
【CVPR2024】用于视觉-语言导航的体积环境表示

来源:专知
本文为论文介绍,建议阅读5分钟
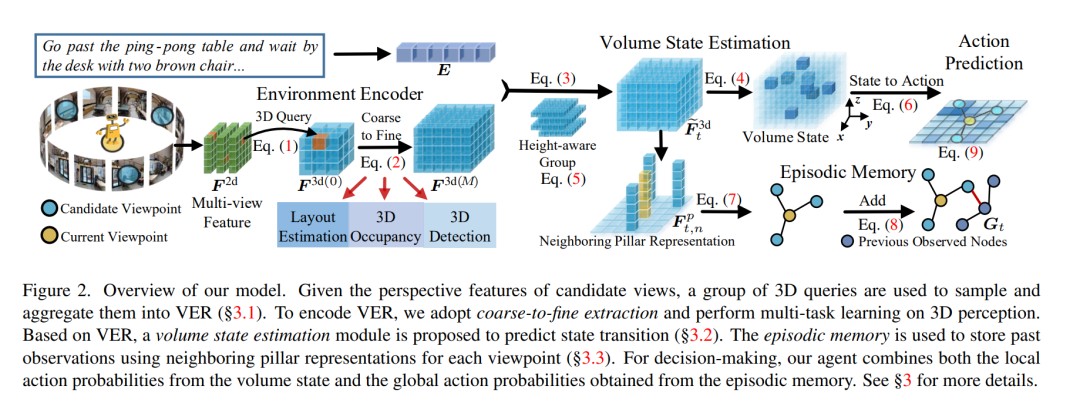
为了实现具有细粒度细节的全面3D表示,我们引入了体积环境表示(VER),该表示将物理世界体素化为结构化的3D单元。

视觉-语言导航(VLN)要求代理基于视觉观察和自然语言指令在3D环境中导航。显然,成功导航的关键因素在于全面的场景理解。之前的VLN代理采用单目框架直接提取透视视图的2D特征。尽管这种方法直接,但它们在捕获3D几何和语义方面存在困难,导致了部分和不完整的环境表示。为了实现具有细粒度细节的全面3D表示,我们引入了体积环境表示(VER),该表示将物理世界体素化为结构化的3D单元。对于每个单元,VER通过2D-3D采样将多视图2D特征聚合到这样一个统一的3D空间中。通过从粗到细的特征提取和对VER的多任务学习,我们的代理联合预测3D占用、3D房间布局和3D边界框。基于在线收集的VER,我们的代理执行体积状态估计并建立情节记忆以预测下一步。实验结果显示,我们从多任务学习中得到的环境表示在VLN上带来了明显的性能提升。我们的模型在VLN基准测试(R2R、REVERIE和R4R)上达到了最先进的性能。
评论