
面经:什么是Transformer位置编码?

极市导读
过去的几年里,Transformer大放异彩,在各个领域疯狂上分。它究竟是做什么,面试常考的Transformer位置编码暗藏什么玄机?本文一次性讲解清楚。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Transformer的结构如下:
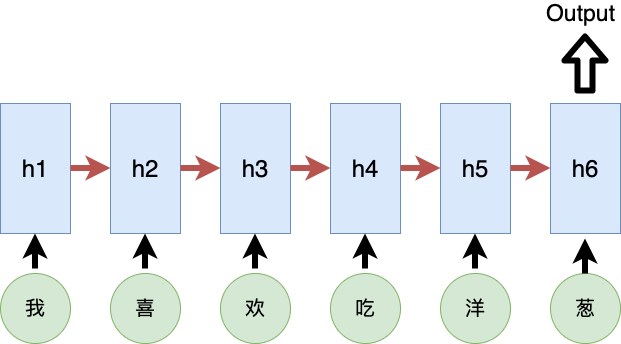
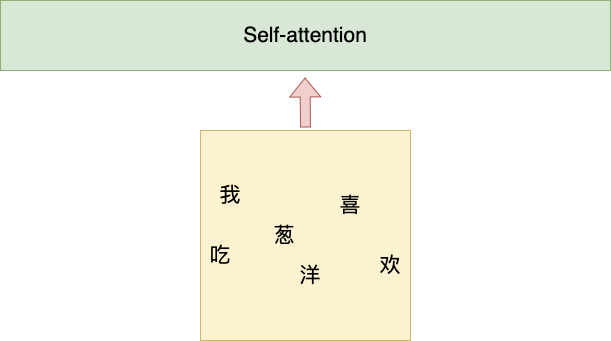
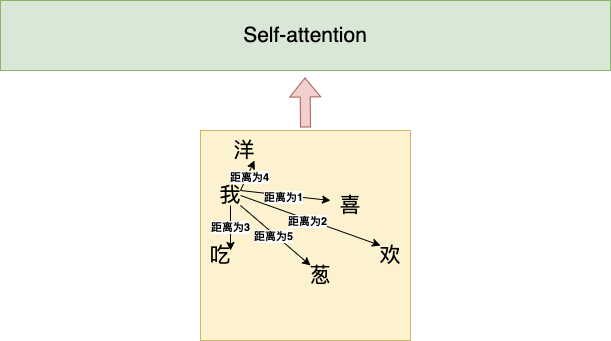
句子1:我喜欢吃洋葱 句子2:洋葱喜欢吃我
位置编码分类
以前的方法-表格型
方法一:使用[0,1]范围分配
我喜欢吃洋葱 【0 0.16 0.32.....1】 我真的不喜欢吃洋葱【0 0.125 0.25.....1】
方法二:1-n正整数范围分配
我喜欢吃洋葱 【1,2,3,4,5,6】 我真的不喜欢吃洋葱【1,2,3,4,5,6,7】
总结
相对位置的关系-函数型
Transformer的Position
类型
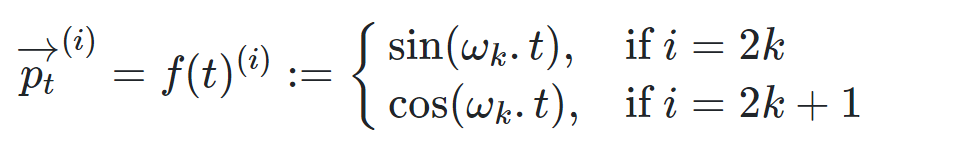
细节:
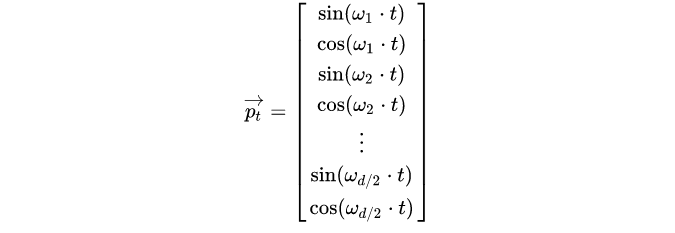
关于每个元素的说明:
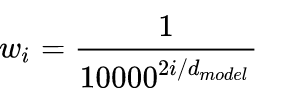
为什么可以表示相对距离?
简单复习
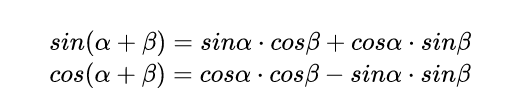
开始证明
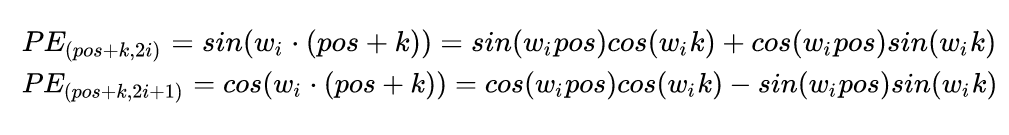
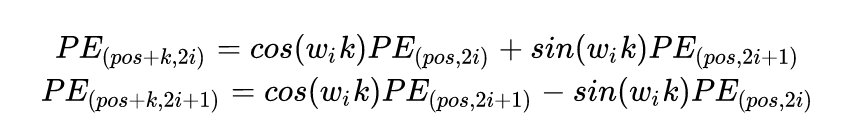
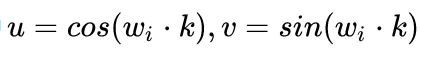
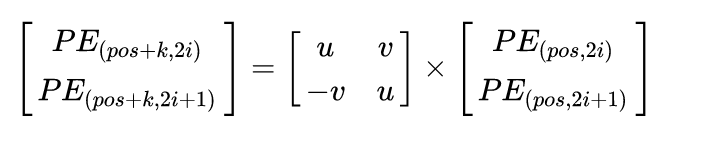
 那么问题来了,上面的操作也只可以看到线性关系,怎么可以更直白地知道每个token的距离关系?
那么问题来了,上面的操作也只可以看到线性关系,怎么可以更直白地知道每个token的距离关系?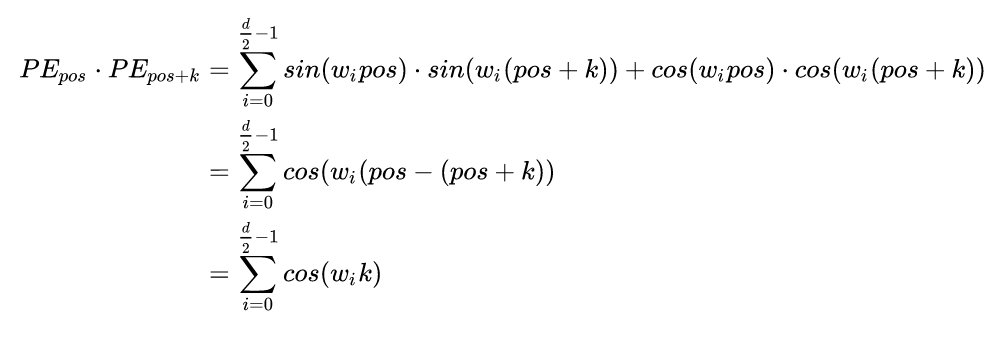
其他
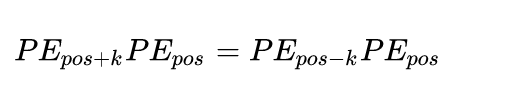
Reference
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论