在云原生时代下,应用工作负载都是以容器的形式部署在宿主机,共享各类物理资源。随着宿主机硬件性能的增强,单节点的容器部署密度进一步提升,由此带来的进程间 CPU 争用,跨 NUMA 访存等问题也更加严重,影响了应用性能表现。如何分配和管理宿主机的 CPU 资源,保障应用可以获得最优的服务质量,是衡量容器服务技术能力的关键因素。
Kubernetes 为容器资源管理提供了 request(请求)和 limit(约束)的语义描述,当容器指定了 request 时,调度器会利用该信息决定 Pod 应该被分配到哪个节点上;当容器指定了 limit 时,Kubelet 会确保容器在运行时不会超用。
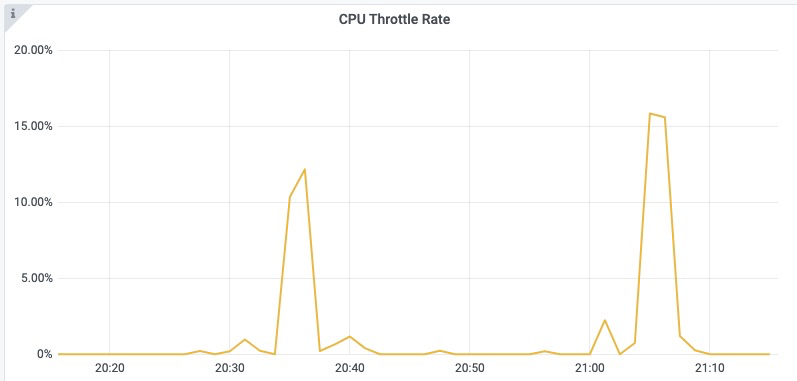
CPU 是一种典型的分时复用型资源,内核调度器会将 CPU 分为多个时间片,轮流为各进程分配一定的运行时间。Kubelet 默认的 CPU 管理策略会通过 Linux 内核的 CFS 带宽控制器(CFS Bandwidth Controller)来控制容器 CPU 资源的使用上限。在多核节点下,进程在运行过程中经常会被迁移到其不同的核心,考虑到有些应用的性能对 CPU 上下文切换比较敏感,Kubelet 还提供了 static 策略,允许 Guaranteed 类型 Pod 独占 CPU 核心。内核 CFS 调度是通过 cfs_period 和 cfs_quota 两个参数来管理容器 CPU 时间片消耗的,cfs_period 一般为固定值 100 ms,cfs_quota 对应容器的 CPU Limit。例如对于一个 CPU Limit = 2 的容器,其 cfs_quota 会被设置为 200ms,表示该容器在每 100ms 的时间周期内最多使用 200ms 的 CPU 时间片,即 2 个 CPU 核心。当其 CPU 使用量超出预设的 limit 值时,容器中的进程会受内核调度约束而被限流。细心的应用管理员往往会在集群 Pod 监控中的 CPU Throttle Rate 指标观察到这一特征。让应用管理员常常感到疑惑的是,为什么容器的资源利用率并不高,但却频繁出现应用性能下降的问题?从 CPU 资源的角度来分析,问题通常来自于以下两方面:一是内核在根据 CPU Limit 限制容器资源消耗时产生的 CPU Throttle 问题;二是受 CPU 拓扑结构的影响,部分应用对进程在 CPU 间的上下文切换比较敏感,尤其是在发生跨 NUMA 访问时的情况。
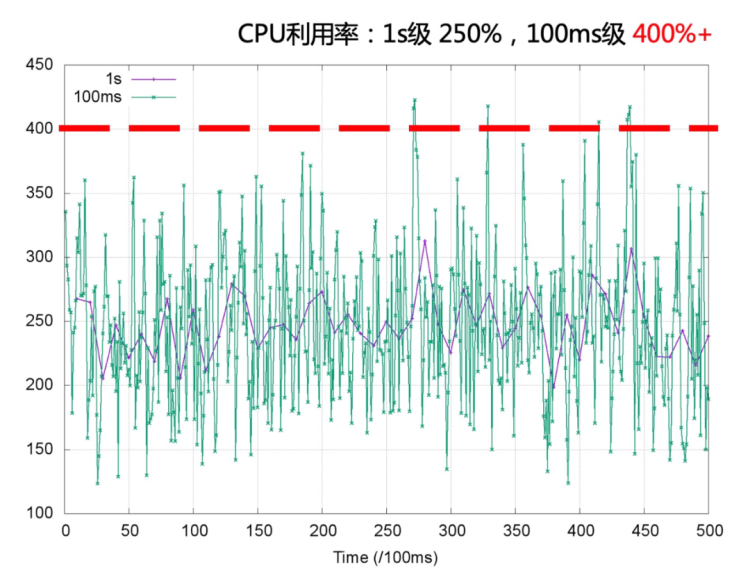
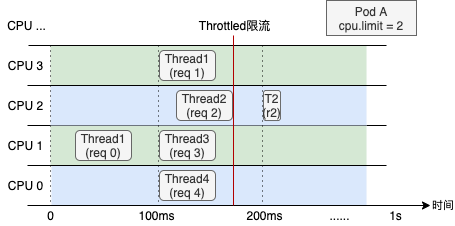
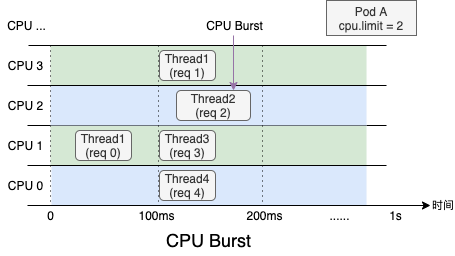
受内核调度控制周期(cfs_period)影响,容器的 CPU 利用率往往具有一定的欺骗性,下图展示了某容器一段时间的 CPU 使用情况(单位为0.01核),可以看到在 1s 级别的粒度下(图中紫色折线),容器的 CPU 用量较为稳定,平均在 2.5 核左右。根据经验,管理员会将 CPU Limit设置为 4 核。本以为这已经保留了充足的弹性空间,然而若我们将观察粒度放大到 100ms 级别(图中绿色折线),容器的 CPU 用量呈现出了严重的毛刺现象,峰值达到 4 核以上。此时容器会产生频繁的 CPU Throttle,进而导致应用性能下降、RT 抖动,但我们从常用的 CPU 利用率指标中竟然完全无法发现!毛刺产生的原因通常是由于应用突发性的 CPU 资源需求(如代码逻辑热点、流量突增等),下面我们用一个具体的例子来描述 CPU Throttle 导致应用性能下降的过程。图中展示了一个CPU Limit = 2 的 Web 服务类容器,在收到请求后(req)各线程(Thread)的 CPU 资源分配情况。假设每个请求的处理时间均为 60 ms,可以看到,即使容器在最近整体的 CPU 利用率较低,由于在 100 ms~200 ms 区间内连续处理了4 个请求,将该内核调度周期内的时间片预算(200ms)全部消耗,Thread 2 需要等待下一个周期才能继续将 req 2 处理完成,该请求的响应时延(RT)就会变长。这种情况在应用负载上升时将更容易发生,导致其 RT 的长尾情况将会变得更为严重。为了避免 CPU Throttle 的问题,我们只能将容器的 CPU Limit 值调大。然而,若想彻底解决 CPU Throttle,通常需要将 CPU Limit 调大两三倍,有时甚至五到十倍,问题才会得到明显缓解。而为了降低 CPU Limit 超卖过多的风险,还需降低容器的部署密度,进而导致整体资源成本上升。
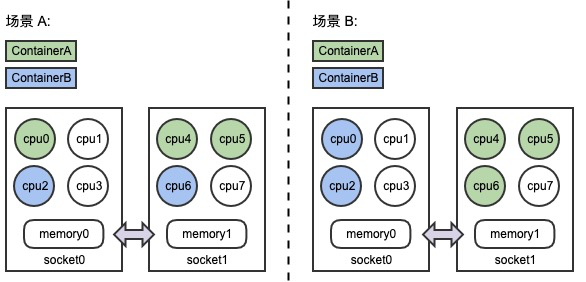
在 NUMA 架构下,节点中的 CPU 和内存会被切分成了两部分甚至更多(例如图中 Socket0,Socket1),CPU 被允许以不同的速度访问内存的不同部分,当 CPU 跨 Socket 访问另一端内存时,其访存时延相对更高。盲目地在节点为容器分配物理资源可能会降低延迟敏感应用的性能,因此我们需要避免将 CPU 分散绑定到多个 Socket 上,提升内存访问时的本地性。如下图所示,同样是为两个容器分配 CPU、内存资源,显然场景B中的分配策略更为合理。Kubelet 提供的 CPU 管理策略 “static policy”、以及拓扑管理策略 “single-numa-node”,会将容器与 CPU 绑定,可以提升应用负载与 CPU Cache,以及 NUMA 之间的亲和性,但这是否一定能够解决所有因 CPU 带来的性能问题呢,我们可以看下面的例子。
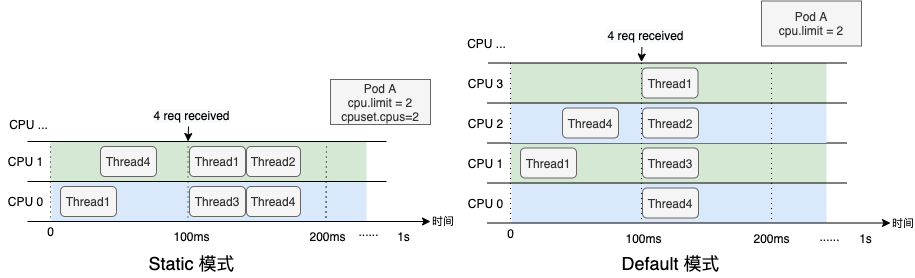
某 CPU Limit = 2 的容器,其应用在 100ms 时间点收到了 4 个请求需要处理,在 Kubelet 提供的 static 模式下,容器会被固定在 CPU0 和 CPU1 两个核心,各线程只能排队运行,而在 Default 模式下,容器获得了更多的 CPU 弹性,收到请求后各线程可以立即处理。可以看出,绑核策略并不是“银弹”,Default 模式也有适合自己的应用场景。
事实上,CPU 绑核解决的是进程在不同 Core,特别是不同 NUMA 间上下文切换带来的性能问题,但解决的同时也损失了资源弹性。在这种情况下线程会在各 CPU 排队运行,虽然 CPU Throttle 指标可能有所降低,但应用自身的性能问题并没有完全解决。往期文章我们介绍了阿里云贡献的 CPU Burst 内核特性,可以有效解决 CPU Throttle 的问题,当容器真实 CPU 资源使用小于 cfs_quota 时,内核会将多余的 CPU 时间“存入”到 cfs_burst 中;当容器有突发的 CPU 资源需求,需要使用超出 cfs_quota 的资源时,内核的 CFS 带宽控制器(CFS Bandwidth Controller,简称 BWC) 会允许其消费其之前存到 cfs_burst 的时间片。CPU Burst 机制可以有效解决延迟敏感性应用的 RT 长尾问题,提升容器性能表现,目前阿里云容器服务 ACK 已经完成了对 CPU Burst 机制的全面支持。对于尚未支持 CPU Burst 策略的内核版本,ACK 也会通过类似的原理,监测容器 CPU Throttle 状态,并动态调节容器的 CPU Limit,实现与内核 CPU Burst 策略类似的效果。
我们使用 Apache HTTP Server 作为延迟敏感型在线应用,通过模拟请求流量,评估 CPU Burst 能力对响应时间(RT)的提升效果。以下数据分别展示了 CPU Burst 策略开启前后的表现情况: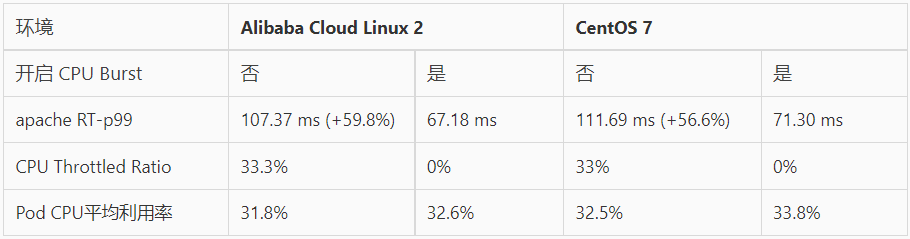
- 在开启 CPU Burst 能力后,应用的 RT 指标的 p99 分位值得到了明显的优化。
- 对比 CPU Throttled 及利用率指标,可以看到开启 CPU Burst 能力后,CPU Throttled 情况得到了消除,同时 Pod 整体利用率基本保持不变。
虽然 Kubelet 提供了单机的资源管理策略(static policy,single-numa-node),可以部分解决应用性能表现受 CPU 缓存、NUMA 亲和性影响的问题,但该策略尚有以下不足之处:- static policy 只支持 QoS 为 Guaranteed 的 Pod,其他 QoS 类型的 Pod 无法使用
- 策略对节点内所有 Pod 全部生效,而我们通过前面的分析知道,CPU 绑核并不是”银弹“
- 中心调度并不感知节点实际的 CPU 分配情况,无法在集群范围内选择到最优组合
阿里云容器服务 ACK 基于 Scheduling framework 实现了拓扑感知调度以及灵活的绑核策略,针对 CPU 敏感型的工作负载可以提供更好的性能。ACK 拓扑感知调度可以适配所有 QoS 类型,并支持在 Pod 维度按需开启,同时可以在全集群范围内选择节点和 CPU 拓扑的最优组合。
通过对 Nginx 服务进行的评测,我们发现在 Intel(104核)、AMD(256核)的物理机上,使用 CPU 拓扑感知调度能够将应用性能提升 22%~43%。
CPU Burst、拓扑感知调度是阿里云容器服务 ACK 提升应用性能的两大利器,它们解决了不同场景下的 CPU 资源管理,可以共同使用。
CPU Burst 解决了内核 BWC 调度时针对 CPU Limit 的限流问题,可以有效提升延时敏感型任务的性能表现。但 CPU Burst 本质并不是将资源无中生有地变出来,若容器 CPU 利用率已经很高(例如大于50%),CPU Burst 能起到的优化效果将会受限,此时应该通过 HPA 或 VPA 等手段对应用进行扩容。
拓扑感知调度降低了工作负载 CPU 上下文切换的开销,特别是在 NUMA 架构下,可以提升 CPU 密集型,访存密集型应用的服务质量。不过正如前文中提到的,CPU 绑核并不是“银弹”,实际效果取决于应用类型。此外,若同一节点内大量 Burstable 类型 Pod 同时开启了拓扑感知调度,CPU 绑核可能会产生重叠,在个别场景下反而会加剧应用间的干扰。因此,拓扑感知调度更适合针对性的开启。