稍后再看。现在,像 ChatGPT 或 LLaMA 这样的大型语言模型为这个长期问题提供了一个潜在的解决方案。
通过将数小时的视频内容转换为几行准确的摘要文本,视频摘要器可以快速为我们提供视频的要点,这样我们就不必花费大量时间来完整观看它。在我创建这个网络应用程序之后,我最常使用的场景是参考它的摘要来决定某个视频是否值得观看,尤其是那些辅导、脱口秀或演示视频。
你可以通过多种方式使用强大的语言模型来完成此视频摘要。
一种选择是使用或设计 ChatGPT 插件,它可以将令人难以置信的 AI 连接到实时 YouTube 网站。但是,只有少数商业开发人员可以访问 ChatGPT 插件,因此这对包括我在内的所有人来说可能不是最可行的途径。
另一种选择是下载视频的抄本(字幕)并将其附加到提示中,然后要求语言模型通过发送提示来总结抄本文本。然而,这种方法有一个很大的缺点——你不能总结一个包含超过 4096 个标记的视频,这对于一个普通的谈话节目来说通常是 7 分钟左右。
一个更有前途的选择是使用上下文学习技术对转录本进行向量化,并使用向量向语言模型提示“摘要”查询。这种方法可以生成准确的答案,指示转录文本的摘要,并且不限制视频长度。
如果你有兴趣开发自己的上下文学习应用程序,我之前关于构建聊天机器人以学习和聊天文档的文章提供了一个很好的起点。通过一些细微的修改,我们可以应用相同的方法来创建我们自己的视频摘要器。在本文中,我将逐步指导你完成开发过程,以便你了解并复制自己的视频摘要器。
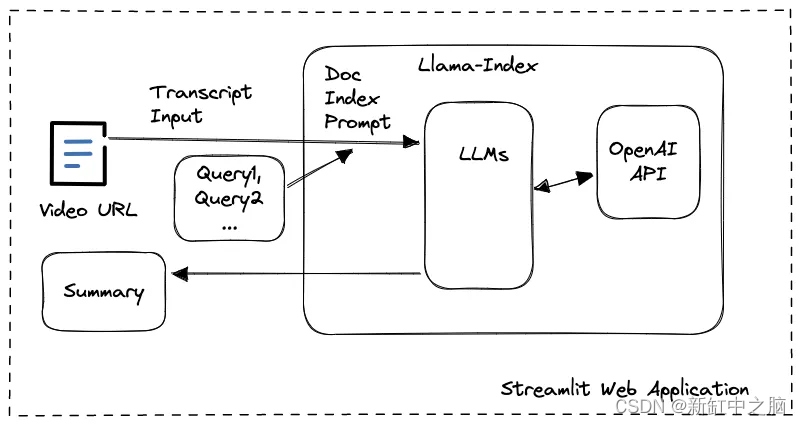
1、功能框图
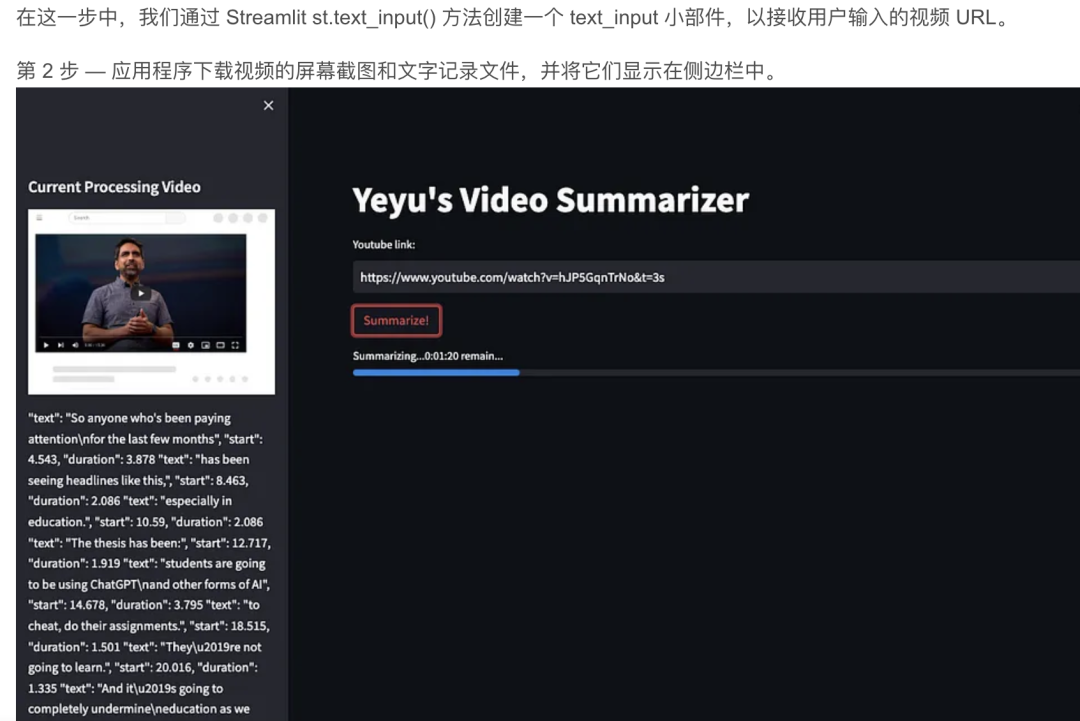
在这个Video Summarizer应用程序中,我们以llama-index为基础,开发了一个Streamlit web应用程序,为用户提供视频URL的输入以及屏幕截图、文字记录和摘要内容的显示。使用 llamaIndex 工具包,我们不必担心 OpenAI 中的 API 调用,因为对嵌入使用的复杂性或提示大小限制的担忧很容易被其内部数据结构和 LLM 任务管理所覆盖。
你有没有想过为什么我在让 LLM 生成摘要时设计了几个查询而不是一个用于转录文本处理的查询?答案在于情境学习过程。当文档被送入 LLM 时,它会根据其大小分成块或节点。然后将这些块转换为嵌入并存储为向量。
当提示用户查询时,模型将搜索向量存储以找到最相关的块并根据这些特定块生成答案。例如,如果你在大型文档(如 20 分钟的视频转录本)上查询“文章摘要”,模型可能只会生成最后 5 分钟的摘要,因为最后一块与上下文最相关 的“总结”。
为了说明这个概念,请看下面的图表:
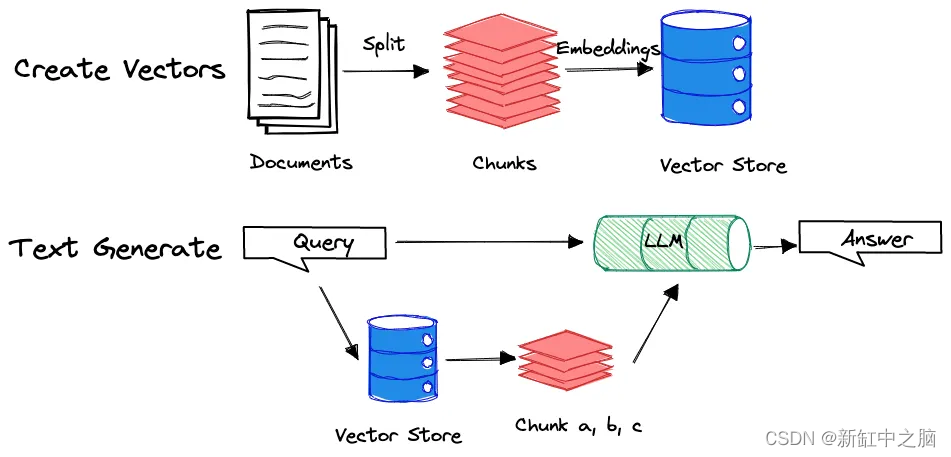
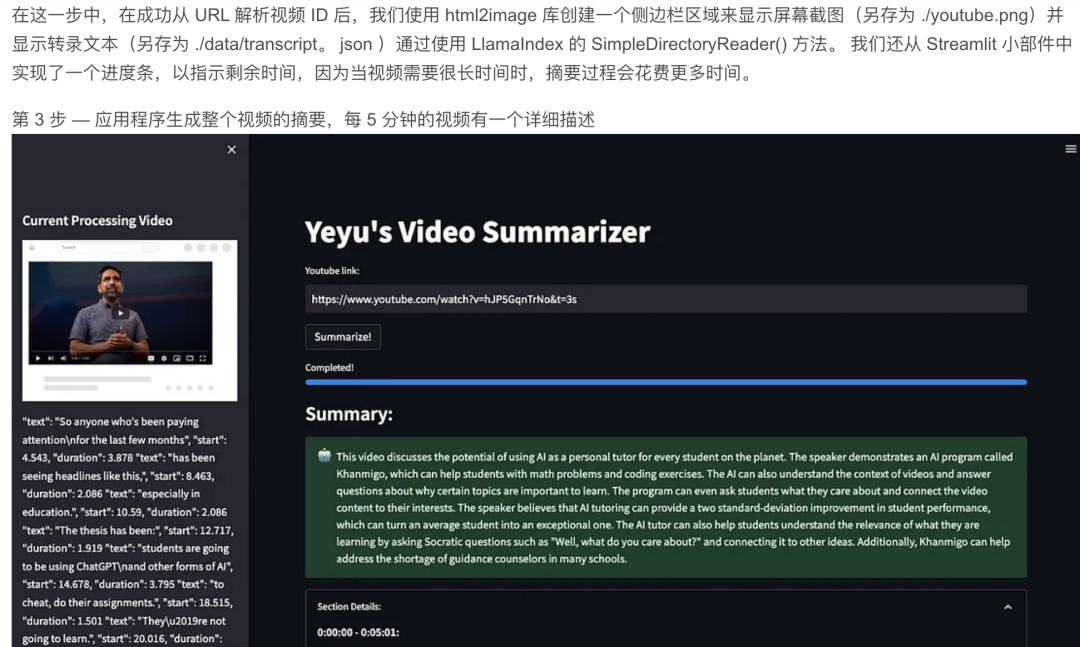
通过设计多个查询,我们可以促使 LLM 生成更全面的摘要,涵盖整个文档。我将在本文后面更深入地组织多个查询。
从第2章到第5章,我将重点介绍本项目中使用到的所有模块的基础知识和典型用法介绍。如果你愿意在没有这些技术背景的情况下立即开始编写整个 Video Summarizer 应用程序,建议你转到第 6 章。
2、Youtube 视频转录文本
总结 YouTube 视频的第一步是下载转录文本。有一个名为 youtube-transcript-api 的开源 Python 库可以完美满足我们的要求。
使用如下命令安装模块后,
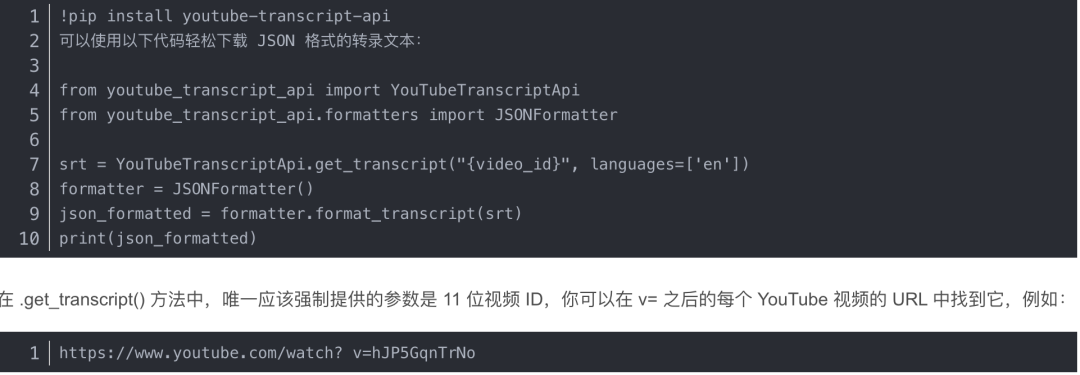
当视频提供英语以外的其他语言时,可以将它们添加到参数语言中,该参数语言作为包含不同语言的列表。
该库还提供“Formatter”方法来生成具有定义格式的转录数据。在这种情况下,我们只需要 JSON 格式即可进行进一步的步骤。
通过运行上面的代码,你会看到像这样的一个像样的转录文本:

4、LlamaIndex
LlamaIndex 是一个 Python 库,充当用户私有数据和大型语言模型 (LLM) 之间的接口。它有几个对开发人员有用的功能,包括连接到各种数据源、处理提示限制、创建语言数据索引、将提示插入数据、将文本拆分为更小的块以及提供查询索引的接口的能力 . 借助 LlamaIndex,开发人员无需实施数据转换即可将现有数据用于 LLM,管理 LLM 与数据的交互方式,并提高 LLM 的性能。
可以在此处查看完整的LlamaIndex文档。
以下是使用 LlamaIndex 的一般步骤:
安装包:
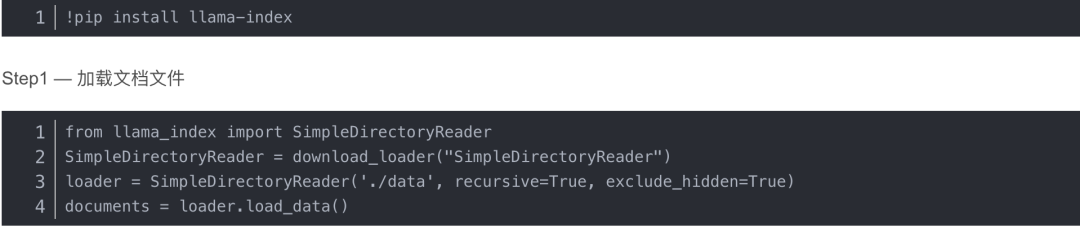
SimpleDirectoryReader 是 LlamaIndex 工具集中的文件加载器之一。它支持在用户提供的文件夹下加载多个文件,在本例中,它是子文件夹“./data/”。这个神奇的加载器功能可以支持解析各种文件类型,如.pdf、.jpg、.png、.docx等,让您不必自己将文件转换为文本。在我们的应用程序中,我们只加载一个文本文件 (.json) 来包含视频转录数据
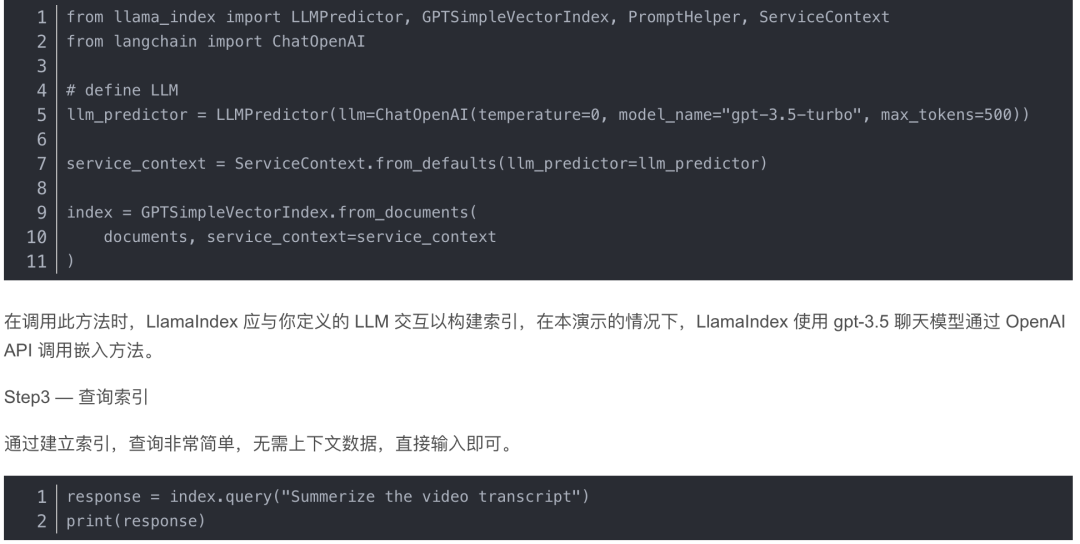
Step2 — 构建索引
5、Web开发
与我文章中之前的项目一样,我们将继续使用方便的 Streamlit 工具集来构建 Video Summarizer 应用程序。
Streamlit 是一个开源的 Python 库,有助于创建交互式 Web 应用程序。它的主要目的是供数据科学家和机器学习工程师用来与他人分享他们的工作。借助 Streamlit,开发人员可以使用最少的代码创建应用程序,并且可以使用单个命令轻松地将它们部署到 Web。
它提供了多种可用于创建交互式应用程序的小部件。这些小部件包括按钮、文本框、滑块和图表。可以从其官方文档中找到所有小部件的用法。
Web 应用程序的典型 Streamlit 代码可以像下面这样简单:


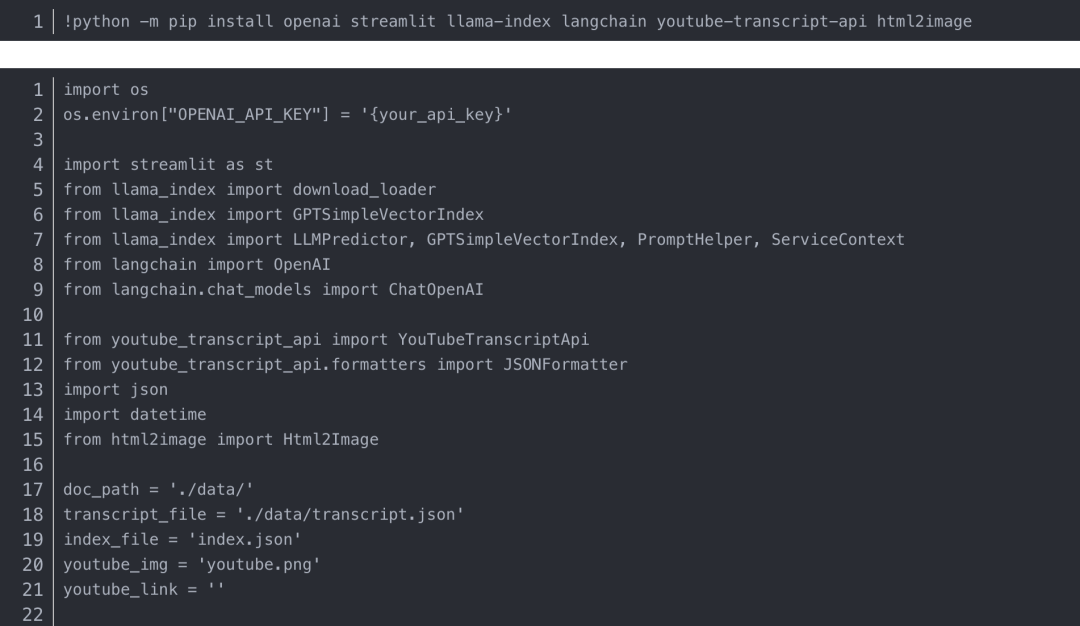
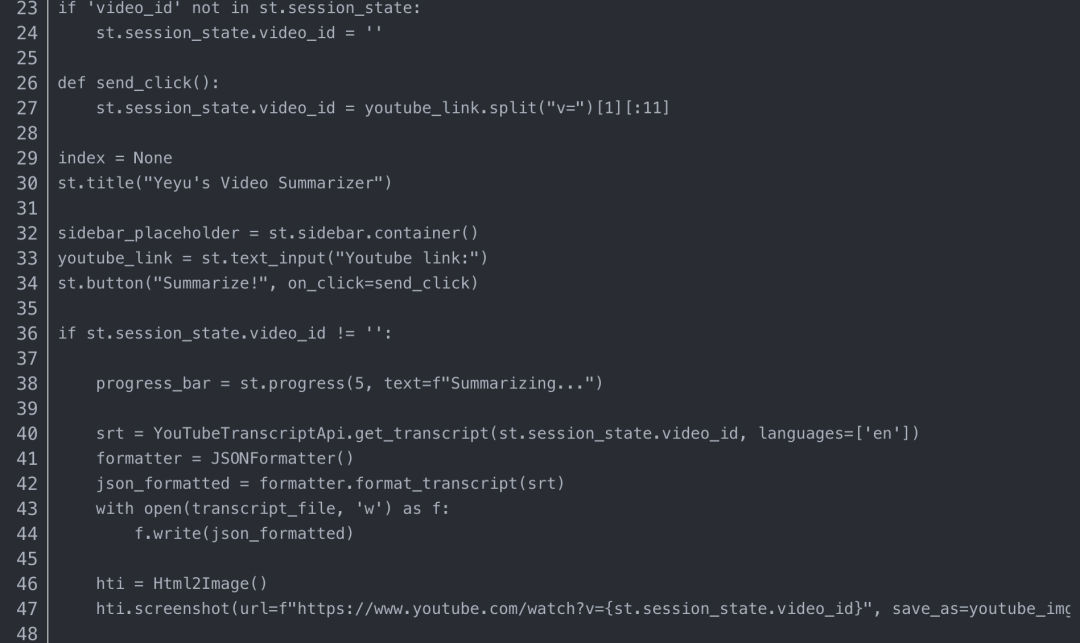
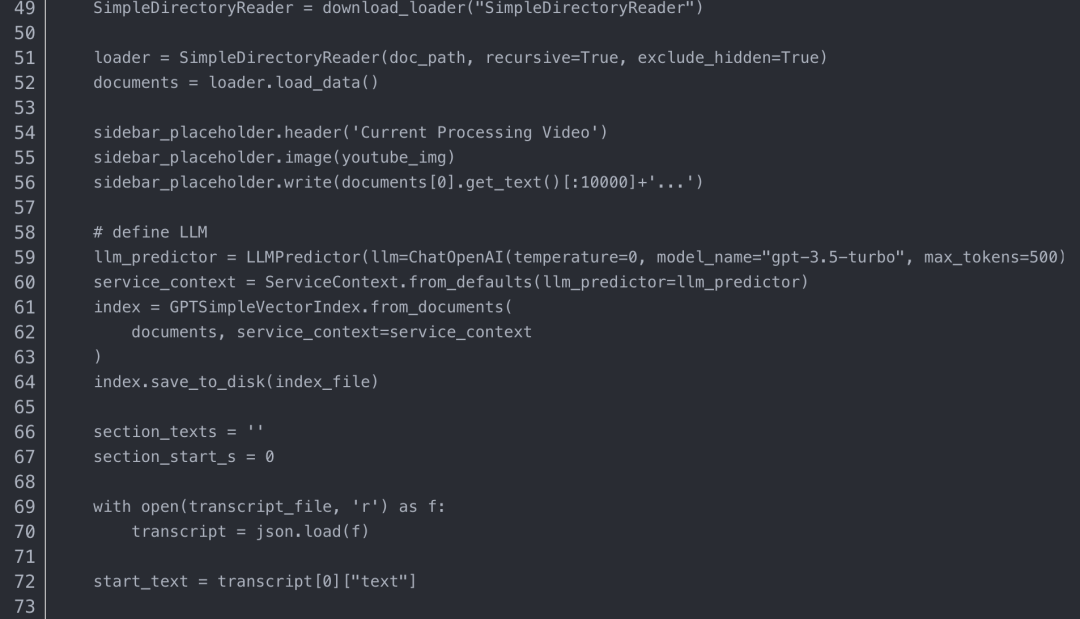
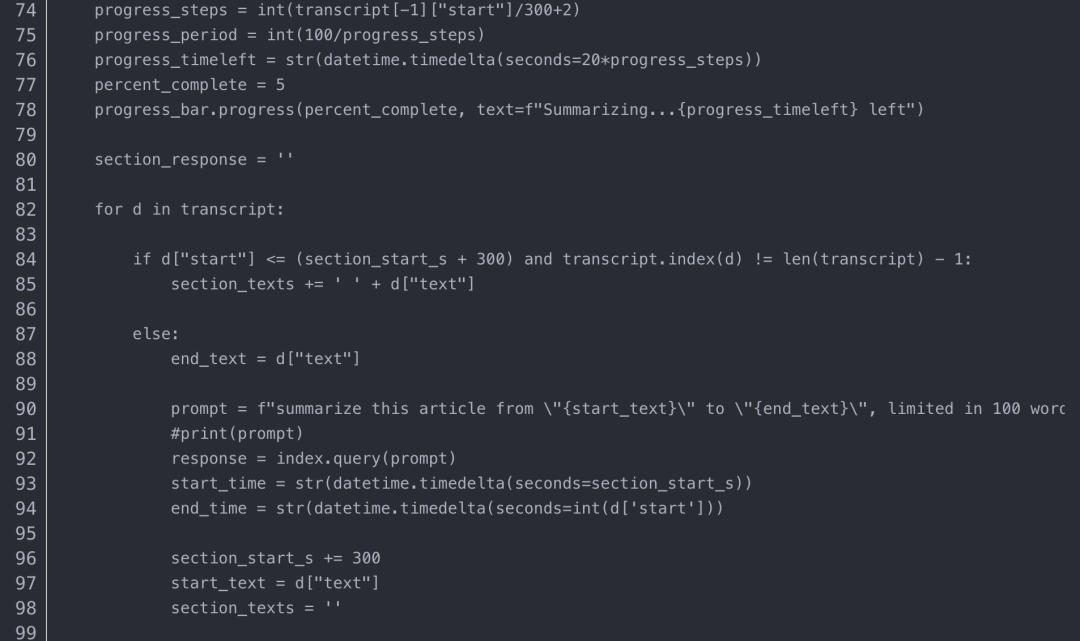
将代码保存到 Python 文件“demo.py”,创建一个 ./data/ 文件夹,然后运行命令:
!python -m streamlit run demo.py
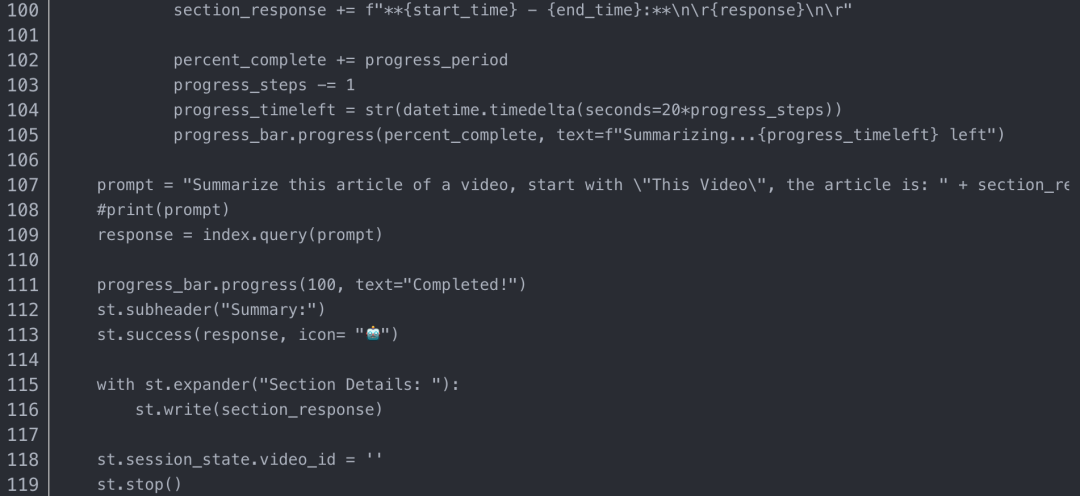
Video Summarizer 现已准备就绪,能够简单而有效地执行其任务。
注意——请从一段短视频开始测试,因为长视频会花费你大量的 OpenAI API 使用费。在继续之前,还请检查视频是否启用文本转录。
机器学习算法AI大数据技术
搜索公众号添加:
datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加:
datayx