
彻底理解Prometheus查询语法
点击“程序员面试吧”,选择“星标🔝”
“下拉至文末”查看更多


<metric name>{<label name>=<label value>, ...}
^
│ . . . . . . . . . . node_cpu{cpu="cpu0",mode="idle"}
│ . . . . . . . . . . node_cpu{cpu="cpu0",mode="system"}
│ . . . . . . . . . . node_load1{}
v
<------- 时间 ---------->
指标(metric):metric name和描述当前样本特征的labelsets;
时间戳(timestamp):一个精确到毫秒的时间戳;
值(value):表示该时间的样本的值。
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}@1434417560938 => 94355
http_request_total{status="200", method="GET"}@1434417561287 => 94334
http_request_total{status="404", method="GET"}@1434417560938 => 38473
http_request_total{status="404", method="GET"}@1434417561287 => 38544
http_request_total{status="200", method="POST"}@1434417560938 => 4748
http_request_total{status="200", method="POST"}@1434417561287 => 4785

通过使用label=value可以选择那些标签满足表达式定义的时间序列;
反之使用label!=value则可以根据标签匹配排除时间序列。
使用label=~regx表示选择符合正则表达式定义的时间序列;
反之使用label=!~regx进行反向选择。
http_requests_total{environment=~"prodect|test|development",method!="GET"}
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
http_request_total{} # 瞬时向量表达式,选择当前最新的数据
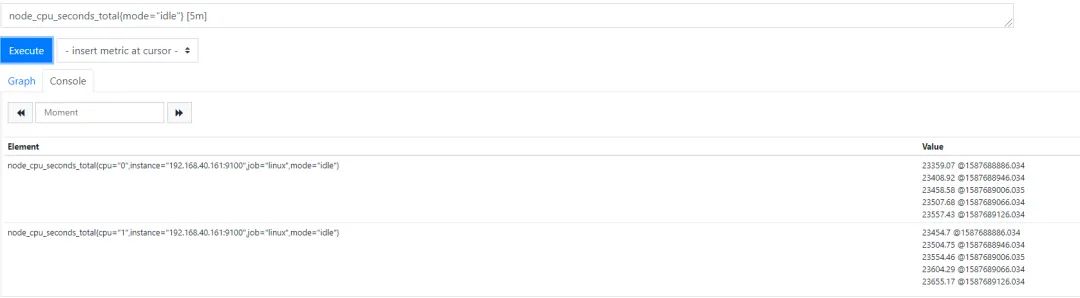
http_request_total{}[5m] # 区间向量表达式,选择以当前时间为基准过去5分钟内的所有数据
http_request_total{} offset 5m
http_request_total{}[1d] offset 1d
http_requests_total{api="/bet“} + http_requests_total{api="/login“} 计算投注和登录请求的和
+(加法)
-(减法)
*(乘法)
/(除法)
%(求余)
^(幂运算)


== (相等)
!= (不相等)
> (大于)
< (小于)
>= (大于等于)
<= (小于)
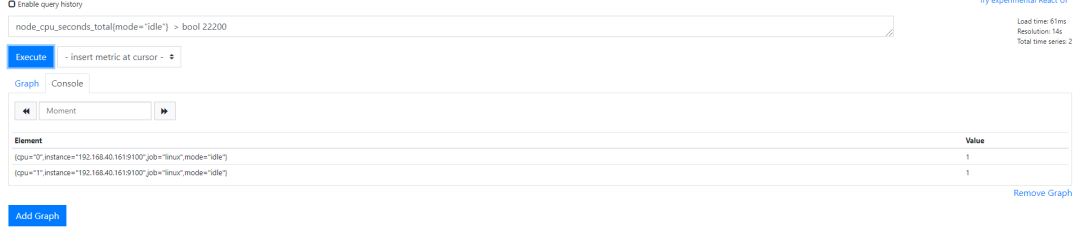
http_requests_total > bool 1000
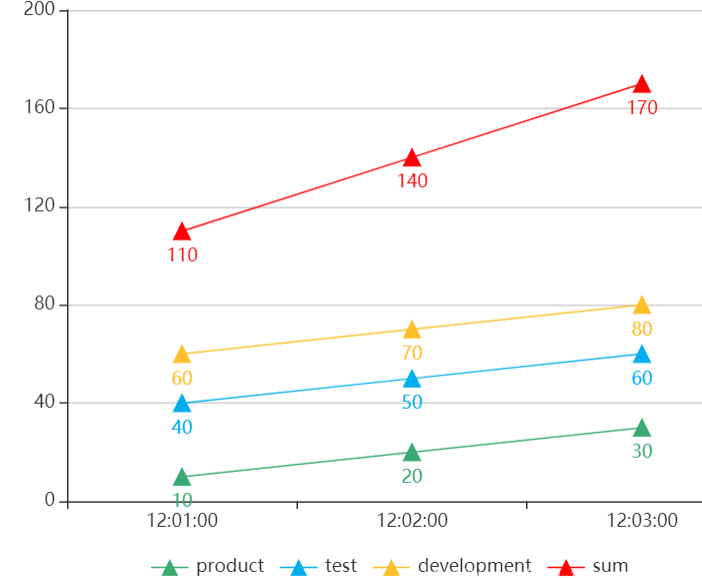
http_requests_total{} 170
http_requests_total{environment="product“} 30
http_requests_total{environment="test“} 60
http_requests_total{environment="developement“} 80
sum:求和
min:最小值
max:最大值
avg:平均值
stddev:标准差
stdvar:方差
count:元素个数
count_values:等于某值的元素个数
bottomk:最小的k个元素
topk:最大的k个元素
quantile:分位数
instant-vector abs(instant-vector):绝对值
instant-vector sqrt(instant-vector):平方根
instant-vector exp(instant-vector):指数计算
instant-vector ln(instant-vector ):自然对数
instant-vector ceil(instant-vector):向上取整
instant-vector floor(instant-vector):向下取整
instant-vector round(instant-vector):四舍五入取整
instant-vector delta(range-vector):计算区间向量里最大最小的差值
instant-vector increase(range-vector):计算区间向量里最后一个值和第一个值的差值
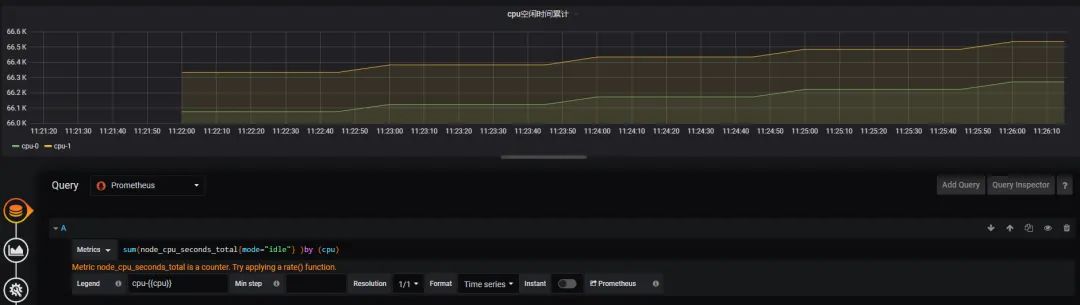
instant-vector rate(range-vector):计算区间向量里的平均增长率
avg_over_time(range-vector):指定间隔内所有点的平均值。
min_over_time(range-vector):指定间隔中所有点的最小值。
max_over_time(range-vector):指定间隔内所有点的最大值。
sum_over_time(range-vector):指定时间间隔内所有值的总和。
rate(http_requests_total[5m])
topk(10, http_requests_total)
node_memory_MemFree
delta(cpu_temp_celsius{host="zeus"}[2h])
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
# HELP prometheus_tsdb_compaction_chunk_range Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range histogram
prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="6400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="25600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="102400"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 0
prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260
prometheus_tsdb_compaction_chunk_range_bucket{le="6.5536e+06"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780
prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780
prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09
prometheus_tsdb_compaction_chunk_range_count 780
# 查询 prometheus_tsdb_compaction_chunk_range 95 百分位
histogram_quantile(0.95, prometheus_tsdb_compaction_chunk_range_bucket)
GET /api/v1/query
query=:PromQL表达式。
time=:指定时间戳。可选参数,默认情况下使用Prometheus当前系统时间。
$ curl 'http://192.168.40.161:9090/api/v1/query?query=node_cpu_seconds_total{mode="idle"}&time=1587690566.034'
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"__name__": "node_cpu_seconds_total",
"cpu": "0",
"instance": "192.168.40.161:9100",
"job": "linux",
"mode": "idle"
},
"value": [
1587690566.034,
"24745.92"
]
},
{
"metric": {
"__name__": "node_cpu_seconds_total",
"cpu": "1",
"instance": "192.168.40.161:9100",
"job": "linux",
"mode": "idle"
},
"value": [
1587690566.034,
"24846.7"
]
}
]
}
}
{
"resultType": "matrix" | "vector",
"result": <value>
}
[
{
"metric": { "<label_name>": "<label_value>", ... },
"value": [ <unix_time>, "<sample_value>" ]
},
...
]
[
{
"metric": { "<label_name>": "<label_value>", ... },
"values": [ [ <unix_time>, "<sample_value>" ], ... ]
},
...
]
$ curl 'http://192.168.40.161:9090/api/v1/query?query=node_cpu_seconds_total{mode="idle"}[5m]&time=1587690566.034'
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "node_cpu_seconds_total",
"cpu": "0",
"instance": "192.168.40.161:9100",
"job": "linux",
"mode": "idle"
},
"values": [
[
1587690266.034,
"24499.47"
],
[
1587690326.034,
"24548.82"
],
[
1587690386.034,
"24598.17"
],
[
1587690446.034,
"24648.21"
],
[
1587690506.034,
"24697.37"
],
[
1587690566.034,
"24745.92"
]
]
},
{
"metric": {
"__name__": "node_cpu_seconds_total",
"cpu": "1",
"instance": "192.168.40.161:9100",
"job": "linux",
"mode": "idle"
},
"values": [
[
1587690266.034,
"24600.32"
],
[
1587690326.034,
"24649.97"
],
[
1587690386.034,
"24698.96"
],
[
1587690446.034,
"24747.99"
],
[
1587690506.034,
"24797.52"
],
[
1587690566.034,
"24846.7"
]
]
}
]
}
}
GET /api/v1/query_range
query=:PromQL表达式。
start=:起始时间。
end=:结束时间。
step=:查询步长。
{
"resultType": "matrix",
"result": <value>
}
$ curl 'http://192.168.40.161:9090/api/v1/query_range?query=node_cpu_seconds_total{mode="idle"}&start=1587693926.035&end=1587694166.034&step=2m'
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "node_cpu_seconds_total",
"cpu": "0",
"instance": "192.168.40.161:9100",
"job": "linux",
"mode": "idle"
},
"values": [
[
1587693926.035,
"27510.45"
],
[
1587694046.035,
"27607.39"
]
]
},
{
"metric": {
"__name__": "node_cpu_seconds_total",
"cpu": "1",
"instance": "192.168.40.161:9100",
"job": "linux",
"mode": "idle"
},
"values": [
[
1587693926.035,
"27645.27"
],
[
1587694046.035,
"27743.97"
]
]
}
]
}
}

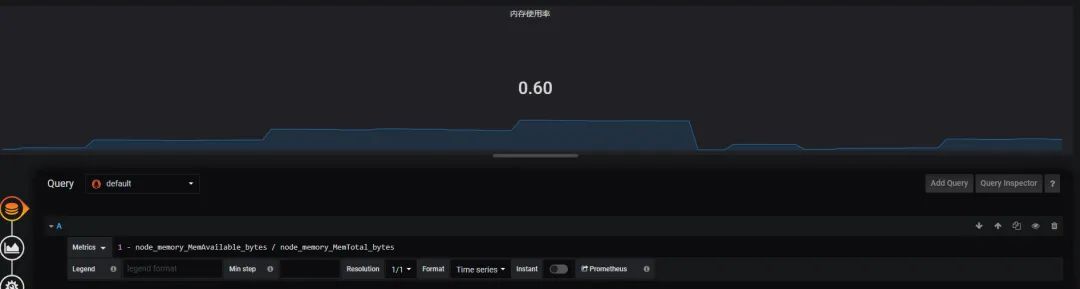
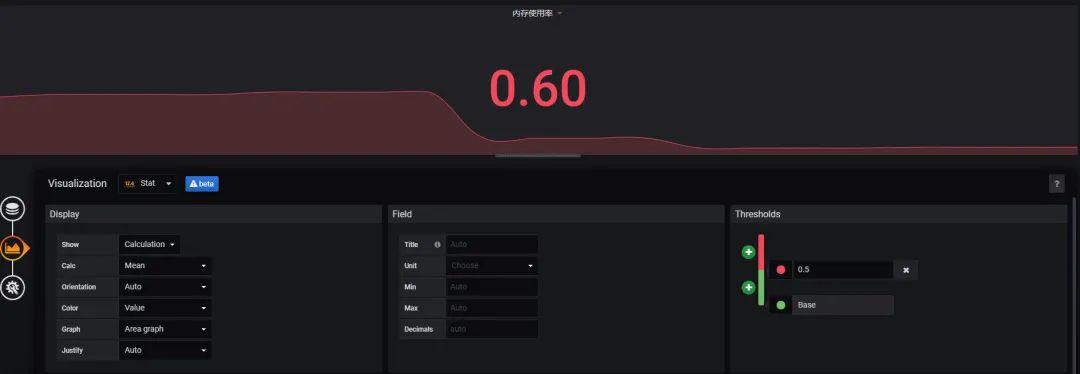
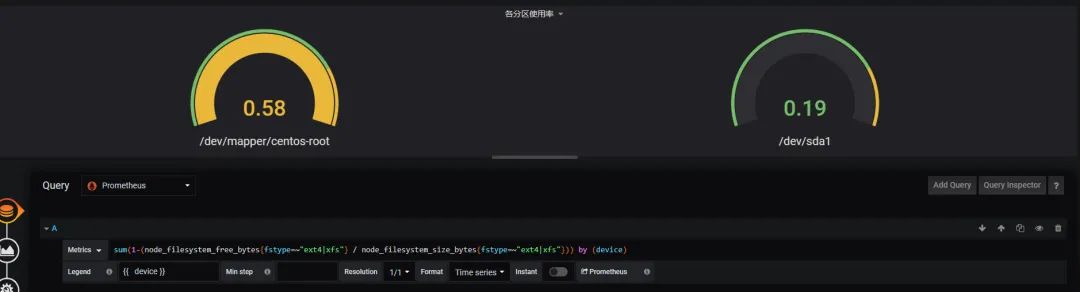
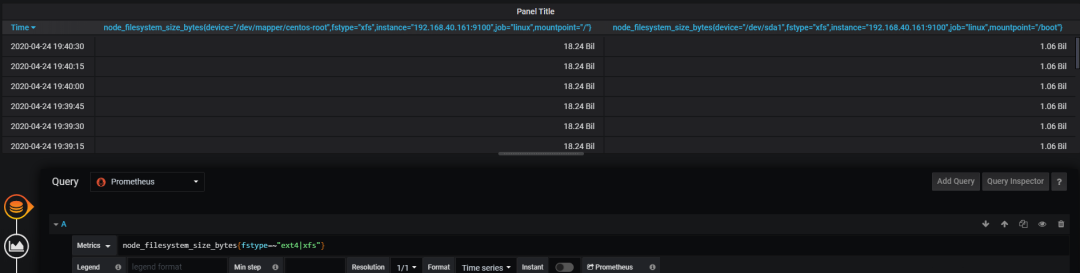


原文链接:https://blog.csdn.net/zhouwenjun0820/article/details/105823389 转自:分布式实验室