国产数据库乱象
共
3030字,需浏览
7分钟
·
2022-07-27 17:46
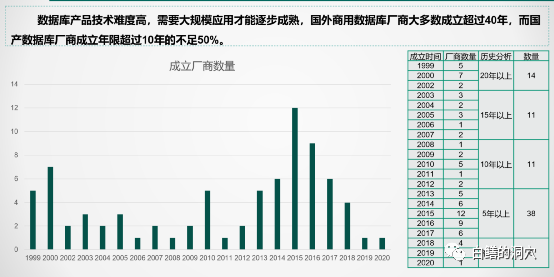
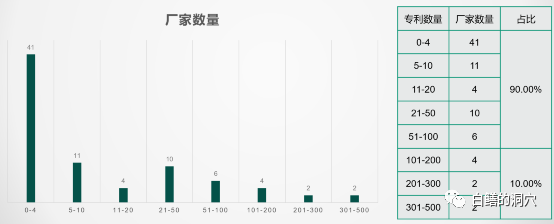
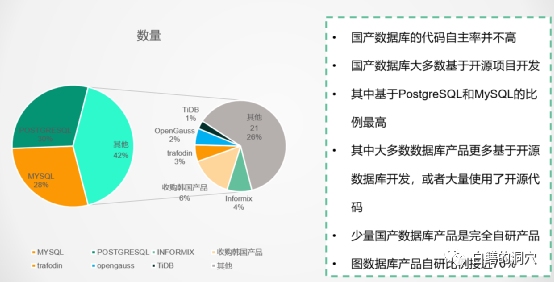
其实这篇文章是我周末开始写的,写这篇文章的这个周末,我的很多时候都是在思考一个数据库国产化替代的建设方案,翻阅了大量的资料。今年正好是我参加工作后的第31个年头,工作的最初十年,我写了十年代码,从汇编、COBOL到C语言,写了几十万行代码;随后的十几年,我一直在帮助用户用好数据库,也在帮助Oracle推广RAC技术;2015年开始,我一边继续从事数据库优化的工作,一边在帮助客户如何从Oracle迁移到成本更低的数据库系统上。所以对国产数据库我一直有一种十分特殊的情感,这是一种爱恨交织的情感。所以今天最后用“乱象”这个题目的时候,还是有些犹豫的,在国产数据库发展如火如荼的时候,泼这盆冷水合适不合适。根据工信部数据库发展白皮书2021的描述,截止2021年6月底,光是国产关系型数据库厂商就已经高达81家,估计马上要发布的2022版里突破100家甚至150家都是很有可能的。相对于十多年前的寥寥数家,这些年国产数据库产业的发展确实是十分迅猛,用野蛮生长来描述也不为过。这些新兴的国产数据库厂商里,也不乏具有相当强大基因,投资巨大,真正认真在做数据库产业的企业,不过大洪水下肯定也会泥沙俱下。原本就起步较晚,人才储备、资金投入都不太足够的国产数据库产业,再被割裂为这么多的细小单位,每个独立个体的真实能力就很值得怀疑了。无论是CPU,服务器,操作系统,中间件这些IT基础设施,投身于IT基础设施中的王冠的企业没想到有这么多,这不知道是中国数据库之幸还是中国数据库的灾难。上周五我在一个沙龙上分享了一些关于基于业务场景的国产数据库选型的演讲,并不是开门见山的去讨论业务场景和数据库选型,而是从对国产数据库厂商的分析开始的。这些分析都是基于工信部的产业发展白皮书的内容。从成立年限上看,我们的国产数据库企业还很年轻,不过成立20年以上的企业还是有十四家,只不过这些企业的这20年并不好过,以数据库产品销售为主业根本生存不下去。因此虽然有20年的历史,实际上真正的历史恐怕要打些折扣的。只看历史可能还无法直接感受到差距,而从从业人数上看,就可以看到国产数据库产业碎片化的恶果了。超过60%的数据库厂商不足100人,而超过500人的企业不足10%。对于想摘取IT基础设施王冠的中国数据库企业,最大的企业的规模可能还不如某个哪怕二三流的国外数据库厂商的一个小研发部门的规模。如果把人员再细化为管理、研发、产品、市场、销售、后勤等部门,恐怕研发人员就更是少的可怜了。据说目前国内最大的数据库厂商的研发人员不足500人,这就是中国数据库企业的现状。如果我们再来看看技术层面的东西,从专利数量上看,90%的数据库企业的数据库领域的专利数少于100件,所有的关系型数据库厂商的专利数加在一起不足4000件,而截止2020年,Oracle公司一家企业的专利数就超过1万4千件。在技术基础薄弱,人才匮乏的情况下,为什么一下子能涌现出如此多的数据库企业和产品呢?从国产数据库的技术来源分析上我们就可以看出一些端倪了。上面这个图表是我们根据收集到的资料自己做的,不一定十分准确,不过可以大体反映出国产数据库的技术来源。大多数是来自于开源项目。因此才会出现大量的规模较小的数据库企业。使用开源技术来发展自己的数据库产业并不是一件坏事,实际上我还是比较赞成的。充分利用开源技术能够加速国产数据库产业的发展,缩短与国外头部企业的差距。不过利用开源技术不等于完全依靠开源技术,而是应该在开源技术基础上进行大量的自主创新,加入自己的技术。比如国内有很多利用PG开源代码的数据库产品,有哪家公司对PG的源码的理解程度,对PG社区的贡献能够达到俄罗斯POSTGRESQLPRO的水平呢?可喜的是,在这种乱象后面我们已经看到了一些数据库厂商开始了自主化的创新,在开源代码的基础上已经走得很远了,我想再有几年的积累,一定会突破开源技术上的某些瓶颈,走出自己的自主化道路。数据库的代码自主化率一直是个迷,如果看工信部的代码自主化测试报告,那么绝大多数号称国产自研的数据库产品都能够拿出很高自主化率的报告来,而且动不动都是95%以上的。我曾经测试过一个号称代码自主化率超过95%的数据库产品,其SQL引擎是完全“兼容”MYSQL的,存储引擎用的不是INNODB。有一次一不小心我把一个不太常用的MYSQL原生态的参数调整了一下,没想到,SQL引擎的工作模式居然按照参数的要求调整了。如果仅仅为了保持MYSQL语法的兼容性的自主化代码,连这种细微之处都模仿的如此完美,那也太牛了吧。虽然国产数据库的专利很少,不过这不影响国产数据库弯道超车,如果不能把Oracle拉出来吊打一番都不好意思说自己是国产数据库。而真实的应用场景下却反映出来我们的国产数据库在CBO和SQL引擎方面与Oracle差距甚大。我也曾经和一些数据库研发人员做过深度交流,他们也承认,要在数据库上缩短与Oracle的差距是十分困难的。无论在人才积累、资金投入和实际应用案例的反馈等方面都存在巨大的差距。特别是第三点,导致Oracle可以不断从生产环境中发现优化器的问题加以改进,而我们甚至都不知道优化器改进的目标,更不要谈从架构上去规划优化器的发展路线了。虽然我们的国产数据库还无法解决用户迫切需要的SQL引擎和优化器的提升,不过并不妨碍我们在其他一些领域上进行创新。在各种宣传资料上,HTAP已经成为了国产数据库的标配功能,不过我想一些国产数据库厂商自己都没几个人真正的懂得什么是HTAP。他们号称的所谓HTAP大多数只是一个OLTP数据库上具有一定的批处理能力而已。OLAP的计算场景和OLTP是完全不同的,OLTP要求资源均衡分配,每次执行的延时稳定并且尽可能段。而OLAP要求的是小并发下的大型甚至巨型计算,利用并行执行充分利用服务器的资源,尽可能把CPU/内存/IO的能力都充分压榨出来,完成复杂的计算,大吞吐量的数据输入和输出。一个连资源隔离都做不好的数据库产品,如何支持HTAP中两种会互相伤害的计算场景呢?我见识过的大多数号称完美解决HTAP问题的数据库产品,实际上都不真正具备可实用的混合负载能力。仅仅是在某些测试环境可以表现出一些能力而已。虽然如此,也并不能阻止HTAP成为很多企业招标中的参数指标,我不知道是采购单位是真正需要这种计算能力,还是仅仅以此来党同伐异的噱头呢?最后一个乱象是评价体系的乱象,每年都会出台各种所谓的国产数据库排行榜,不过这种排行榜似乎有点排排坐吃果果的感觉,第一名和第二十名的评分不超过5分,前几天我看到一个榜单,第一名和第十名的分差只有1分多。如果我是一个企业的IT主管,会有一个感觉,这个榜上的产品,随便选都不会有多大的差别吧。墨天轮有个国产数据库流行度排名,是模仿DBENGINE的,算是目前比较全的常态化榜单了。不过墨天轮上的关于数据库的介绍资料仅仅也就是各个数据库厂商提供的宣传资料,并无相对客观的第三方评价。所有的评价体系和排行榜都是当好好先生的,这很不利用国产数据库的发展。国产数据库现在迎来了最好的发展机遇,我们已经看到了芯片,服务器、安全等领域都在这个机遇到来时显现出了勃勃生机。而在我相对熟悉的数据库领域,我看到的只是一种表面的繁荣,并没有看到一种良性的发展趋势,希望这种局面很快会有所改观,希望国产数据库产业能够异军突起。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报

 下载APP
下载APP