
头,有点秃了.
我是y哥的读者,已经毕业几年了,一直在做业务开发,最近想要跳槽,自然就会读读y哥写的对线面试官系列,毕竟现在面试都得搞八股文啊。
回头看了下对线面试官的目录,竟然已经快刷掉一半了,不过到现在好像又已经把前面刷过的忘得七七八八了。但不想那么多了,先过一遍吧。
从Java虚拟机往下就是Spring章节了,而Spring章节有三篇文章:Spring基础、SpringMVC、SpringBean生命周期。没有SpringBoot和SpringCloud是我预料之外的,感觉这两块也是会出很常见的面试题,不知道第二季能不能补上呢。对于Spring这个章节,我很快就刷完了,大多数都是概念理解的东西,要是真问到细节我也记不住。
《Spring基础》主要讲了什么是iOC和AOP,进而引出了SpringBean生命周期,而生命周期大概就是在SpringBean的各个重要节点(定义/代理/初始化后/销毁)上提供hook给我们去扩展。
《SpringBean生命周期》中间的那些细节我是不太关心的,反正意思到位了,就是提供扩展钩子嘛,顺便理解下循环依赖是怎么解决的,原来就这么回事。
《SpringMVC》就是Spring的webmvc模块的内容了,主要就是考察个处理流程,这个背得朗朗上口了:映射器->适配器->拦截器->真实调用->视图解析器,看源码后也就这么个结论,所以不难。
看完了之后,原来Spring就已经提供了这么多扩展,原来拦截器是在这个过程中生效的...总的来说吧,看看这种内容对日常写代码还是有点用的,但不多。
Spring章节后就是Redis章节,Redis是内存存储,现在几乎在后端里是标配了。我觉得看Redis比看什么JVM有价值多了,Redis不会用会影响到接口性能,而JVM不会用也不会影响到啥。
《Redis基础》挺简单的,就介绍了下在线上什么场景用了Redis,这个我会套回到自己的项目上的,没啥好讲的。而为什么Redis快,那首要原因肯定是内存啊,其次就是非阻塞的IO多路复用机制避免上下文切换所带来的吧。
《Redis持久化》这个我们在使用的时候一般都不关注,正如在使用MySQL的时候不关心它是怎么落盘的,因为我们认为就是理所当然的。而AOF/RDB持久化一般都是由维护Redis集群的人所配置的,了解下这个机制是可以的,但对应用开发没多大的帮助。面试要是真问到了,经过这一轮复习,应该也能大致讲讲。
《Redis主从架构》和《Redis分片集群》我觉得这个还是得懂的,就在公司里Redis的架构是怎么样的,是cluster 集群模式呢,还是主从模式,还是通过proxy做分片呢,不同的架构会影响到我们对它的使用。
比如,如果我是redis cluster模式,这时候我使用批量的命令,是不是对批量所带来的提升就没那么大了(毕竟已经数据已经被分配到不同的节点了,不还是得分发到不同的节点中进行命令传递),这种架构下可以做什么来尽可能适配批量的命令?比如说hash tag / 计算好key的节点再做并发啥的,而这些是需要了解Redis部署的架构才能理解为啥这样做的。
《Redis主从架构》主要讲的是主从架构下,数据同步(完全和部分同步是怎么做的),如果服务器出了问题,那哨兵的选举过程是怎么样的。这个我感觉了解就好了,不会影响到我们正常的使用,出了问题也轮不到我们这些做业务开发的去查。不过可以顺着这些功能,想想其他的存储是不是也类似这么做的。
《Redis分片集群》这种架构在互联网里是比较常见了,现在基本出去都说什么分布式,分片集群这种模式就算是分布式了。而要实现数据分发到不同的节点,可以采用官方的Cluster方案,也可以做Proxy,这两种方案各有各的优缺点。原来Cluster方案的Hash槽是16384个,至于为什么这么多,是作者认为的合理值,没有啥大的探讨意义。(求面试的时候别问我这个玩意,真没意思),不过在这侧面可以说明节点之间的网络通信确实是挺大的。
Redis章节总体看下来,看似都是八股文,但如果懂这些东西,会给你在使用Redis的时候有种莫名的信心,即便出了问题也不会太慌。不过如果深挖细节,那确实还是八股文。
Redis章节后面是消息队列,消息队列就只有两篇文章《Kafka基础》和《使用Kafka会考虑什么问题》,没有别的MQ确实挺可惜的,但是估计面试也够用了,一般面试官也不会各种MQ的,反正都是举一反三的嘛。不过,看完我觉得不够细,不够八股文,没有那股味道,都是以线上的角度去聊怎么用Kafka的,很多原理性的东西都没有。虽然我本身不爱看这些东西,但面试就是要啊,希望后面y哥可以补充补充。
《Kafka基础》主要是讲了为啥Kafka那么快,这个可以盲猜 顺序写和操作系统cache(我感觉换每种存储都可以这样盲猜,反正思想都是一样的)。。然后再结合Kafka的天然架构,多partition,这不就是并行吗。然后再说说中间的读写做了零拷贝,这就是它能这么快的原因了。
不过零拷贝这个我看完了,也不太好去描述,感觉有点理论性,也挺难记的。知道零拷贝有mmap和sendfile,但描述这个过程我总感觉嘴瓢。。
《使用Kafka会考虑什么问题》这个文章就是针对消息不丢失,消息顺序性,结合业务做的解释,没过多的理论在,全凭业务在吹水。不过,如何在client实现至少一次消息,这个还是可以去看看的。
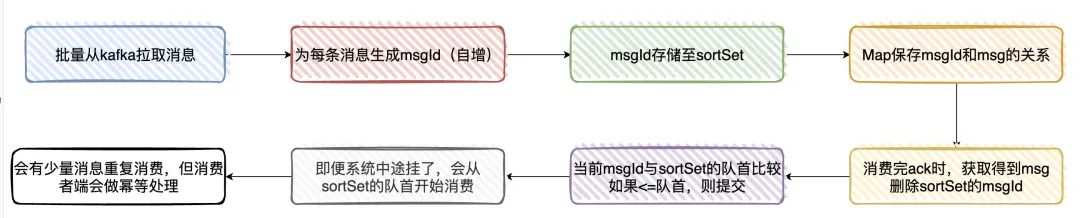
这两天看的这三章,感觉没有那么的八股文,但我又想多点八股文的内容,真TM的矛盾。产生这种矛盾可能就在于,这些在生产环境下是真的有在用的,学了这些真有可能会让自己所维护的程序变得更好,至少不像什么JVM和并发的八股文,看完用不上就立马忘了。
最近看这破八股文,头都大了。