
【NLP】今年高考英语AI得分134,复旦武大校友这项研究有点意思
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
在挑战写语文作文后,AI现在又盯上了高考英语。
结果好家伙,今年高考英语卷(全国甲卷)一上手,就拿了134分。

而且不是偶然的超常发挥。
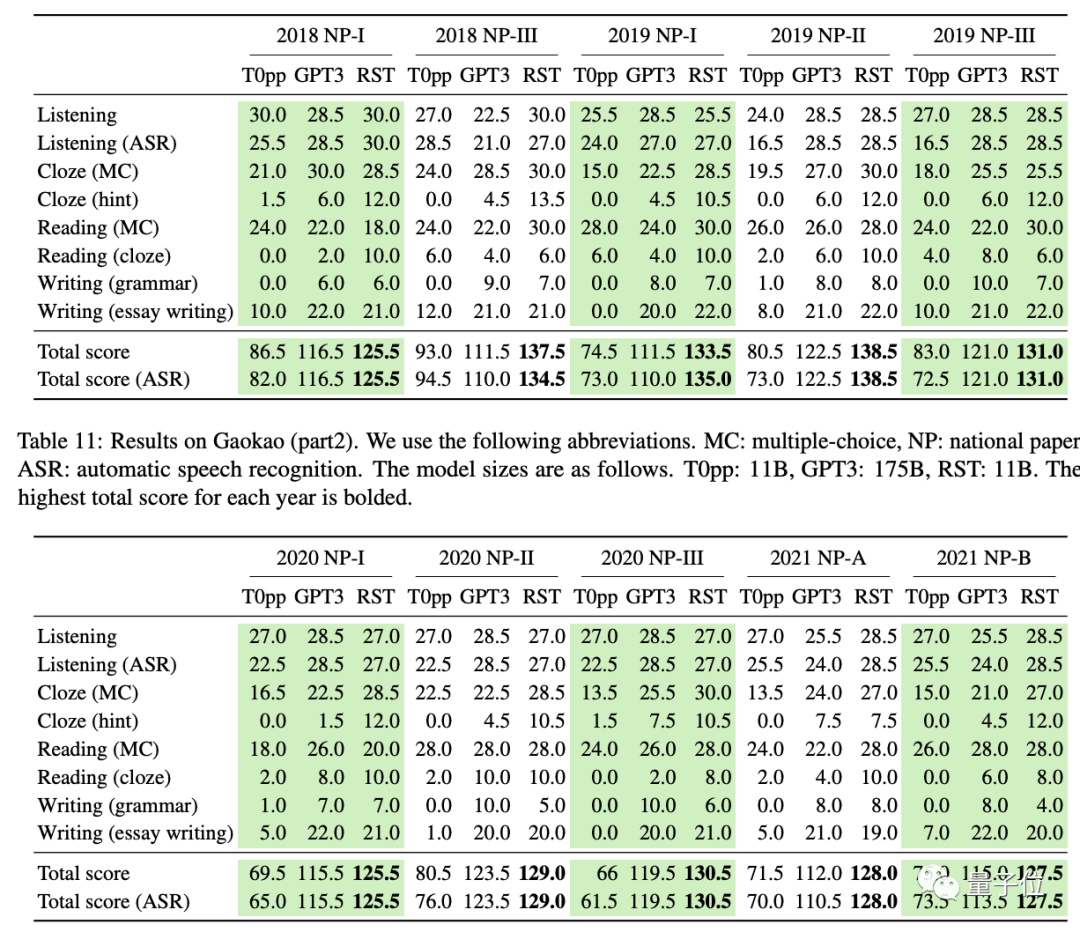
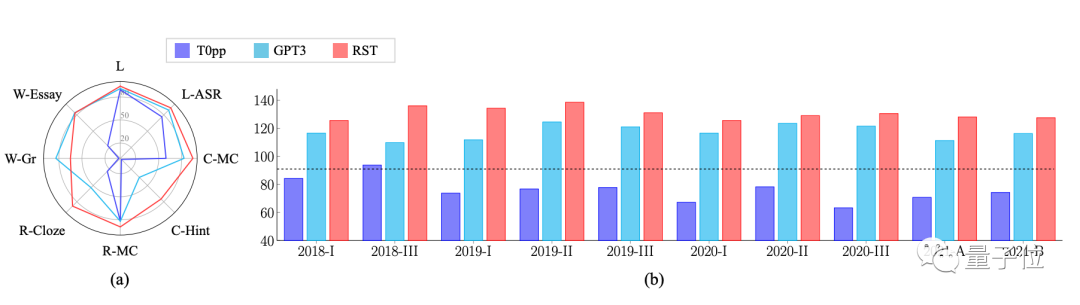
在2018-2021年的10套真题测试中,AI的分数都在125分以上,最高纪录为138.5分,听力和阅读理解还拿过满分。
这就是由CMU学者提出的,高考英语测试AI系统Qin。
它的参数量只有GPT-3的16分之一,平均成绩却比GPT-3高出15分。
其背后的秘诀名叫重构预训练 (reStructured Pre-training),是作者提出的一种新学习范式。
具体来看,就是把维基百科、YouTube等平台的信息重新提取重构,再喂给AI进行训练,由此让AI具有更强的泛化能力。
两位学者用足足100多页的论文,深入解释了这一新范式。

那么,这一范式到底讲了什么?
我们来深扒一下~
什么是重构预训练?
论文题目很简单,就叫reStructured Pre-training(重构预训练,RST)。

核心观点凝练来说就是一句话,要重视数据啊!
作者认为,这个世界上有价值的信息无处不在,而目前的AI系统并没有充分利用数据中的信息。
比如像维基百科,Github,里面包含了各种可以供模型学习的信号:实体,关系,文本摘要,文本主题等。这些信号之前由于技术瓶颈都没有被考虑。
所以,作者在本文中提出了一种方法,可以用神经网络统一地存储和访问包含各种类型信息的数据。
他们以信号为单位、结构化地表示数据,这很类似于数据科学里我们常常将数据构造成表或JSON格式,然后通过专门的语言(如SQL)来检索所需的信息。
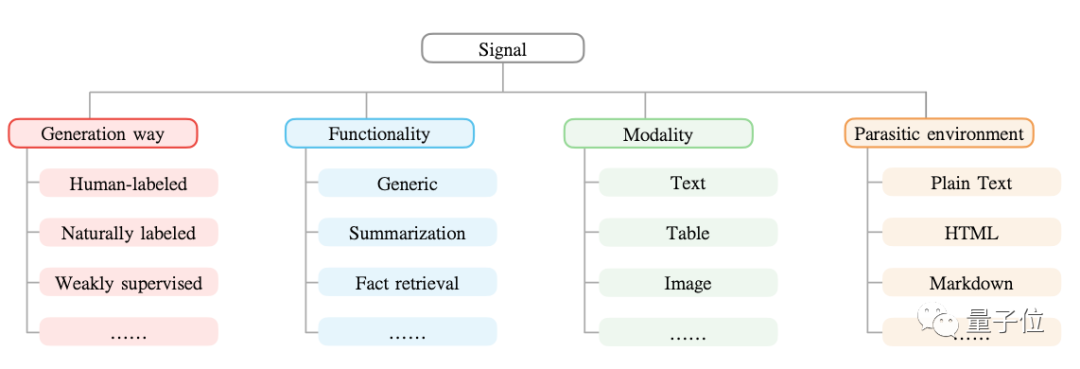
具体来看,这里的信号,其实就是指数据中的有用信息。
比如在“莫扎特生于萨尔茨堡”这句话中,“莫扎特”、“萨尔茨堡”就是信号。
然后,就需要在各种平台上挖掘数据、提取信号,作者把这个过程比作了从矿山里寻宝。

接下来,利用prompt方法,就能将这些来自不同地方的信号统一成一种形式。
最后,再将这些重组的数据集成并存储到语言模型中。
这样一来,该研究就能从10个数据源中,统一26种不同类型的信号,让模型获得很强的泛化能力。
结果表明,在多个数据集中,RST-T、RST-A零样本学习的表现,都优于GPT-3的少样本学习性能。

而为了更进一步测试新方法的表现,作者还想到了让AI做高考题的方法。
他们表示,现在很多工作方法走的都是汉化GPT-3的思路,在评估的应用场景上也是跟随OpenAI、DeepMind。
比如GLUE测评基准、蛋白质折叠评分等。
基于对当下AI模型发展的观察,作者认为可以开辟出一条新的赛道试试,所以就想到了用高考给AI练练手。
他们找来了前后几年共10套试卷进行标注,请高中老师来进行打分。
像听力/识图理解这样的题目,还找来机器视觉、语音识别领域的学者帮忙。
最终,炼出了这套高考英语AI模型,也可以叫她为Qin。
从测试结果可以看到,Qin绝对是学霸级别了,10套卷子成绩都高于T0pp和GPT-3。
此外,作者还提出了高考benchmark。
他们觉得当下很多评价基准的任务都很单一,大多没有实用价值,和人类情况对比也比较困难。
而高考题目既涵盖了各种各样的知识点,还直接有人类分数来做比对,可以说是一箭双雕了。
NLP的第五范式?
如果从更深层次来看,作者认为,重构预训练或许会成为NLP的一种新范式,即把预训练/微调过程视为数据存储/访问过程。
此前,作者将NLP的发展总结成了4种范式:
P1. 非神经网络时代的完全监督学习 (Fully Supervised Learning, Non-Neural Network)
P2. 基于神经网络的完全监督学习 (Fully Supervised Learning, Neural Network)
P3. 预训练,精调范式 (Pre-train, Fine-tune)
P4. 预训练,提示,预测范式(Pre-train, Prompt, Predict)

但是基于当下对NLP发展的观察,他们认为或许之后可以以一种data-centric的方式来看待问题。
也就是,预训/精调、few-shot/zero-shot等概念的差异化会更加模糊,核心只关注一个点——
有价值的信息有多少、能利用多少。
此外,他们还提出了一个NLP进化假说。
其中的核心思想是,技术发展方向总是顺着这样的——做更少的事实现更好、更通用的系统。
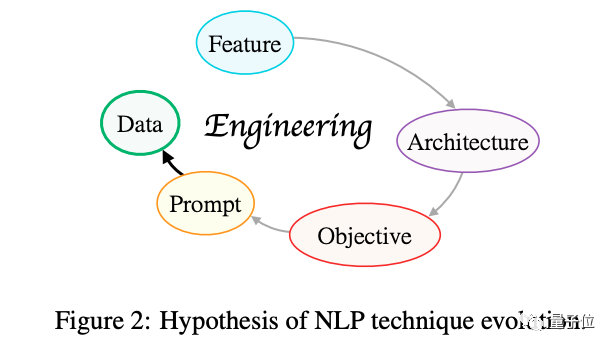
作者认为,NLP经历了特征工程、架构工程、目标工程、提示工程,当下正在朝着数据工程方向发展。
复旦武大校友打造
本篇论文的一作为Weizhe Yuan。
她本科毕业于武汉大学,后赴卡内基梅隆大学读研,学习数据科学专业。
研究方向集中在NLP任务的文本生成和评估。
去年,她被AAAI 2022、NeurIPS 2021分别接收了一篇论文,还获得了ACL 2021 Best Demo Paper Award。

论文的通讯作者为卡内基梅隆大学语言技术研究所(LTI)的博士后研究员刘鹏飞。
他于2019年在复旦大学计算机系获得博士学位,师从邱锡鹏教授、黄萱菁教授。
研究兴趣包括NLP模型可解释性、迁移学习、任务学习等。
博士期间,他包揽了各种计算机领域的奖学金,包括IBM博士奖学金、微软学者奖学金、腾讯人工智能奖学金、百度奖学金。

One More Thing
值得一提的是,刘鹏飞在和我们介绍这项工作时,直言“最初我们就没打算拿去投稿”。
这是因为他们不想让会议论文的格式限制了构思论文的想象力。
我们决定把这篇论文当作一个故事来讲,并给“读者”一种看电影的体验。
这也是为什么我们在第三页,设置了一个“观影模式“的全景图。
就是为了带着大家去了解NLP发展的历史,以及我们所展望的未来是怎样的,让每一个研究者都能有一定的代入感,感受到自己去带领着预训练语言模型们(PLMs)通过矿山寻宝走向更好明天的一个过程。

论文结尾,还藏了一些惊喜彩蛋。
比如PLMs主题表情包:

还有结尾的插画:

这么看,100多页的论文读起来也不会累了 ~
~
论文地址:
https://arxiv.org/abs/2206.11147
— 完 —
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码