
中国力量在人工智能顶会崛起,这枚NLP“金牌”奥妙何在?

作者 | 青暮
编辑 | 陈彩娴
以学术界为主力军的中国AI研究力量正在悄然变化,工业界的作用愈发凸显,与学术界一起形成双轮驱动之势。
伦敦帝国理工学院 Marek Rei 教授对ML&NLP相关会议论文的统计显示,自2012年至2020年期间,美国以近4000篇论文的数量遥遥领先,中国、英国、德国和加拿大分别名列第二至五位。
美国科技公司在各大人工智能顶会上格外强势,微软和谷歌排名前二,IBM和Facebook也名列前十;与此形成鲜明反差的是,中国AI研究界则由学术机构当家,仅清华和北大跻身前十,分别排名第八和第九位。
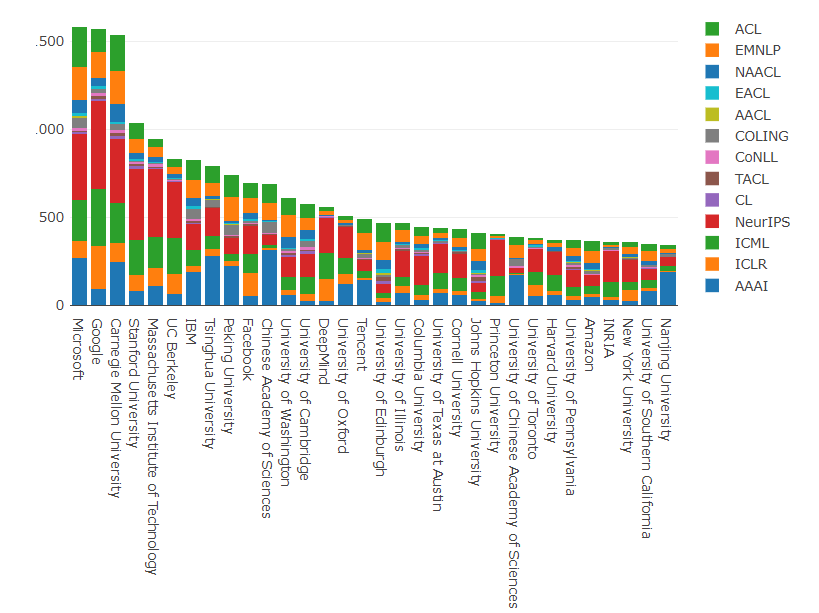
但是在AI技术应用火热的推动下,中国科技企业也逐渐从“辅助角色”进化为中坚力量。在刚刚结束的NLP顶会ACL 2021上,中国的论文投稿数量已经大幅超越美国,共有 1239 篇论文投稿来自中国大陆,其中 251 篇被接收,接收率 20.3%,工业界在其中出力甚多。
更值得欣喜的是,字节跳动AI Lab的词表学习方案VOLT赢得“最佳论文”奖项。这是ACL举办59年以来,中国团队第二次获得会议最高荣誉,上一次是由中科院计算所研究员冯洋获得ACL 2019年最佳长论文奖。此外,香港中文大学与腾讯AI Lab的合作论文成功入选“杰出论文”。
本次我们采访到了字节跳动AI Lab获奖论文作者,向读者介绍他们在ACL 2021上的工作。
1
NLP的华人力量

论文地址:https://arxiv.org/abs/2012.15671
项目地址:https://github.com/Jingjing-NLP/VOLT
2
来自经济学和数学的启发
2
来自经济学和数学的启发



通俗来说,边际收益就是指“刚开始的几口蛋糕真香”以及“最后一口蛋糕好腻”。我们可以把“吃一口蛋糕”定义为投入,“真香感受”定义为产出,边际收益就是投入产出比。“刚开始的几口蛋糕真香”的投入产出比高,“最后一口蛋糕好腻”的投入产出比低。

在子词词表构建中,随着词表大小的增加,一般来说,token的信息熵收益会在某个时刻之后达到巅峰并且下降。
而这个性价比临界点,正是团队要寻找的目标。
因此,团队为了建模这种平衡,引入了边际收益的概念。团队将信息熵看成是边际收益中的利益,词表大小看成是边际收益中的代价。随着词表的增加,不同大小的词表的信息熵收益是不同的。
团队使用边际收益的概念定义了衡量词表质量的指标MUV,并且观测到了MUV指标和下游任务的相关性。
MUV可以理解成为信息熵对词表大小的负一阶导数,也即是我们在逐个增加token来构建词表的时候,每增加一定量的token导致的信息熵增益。我们的目标,就是要在巨大的词表空间中寻找MUV的最高值。
这样就可以把词表学习转化为搜索具有最大MUV分数的词表问题。为了解决该问题,作者提出了一种基于最优运输的方案。
为了便于大家更方便地理解最优运输,这里对最优运输先做一个简单的回顾。
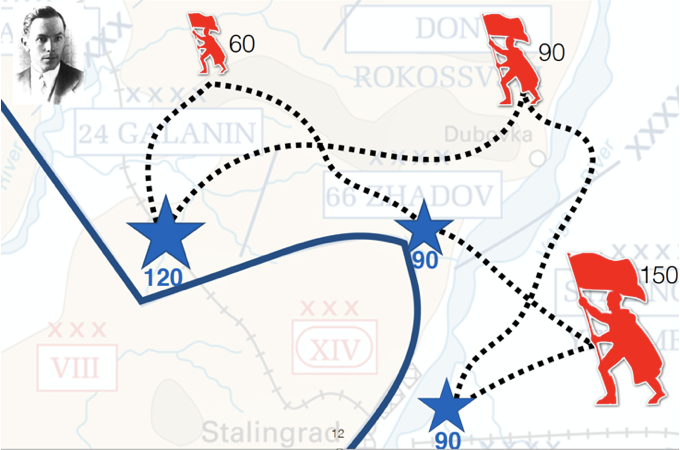
大约250年前,法国数学家蒙日在其作品中对这类问题进行了严格分析,下面是一个比较直观的例子。
假设在战争中,我方有一些前线(蓝色星星)发出了需要增兵的信号,而我们的士兵分散在不同的后方根据地(红色旗帜)。不同的前线需要的士兵个数不同,后方根据地的士兵个数也不同,前线距离后方根据地的距离也不同。问如何设计转移方案,使得总转移代价最低?这就是最优运输想要回答的问题。
那么,如果要用最优传输来解决词表学习问题,首先要将问题进行重建。作者们将句子拆分成字符后的表示看成是后方士兵,将候选词表看成是前线。为了避免不合法的搬运,作者们将不合法的搬运设为无穷大(比如字e搬运给词cat是不合法的)。每种搬运方式对应一种词表,那么我们只需要把搬运代价定义成MUV相关分数,就可以实现搜索的目的。
那么如何将词表学习的问题转化成为最优运输的代价呢?作者对问题进行了简化。简化过程分为两步,一个是对搜索空间进行压缩,一个是对目标进行近似。对技术细节感兴趣的读者,可以看看VOLT方法的伪代码:

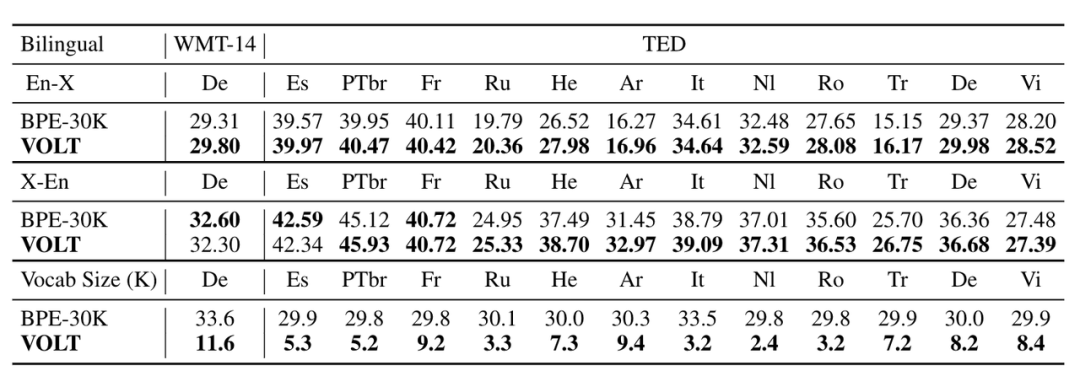
以下是VOLT生成的词表在双语翻译的结果,可以看出新方法学到的词表比经常使用的词表大小小很多,效果也很有竞争力。
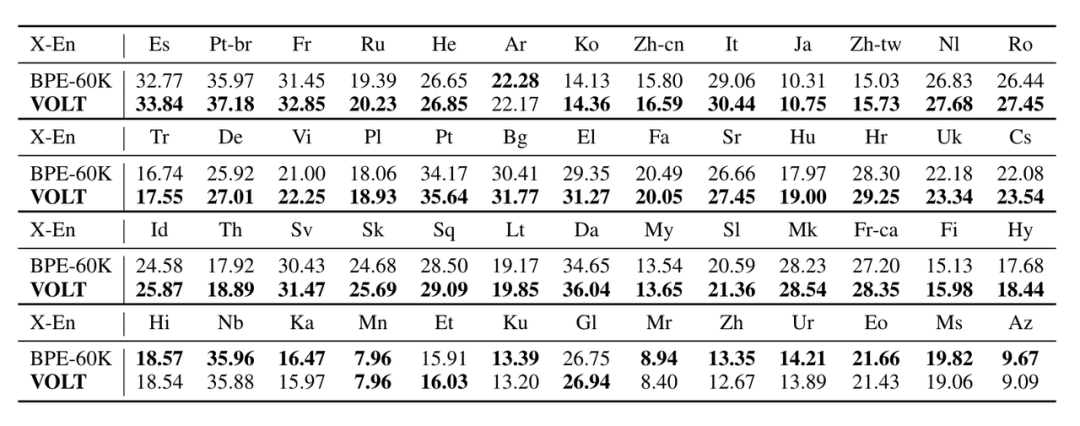
以下是在多语翻译的结果,总体来看,在三分之二的数据集上效果也是较好的。
VOLT不需要结合任务的下游任务训练,因此非常简单高效。但许晶晶转而说道,“这其实是一把双刃剑,如果可以结合下游任务的话,有机会针对特定情况或许可以获得更好的性能和效率。”
3
不止是VOLT
相比于对模型的关注,词表在NLP社区中相关的研究可能少一些,而词表又是非常重要的一环。如何去理解词表其实是一个很有意思的问题。
对于这项工作的泛化性,许晶晶也有所期待,“或许未来能在其他NLP任务上看到VOLT的身影。”
同时,这项技术也被团队用到了竞赛中。在今年的WMT2021中,字节跳动AI Lab在WMT机器翻译比赛中取得了好成绩。这次比赛中,除了VOLT,团队们还使用了非自回归的方法GLAT。

论文链接:https://arxiv.org/abs/2008.07905
在WMT2021国际机器翻译大赛上,字节跳动火山翻译团队以“并行翻译”系统参赛,获得德语到英语方向机器翻译比赛自动评估第一名。“并行翻译”在国际大赛首次亮相,就成功击败了从左向右逐词翻译的“自回归模型”技术,打破后者在机器翻译领域的绝对统治地位。
许晶晶的团队同事周浩说道,“这充分说明并行(非自回归)生成模型未必比自回归模型差”。
WMT2021是由国际计算语言学协会ACL举办的世界顶级机器翻译比赛,德英语向是该赛事竞争最激烈的大语种项目之一。
GLAT被还上线到了字节跳动的火山翻译中,为公司产品和火山引擎的企业级客户提供翻译服务,” 在训练数据量小的场景下,‘并行翻译’的质量相比传统技术处于劣势。但是当训练数据规模变大后,‘并行翻译’会逐渐缩小差距,甚至反超传统技术。“周浩补充道。
火山翻译是字节跳动旗下火山引擎的AI中台能力之一,提供全球先进的翻译技术与服务,打造各大场景智能翻译解决方案。
火山翻译打通了多个翻译场景,包括文本、语音、图片、音频、视频,以及虚拟世界和现实世界。其中,虚拟世界即AR,现实世界即同传。此外还支持多语种,包括56门语言、3080个语向的翻译。
在2021年上半年,火山翻译研发了视频翻译和AR智能翻译眼镜,火山同传也支持了多场大会与直播,很好促进了多语言内容互通。
视频翻译:




在这些产品背后,字节跳动AI Lab重点研发了多语言翻译和语音翻译,有如下几个亮点。
比如开源了 lightseq2.0,这是业界最快的推理和训练引擎,可以把机器翻译的训练速度提升 3 倍,把推理速度提升 10 倍。

以及研发了大规模多语言预训练 mRASP2 ,可以支持 150 个语种之间的互译,通过大规模预训练翻译效果非常好。

还有研发了端到端语音翻译,并且开源了 NeurST,引起了业内较大的关注。

“既重视基础研究,又能高效转化技术。”这也是许晶晶当初选择字节跳动AI Lab的原因,“组里的同事们都很年轻,有活力、有想法,同时氛围又很自由,大家都会积极地去推动整个工作组的研究,并在自己的领域中发光发热。”
许晶晶的主要研究方向是绿色深度学习,VOLT的能力正好定位于这个价值观。
VOLT:绿色环保的词表学习方案
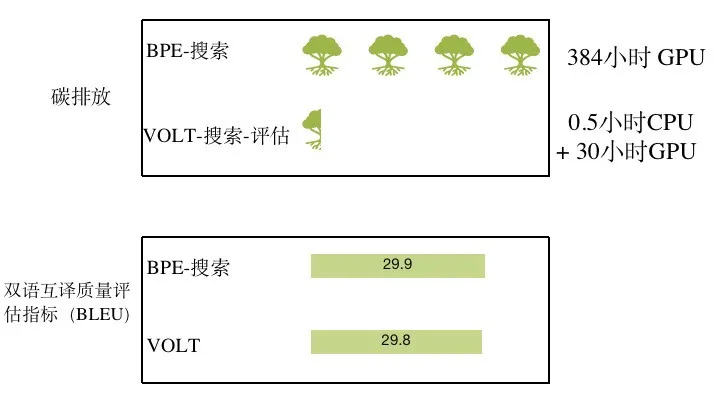
以主流词表BPE为例。为了搜索最优词表,业内普遍会通过大量自然语言处理下游任务的训练以寻找最优大小。相比之下,使用VOLT方案可以节省92%的算力,这同时意味着所需电能的大量减少。
巧合的是,伏特(volt)是电学的一个基本单位。可以说,VOLT是一项非常环保的绿色解决方案。
机器翻译是NLP应用的主要部分,而NLP的市场价值仍然无可限量。John Snow实验室与Gradient Flow合作在2020年发布了一份全球调查报告。这项全球调查询问了来自50多个国家的近600名受访者,全面了解了2020年NLP的采用和实施状况。
尽管今年IT支出不景气,但有趣的是,NLP预算全面增加,报告的NLP技术预算比去年增加了10-30%。考虑到该调查是在全球COVID-19大流行的高峰期进行的,而当时全球的IT支出都在下降,这一点尤其重要。
4
写在最后
“获得最佳论文对于我来说是很高的起点。但人终究是要不断追求进步的,对于下一步该往何处走,做出更好的研究贡献,也会感受到压力。”
展望未来,许晶晶抱有很大的期待,“事物是动态发展的,方向会不断调整,但我相信都会往好的方向发展。对于我个人,也期望在这个自由的环境中,继续做出对公司、对社区、对社会有帮助的事情。字节跳动AI Lab还很年轻,欢迎大家过来开拓自己的事业。”

陌陌十年和其穿越的陌生人社交江湖

挑战苹果三星,Google 手机终于祭出 "大杀器"

P50 系列:华为手机一次悲壮而又辉煌的挣扎