
由 OOM 引发的 ext4 文件系统卡死
注:本问题影响 3.10.0-862.el7.centos 及之后的 CentOS 7 版本内核,目前问题还未被修复。
背景
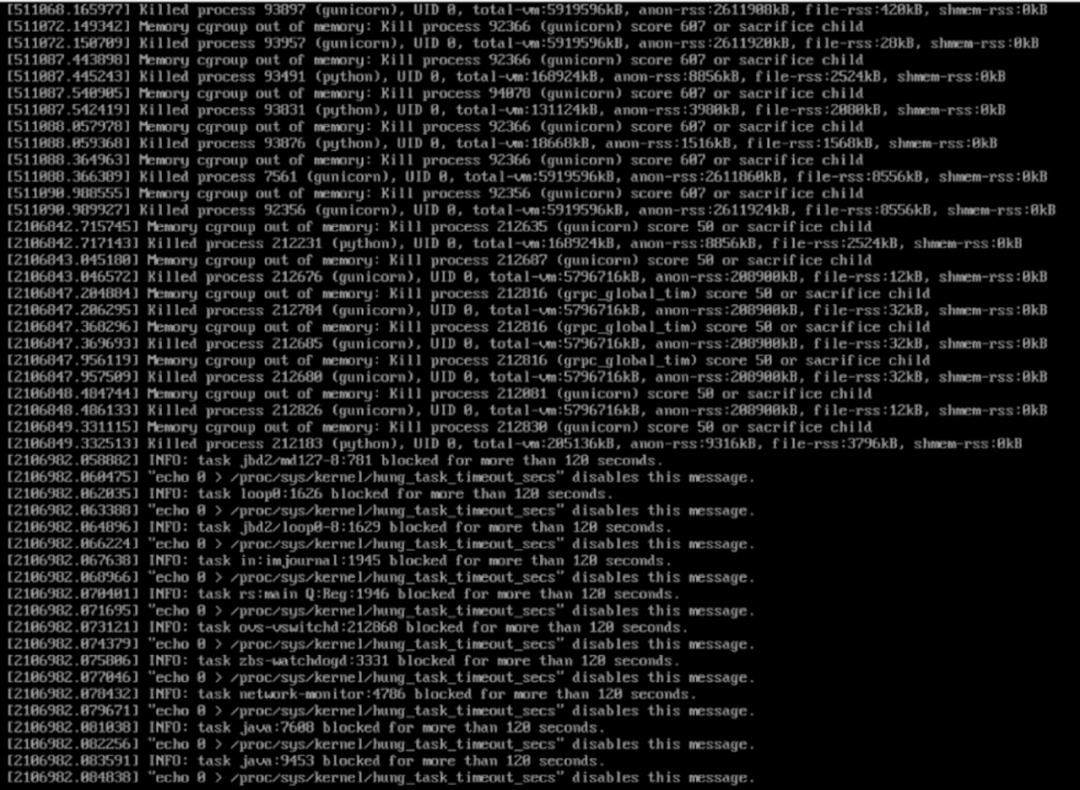
近日,我司的测试同学发现内部集群中一个存储节点无法通过 ssh 访问了。iDRAC console 界面出现如下图的错误:有若干个服务进程由于 cgroup 超过内存限制被 Kill,随后许多进程陆续卡住,出现 “task xxx blocked for more than 120 seconds”。此时,系统无法进行账号登录,似乎整个根文件系统(ext4)都卡住了。测试同学通过 ipmitool 工具发送 NMI 信号让系统产生 vmcore(Linux 内核崩溃时产生的内核转储文件)以便后续分析,然后重启机器让业务恢复。
将多个服务放置在 cgroup 中,限制它们的内存使用量;当内存使用量超过预设上限值,OOM(Out-of-Memory) Killer 按照一定策略 Kill 掉部分进程,实现内存释放。这是很常规的操作,如 Red Hat Enterprise Linux Resource Management Guide - memory(https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/resource_management_guide/sec-memory)。
从内存使用量的监控图表中,我们确定了系统中某个服务存在内存占用随着实例数增加而线性增长的 bug。但是,为什么 OOM 会导致 ext4 文件系统卡死呢?
相关问题检索
从日志和采集到的 vmcore 中,发现有许多进程都卡在 ext4/jbd2 的 I/O 操作上。其中 jbd2 (Journaling block device)是 kernel 中通用的 journal 模块,被 ext4 使用。从日志中可以看出,OOM 后不久就触发许多进程卡住,可以推断 OOM 与 ext4 卡住存在很强的关联性。
为此,找到如下一些 RedHat 官方关于 ext4/jbd2 的 KB,但经过版本和调用栈比对,我们排除了它们,看上去这是一个新的问题。
Hung task "jbd2/dm-16-8" in jbd2_journal_commit_transaction() when issuing I/O through a software RAID or mirror device(https://access.redhat.com/solutions/3226391)
RHEL7: jbd2 deadlock occurs while checkpoint thread waits commit thread to finish(https://access.redhat.com/solutions/4054181).
尝试复现
尝试根据现有线索构建复现脚本,方便后续 debug 分析和假想验证。一旦复现问题,就可以生成 vmcore 做分析。然而,vmcore 只能记录产生 vmcore 时刻的快照信息,犯罪进程可能已经逃离现场,此时更详细的日志可以帮助恢复现场。因此,我们还开启了 jbd2 模块日志功能,重新编译内核。
初次尝试
根据网上一些相似问题的讨论,我们最初的猜想是 cgroup 内的进程在做 ext4 I/O 操作时,可能由于内存限制无法申请到内存后忘记释放文件系统的某些关键资源,导致其他进程(可能是 cgroup 内,也可能不处于 cgroup 中)ext4 I/O 操作无法进行。于是,有了以下复现方法:
在 cgroup 中有两类进程,一类不断分配内存,在 15s 左右达到 cgroup 的内存限制;另一类跑 fio,对 ext4 分区的文件做大块随机写操作。每类进程各 3 个;如果进程被 OOM Kill,会被 systemd 重新拉起; 在 cgroup 之外,有另外 3 个 fio 进程,对 ext4 分区的其他文件做大块随机写操作;
经历了 7 个小时左右,我们复现了一次,卡住现象与最初现场一致。但随后一天中,4 个节点都没法再次复现,需要找到加速复现的方式。
再次尝试
由于前两次复现的场景最后被 OOM Kill 的进程都是 IO 进程,而上述复现步骤中经常被 Kill 的是分配内存的进程,因此考虑做以下调整:
准备一个测试程序 ext4-repro-with-write,打开 ext4 文件系统上的文件,并不断地对该文件做写操作,过程中会涉及到 ext4 inode 内部的一些内存分配操作;测试的 cgroup 中只有这一类进程,OOM Kill 的只可能是这类进程; 创建 10 个 cgroup,每个的内存限制为 100 MB; 对于每个 cgroup,创建 30 个 ext4-repro-with-write 进程;
使用这一脚本,我们能够在 10 分钟以内复现这个问题。相关复现脚本已经上传到 https://gist.github.com/jiewei-ke/4962ac0061703fdcd0837bab2dbec261。
确定影响版本
分别测试 CentOS 7 的几个官方内核版本以及 CentOS 8 的 4.18 内核,我们确定:
CentOS 7 3.10.0-693.el7 版本没有问题; CentOS 7 3.10.0-862.el7 及后续版本(包含最新的 3.10.0-1160.el7)都有问题; CentOS 8 4.18.0 版本没有问题;
即该问题是 CentOS 7 3.10.0-862.el7 引入的。
vmcore 分析
获取到带有 jbd2 模块日志的 vmcore 后,下面使用 crash 工具对其进行分析。
注:分析过程比较冗长,对于 vmcore 分析不感兴趣的同学可以直接跳到 Recap 部分看结论。
ext4/jbd2 简介
参考 Linux: The Journaling Block Device(https://web.archive.org/web/20070926223043/http://kerneltrap.org/node/6741),ext4 文件系统基于 jbd2 以 WAL(write-ahead logging)形式更新元数据,防止系统 crash 时发生元数据损坏。每一个 ext4 文件系统实例对应一个 jbd2 Journal 实例。每个用户线程的一次数据更新称为一个 Handle,在时间上连续的多个 Handle(可能来自不同线程)组成一个 Transaction,以便实现批量提交。Transaction 提交满足原子性。
Journal 包括两个阶段,Commit 和 Checkpoint。Commit 负责提交修改,由用户线程和内核 Journal 线程配合完成。
当用户程序对 ext4 文件系统做文件操作(例如 create())时,用户线程先获取 Handle,然后获取 Journal 当前的 running Transaction,如果存在则使用它,不存在则新创建一个。同时原子增加 running Transaction 的 t_updates 计数,表示该 Transaction 被多少个线程使用。随后,用户线程将修改的元数据内容加入到 Transaction 的 buffer 链表中,递减 t_updates。 内核的 Journal 线程会定期唤醒,将 Journal 的 running Transaction 变为 committing 状态,然后等待 t_updates 归零,即等待用户线程完成插入 buffer 链表。随后将 buffer 链表合并写入到对应的 Journal 区域。随后该 Transaction 加入等待 checkpoint 的 Transaction 列表中。 以上过程中,每个 Journal 实例同时只有一个 running Transaction 和一个 committing Transaction。
Checkpoint 负责持久化修改,由用户线程发起。用户线程从待 checkpoint 的 Transaction 列表中获取 buffer,然后合并写入到物理磁盘,Transaction 至此结束。
以上描述只关注本文涉及到的步骤。更详细的过程请参考 High-Performance Transaction Processing in Journaling File Systems(https://www.usenix.org/system/files/conference/fast18/fast18-son.pdf) 的 Background 部分。
进程堆栈分析
针对 vmcore,通过 crash 命令 ”foreach bt > bt.log“ 获得所有进程的堆栈信息。根据 jbd2 关键字过滤进程,主要有以下几类:
类别 1:内核的 Journal 线程卡在等待 t_updates 归零
上文提到,内核 Journal 线程进行 Commit 之前需要先等待 t_updates 归零。下图的 Journal 线程正是卡在等待 t_updates 归零的循环中,说明此时有一个用户进程正在发起 Commit 操作,但是还没有完成 buffer 链表的更新。
PID: 587 TASK: ffff9f53f8c31070 CPU: 5 COMMAND: "jbd2/md127-8"
#0 [ffff9f53ff35bbf0] __schedule at ffffffffb139e420
#1 [ffff9f53ff35bc88] schedule at ffffffffb139eb09
#2 [ffff9f53ff35bc98] jbd2_journal_commit_transaction at ffffffffc01fe8b0 [jbd2]
#3 [ffff9f53ff35be40] kjournald2 at ffffffffc0205c5e [jbd2]
#4 [ffff9f53ff35bec8] kthread at ffffffffb0cc6bd1
/*
* jbd2_journal_commit_transaction
*
* The primary function for committing a transaction to the log. This
* function is called by the journal thread to begin a complete commit.
*/
void jbd2_journal_commit_transaction(journal_t *journal)
{
// ...
while (atomic_read(&commit_transaction->t_updates)) { <<< 在这循环
DEFINE_WAIT(wait);
prepare_to_wait(&journal->j_wait_updates, &wait,
TASK_UNINTERRUPTIBLE);
if (atomic_read(&commit_transaction->t_updates)) {
spin_unlock(&commit_transaction->t_handle_lock);
write_unlock(&journal->j_state_lock);
schedule();
write_lock(&journal->j_state_lock);
spin_lock(&commit_transaction->t_handle_lock);
}
finish_wait(&journal->j_wait_updates, &wait);
}
类别 2:等待 Transaction Commit 完成的进程
有 3 个进程,它们都在等待 Transaction Commit 的完成。jbd2_log_wait_commit() 正在等待 j_wait_done_commit,该锁正被类别 1 的 Journal 线程持有,只有当 Journal 线程完成 jbd2_journal_commit_transaction() 时,才会释放 j_wait_done_commit。因此,这 3 个进程也是被动卡住的线程,正在等待 Journal 线程。
PID: 27153 TASK: ffff9f53fc35a0e0 CPU: 5 COMMAND: "ext4-repro-with-write"
#0 [ffff9f526e04fd70] __schedule at ffffffffb139e420
#1 [ffff9f526e04fe08] schedule at ffffffffb139eb09
#2 [ffff9f526e04fe18] jbd2_log_wait_commit at ffffffffc02054a5 [jbd2]
#3 [ffff9f526e04fe98] jbd2_complete_transaction at ffffffffc0206e21 [jbd2]
#4 [ffff9f526e04feb8] ext4_sync_file at ffffffffc03cff60 [ext4]
#5 [ffff9f526e04ff00] do_fsync at ffffffffb0e8ccf7
#6 [ffff9f526e04ff40] sys_fsync at ffffffffb0e8cff0
#7 [ffff9f526e04ff50] system_call_fastpath at ffffffffb13ac81e
类别 3:等待 Commit Transaction 的用户进程
这类有 32 个进程,数量比较多,都卡在 jbd2__journal_start() -> wait_transaction_locked() 上,在 Commit Transaction 的早期阶段。这些进程都是被动卡住的,不是事发原因。
PID: 906 TASK: ffff9f53fa13b150 CPU: 5 COMMAND: "loop0"
#0 [ffff9f53fb7cf830] __schedule at ffffffffb139e420
#1 [ffff9f53fb7cf8c8] schedule at ffffffffb139eb09
#2 [ffff9f53fb7cf8d8] wait_transaction_locked at ffffffffc01fb085 [jbd2]
#3 [ffff9f53fb7cf930] add_transaction_credits at ffffffffc01fb360 [jbd2]
#4 [ffff9f53fb7cf990] start_this_handle at ffffffffc01fb63f [jbd2]
#5 [ffff9f53fb7cfa48] jbd2__journal_start at ffffffffc01fbbb6 [jbd2]
#6 [ffff9f53fb7cfa90] __ext4_journal_start_sb at ffffffffc0409c89 [ext4]
#7 [ffff9f53fb7cfad0] ext4_dirty_inode at ffffffffc03dc9da [ext4]
#8 [ffff9f53fb7cfaf0] __mark_inode_dirty at ffffffffb0e87280
#9 [ffff9f53fb7cfb28] update_time at ffffffffb0e7484a
#10 [ffff9f53fb7cfb58] file_update_time at ffffffffb0e74961
#11 [ffff9f53fb7cfba0] __generic_file_aio_write at ffffffffb0dc4eac
#12 [ffff9f53fb7cfc20] generic_file_aio_write at ffffffffb0dc5109
#13 [ffff9f53fb7cfc60] ext4_file_write at ffffffffc03cfb8e [ext4]
#14 [ffff9f53fb7cfcd8] do_sync_write at ffffffffb0e54936
#15 [ffff9f53fb7cfdb0] __do_lo_send_write at ffffffffc0597045 [loop]
#16 [ffff9f53fb7cfdf8] do_lo_send_direct_write at ffffffffc0597156 [loop]
#17 [ffff9f53fb7cfe30] loop_thread at ffffffffc0598382 [loop]
#18 [ffff9f53fb7cfec8] kthread at ffffffffb0cc6bd1
在以上 3 种类别中,类别 1 内核的 Journal 线程卡住是导致其他进程卡住的原因,此时整个 ext4 文件系统的文件操作都无法继续。下面着重分析该进程。
内核的 Journal 线程分析
首先检查当前 Journal 的状况。crash 切换到内核 Journal 线程,显示每个 stack frame 的参数寄存器内容,主要关注 jbd2_journal_commit_transaction()。尝试解析各个地址,发现 ffff9f4539ac9000 能够正确解析为 journal_t 类型(也可以根据反汇编确定参数是如何传递的),拿到 Journal 的指针。
crash> mod -s jbd2
MODULE NAME SIZE OBJECT FILE
ffffffffc02100e0 jbd2 117134 /lib/modules/3.10.0-1.el7.x86_64/kernel/fs/jbd2/jbd2.ko
crash> set 587
PID: 587
COMMAND: "jbd2/md127-8"
TASK: ffff9f53f8c31070 [THREAD_INFO: ffff9f53ff358000]
CPU: 5
STATE: TASK_UNINTERRUPTIBLE
crash> bt
PID: 587 TASK: ffff9f53f8c31070 CPU: 5 COMMAND: "jbd2/md127-8"
#0 [ffff9f53ff35bbf0] __schedule at ffffffffb139e420
#1 [ffff9f53ff35bc88] schedule at ffffffffb139eb09
#2 [ffff9f53ff35bc98] jbd2_journal_commit_transaction at ffffffffc01fe8b0 [jbd2]
#3 [ffff9f53ff35be40] kjournald2 at ffffffffc0205c5e [jbd2]
#4 [ffff9f53ff35bec8] kthread at ffffffffb0cc6bd1
crash> bt -fl
PID: 587 TASK: ffff9f53f8c31070 CPU: 5 COMMAND: "jbd2/md127-8"
#0 [ffff9f53ff35bbf0] __schedule at ffffffffb139e420
...
#1 [ffff9f53ff35bc88] schedule at ffffffffb139eb09
/usr/src/debug/kernel-ml-3.10.0/linux-3.10.0-1.el7.x86_64/kernel/sched/core.c: 3654
ffff9f53ff35bc90: ffff9f53ff35be38 ffffffffc01fe8b0
#2 [ffff9f53ff35bc98] jbd2_journal_commit_transaction at ffffffffc01fe8b0 [jbd2]
…
ffff9f53ff35be10: ffff9f4539ac9028 ffff9f4539ac93e8
ffff9f53ff35be20: ffff9f4539ac90a8 ffff9f53ff35be80
ffff9f53ff35be30: ffff9f4539ac9000 ffff9f53ff35bec0 // 能够正确解析为 Journal 的地址
ffff9f53ff35be40: ffffffffc0205c5e
#3 [ffff9f53ff35be40] kjournald2 at ffffffffc0205c5e [jbd2]
ffff9f53ff35be48: ffff9f5316aa0f62 ffff9f53f8c31070
ffff9f53ff35be58: ffff9f53f8c31070 ffff9f4539ac9090
...
#4 [ffff9f53ff35bec8] kthread at ffffffffb0cc6bd1
/usr/src/debug/kernel-ml-3.10.0/linux-3.10.0-1.el7.x86_64/kernel/kthread.c: 202
crash> journal_t.j_devname ffff9f4539ac9000
j_devname = "md127-8\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"
获取 Journal 的 running Transaction 0xffff9f53d4ec1900,可以看到它的 t_updates 为 1,因此处于循环等待中。
crash> journal_t.j_running_transaction ffff9f4539ac9000
j_running_transaction = 0xffff9f53d4ec1900
crash> transaction_t 0xffff9f53d4ec1900
struct transaction_t {
t_journal = 0xffff9f4539ac9000,
t_tid = 380243810,
t_state = T_LOCKED,
...
t_updates = {
counter = 1 // t_updates 为 1,处于循环等待
},
t_outstanding_credits = {
counter = 56
},
…
}
提交 Transaction 的用户进程分析
t_updates 的更新是由提交 Transaction 的用户进程完成的。下面看一下其更新流程。
t_updates 递增的过程
在 Transaction 被提交前,用户进程会先通过 jbd2__journal_start() 获取当前进程的 Handle,随后调用 start_this_handle() 为 Transaction 预留需要的 Journal 空间。
static inline handle_t *journal_current_handle(void)
{
return current->journal_info;
}
handle_t *jbd2__journal_start(journal_t *journal, int nblocks, int rsv_blocks,
gfp_t gfp_mask, unsigned int type,
unsigned int line_no)
{
handle_t *handle = journal_current_handle(); // 获取进程的 Handle
...
err = start_this_handle(journal, handle, gfp_mask);
在 start_this_handle() 中,我们看到 Handle 中保存了 running Transaction 的指针,同时 Transaction 的 t_updates 被原子加一。
static int start_this_handle(journal_t *journal, handle_t *handle,
gfp_t gfp_mask)
{
...
transaction = journal->j_running_transaction;
...
update_t_max_wait(transaction, ts);
handle->h_transaction = transaction;
handle->h_requested_credits = blocks;
handle->h_start_jiffies = jiffies;
atomic_inc(&transaction->t_updates);
atomic_inc(&transaction->t_handle_count);
t_updates 递减的过程
相对应的,Transaction 的 t_updates 是由 jbd2_journal_stop 中递减的。
int jbd2_journal_stop(handle_t *handle)
{
...
/*
* Once we drop t_updates, if it goes to zero the transaction
* could start committing on us and eventually disappear. So
* once we do this, we must not dereference transaction
* pointer again.
*/
tid = transaction->t_tid;
if (atomic_dec_and_test(&transaction->t_updates)) {
wake_up(&journal->j_wait_updates);
if (journal->j_barrier_count)
wake_up(&journal->j_wait_transaction_locked);
}
t_updates 为何没有归零?
我们找一下是否有 Handle 持有着这个 Transaction。事先添加的 jbd2 模块日志会打印出 Handle 相关日志,检索日志中曾经出现过的 Handle 指针如下,
$ grep jbd2_journal_stop vmcore-dmesg.txt | grep Handle | awk '{print $7}' | sort | uniq
...
ffff9f53f9676cf0
ffff9f53fa89bb70
ffff9f53fe3423c0
逐个尝试解析 Handle,发现 Handle ffff9f53fa89bb70 正在处理上述的 Transaction 0xffff9f53d4ec1900。其中,h_line_no 为 2264,即该 Handle 是在行号为 2264 的代码启动的(但没有包含文件名信息)。
crash> handle_t ffff9f53fa89bb70
struct handle_t {
{
h_transaction = 0xffff9f53d4ec1900,
h_journal = 0xffff9f53d4ec1900 // 这里好像填错了,跟 transaction 是一样的。。
},
h_rsv_handle = 0x0,
h_buffer_credits = 33,
h_ref = 1,
h_err = 0,
h_sync = 0,
h_jdata = 0,
h_reserved = 0,
h_aborted = 0,
h_type = 4,
h_line_no = 2264,
h_start_jiffies = 4298558935,
h_requested_credits = 35
}
在 ext4 代码中,发现 ext4_create() 中调用 ext4_new_inode_start_handle() 的行号正好与之匹配。根据代码,ext4_new_inode_start_handle() 会调用 jbd2__journal_start() 将 t_updates 加一,然后将 inode 元数据信息更新加入 Transaction。之后,ext4_create() 调用 ext4_journal_stop() 将 t_updates 减一。
static int ext4_create(struct inode *dir, struct dentry *dentry, umode_t mode,
bool excl)
{
handle_t *handle;
struct inode *inode;
int err, credits, retries = 0;
dquot_initialize(dir);
credits = (EXT4_DATA_TRANS_BLOCKS(dir->i_sb) +
EXT4_INDEX_EXTRA_TRANS_BLOCKS + 3);
retry:
inode = ext4_new_inode_start_handle(dir, mode, &dentry->d_name, 0,
NULL, EXT4_HT_DIR, credits); // 在这里卡住了
handle = ext4_journal_current_handle();
err = PTR_ERR(inode);
if (!IS_ERR(inode)) {
inode->i_op = &ext4_file_inode_operations;
inode->i_fop = &ext4_file_operations.kabi_fops;
ext4_set_aops(inode);
err = ext4_add_nondir(handle, dentry, inode);
if (!err && IS_DIRSYNC(dir))
ext4_handle_sync(handle);
}
if (handle)
ext4_journal_stop(handle); // 还没有调用
if (err == -ENOSPC && ext4_should_retry_alloc(dir->i_sb, &retries))
goto retry;
return err;
}
t_updates 没有归零,说明 ext4_journal_stop() 没有调用。如果 Handle 还没有执行 jbd2_journal_stop(),那么它会被某个进程所持有,保存在进程控制块 task_struct 的 journal_info 中。通过搜索所有进程的 task_struct,可以看到 task 27225(我们的测试程序 ext4-repro-with-write)进程正在持有这个 Handle。
crash> foreach task > task.log
crash> task 27225 | grep journal_info
journal_info = 0xffff9f53fa89bb70,
crash> ps | grep 27225
27225 1 4 ffff9f533a6d3150 RU 0.0 239712 38800 ext4-repro-with-write
crash> bt 27225
PID: 27225 TASK: ffff9f533a6d3150 CPU: 4 COMMAND: "ext4-repro-with-write"
#0 [ffff9f53c234f900] __schedule at ffffffffb139e420
#1 [ffff9f53c234f990] sys_sched_yield at ffffffffb0cdafdc
#2 [ffff9f53c234f9b0] yield at ffffffffb139fca2
#3 [ffff9f53c234f9c8] free_more_memory at ffffffffb0e8ee2c
#4 [ffff9f53c234fa08] __getblk at ffffffffb0e90013
#5 [ffff9f53c234fa70] __ext4_get_inode_loc at ffffffffc03d358f [ext4]
#6 [ffff9f53c234fad8] ext4_reserve_inode_write at ffffffffc03d8e62 [ext4]
#7 [ffff9f53c234fb08] ext4_mark_inode_dirty at ffffffffc03d8f23 [ext4]
#8 [ffff9f53c234fb60] ext4_ext_tree_init at ffffffffc04038ba [ext4]
#9 [ffff9f53c234fb70] __ext4_new_inode at ffffffffc03d271b [ext4]
#10 [ffff9f53c234fc18] ext4_create at ffffffffc03e3fb3 [ext4]
#11 [ffff9f53c234fc90] vfs_create at ffffffffb0e62aa8
#12 [ffff9f53c234fcc8] do_last at ffffffffb0e67e5f
#13 [ffff9f53c234fd70] path_openat at ffffffffb0e681e0
#14 [ffff9f53c234fe08] do_filp_open at ffffffffb0e69d6d
#15 [ffff9f53c234fee0] do_sys_open at ffffffffb0e5442e
#16 [ffff9f53c234ff40] sys_openat at ffffffffb0e54504
#17 [ffff9f53c234ff50] system_call_fastpath at ffffffffb13ac81e
ext4-repro-with-write 进程处于 RUNNING 状态,正在执行 ext4_create -> ext4_new_inode_start_handle -> __ext4_new_inode,此时 t_updates 已经加一,但是由于 ext4_new_inode_start_handle() 还没有结束,后续的 ext4_journal_stop() 也没有执行,故 t_updates 没有归零。
问题出在 ext4_new_inode_start_handle(),如果 __get_blk() 获取不到内存时,会不断地尝试调用 free_more_memory() 释放掉部分内存(事实证明释放并没有成功),然后再尝试获取。如果一直获取不到,那么将会卡在这里。
get_blk 为何分配不到内存?
与前文的复现脚本略微有些差异,这个测试中 ext4-repro-with-write 内部包含两个线程,一个负责不断分配内存,另一个负责持续写文件。在内存限制为 900MB 左右的 cgroup 中启动了 3 个进程。
$cat /etc/systemd/system/system-fio.slice.d/50-MemoryLimit.conf
[Slice]
MemoryLimit=973741824
>>> 973741824/1024.0/1024
928.632568359375 // 900MB 左右
按照 task group 方式检查当前 3 个 ext4-repro-with-write 进程的内存使用量,可以看到内存使用已经接近 cgroup 内存限制,提交 Transaction 的 task 27225 所在的 group 只占用了 37 MB,而另外两个进程各自占用 400 MB 以上。
crash> ps -G ext4-repro-with-write | sed 's/>//g' | sort -k 8,8 -n | awk '$8 ~ /[0-9]/{ $8 = $8/1024" MB"; print }'
27222 1 5 ffff9f53b5b9b150 RU 0.0 239712 37.8906 MB ext4-repro-with-write // 27225 所在的 group
27189 1 5 ffff9f52357c1070 IN 0.3 578292 403.246 MB ext4-repro-with-write
27153 1 5 ffff9f53fc35a0e0 UN 0.4 848900 487.488 MB ext4-repro-with-write // 需要被 Kill 的进程
>>> 37.8906+403.246+487.488
928.6246
从 vmcore-dmesg 日志看,最近一次触发 OOM Kill 的进程是 27153 ,但是内存并没有降下来。
[ 3891.873807] Memory cgroup out of memory: Kill process 27158 (ext4-repro-with-write) score 511 or sacrifice child
[ 3891.875313] Killed process 27153 (ext4-repro-with-write), UID 0, total-vm:848900kB, anon-rss:499124kB, file-rss:868kB, shmem-rss:0kB
看一下 27153 进程,处于 UN 状态而无法接受 Kill 信号,所以内存不可能得到释放。
crash> ps ext4-repro-with-write
PID PPID CPU TASK ST %MEM VSZ RSS COMM
27153 1 5 ffff9f53fc35a0e0 UN 0.4 848900 499188 ext4-repro-with-write
如下图,该进程属于上述类型 2 的进程,它正在等到内核 Journal 线程完成 Commit,死锁条件成立。
crash> bt 27153
PID: 27153 TASK: ffff9f53fc35a0e0 CPU: 5 COMMAND: "ext4-repro-with-write"
#0 [ffff9f526e04fd70] __schedule at ffffffffb139e420
#1 [ffff9f526e04fe08] schedule at ffffffffb139eb09
#2 [ffff9f526e04fe18] jbd2_log_wait_commit at ffffffffc02054a5 [jbd2]
#3 [ffff9f526e04fe98] jbd2_complete_transaction at ffffffffc0206e21 [jbd2]
#4 [ffff9f526e04feb8] ext4_sync_file at ffffffffc03cff60 [ext4]
#5 [ffff9f526e04ff00] do_fsync at ffffffffb0e8ccf7
#6 [ffff9f526e04ff40] sys_fsync at ffffffffb0e8cff0
#7 [ffff9f526e04ff50] system_call_fastpath at ffffffffb13ac81e
Recap
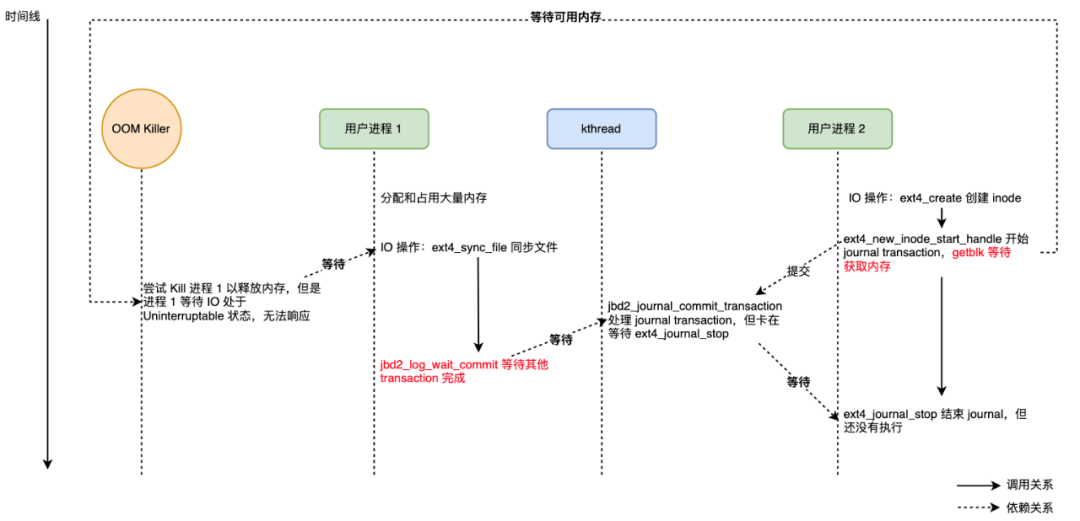
根据以上冗长的分析,OOM 导致 ext4 文件系统死锁的时间线整理如下:
系统内有两个用户进程,位于同一个 cgroup 中,cgroup 上限制最大可用的内存; 进程 1,分配大量内存,使得 cgroup 内存使用量超过限制,OOM Killer 选择该进程杀死;该进程正在执行 ext4_sync_file(),在 jbd2_log_wait_commit() 等待进程 2 的 Transaction 完成;此时该进程处于不可中断状态,无法被 Kill,内存无法被释放; 进程 2,处于 ext4_create()(或者其他 ext4_xxx 函数)中,在 __getblk() 上等待可用的内存;只有拿到足够内存,才能完成 ext4_journal_stop(),将 t_updates 递减,其对应的内核 Journal 线程才能完成 jbd2_journal_commit_transaction(); (死锁条件 1)进程 1 在等待进程 2 的 Transaction Commit 完成才能被 Kill 而释放内存;(死锁条件 2)进程 2 在等待进程 1 的释放内存才能拿到内存完成 Transaction Commit。
解决方案
在上述两个死锁条件中,只要我们破坏一个条件就可以避免死锁发生。条件 1 是 jbd2 的实现要求,我们难以改变;条件 2 则有可能打破,例如,针对这种关键路径上的内存分配,允许 cgroup 的内存暂时超过限制。
Linux VMM(Virtual Memory Manager)提供了 Get Free Page(GFP)Flags 来控制分配器的分配、释放行为。其中有一个 Flag 名为 __GFP_NOFAIL,在 2.6 内核版本加入,其作用是 “This flag is used by a caller to indicate that the allocation should never fail and the allocator should keep trying to allocate indefinitely”。根据代码确认,如果分配内存时 gfp_mask 携带了 __GFP_NOFAIL,那么 VMM 会尽量满足分配需求,不再理会 cgroup 的内存限制。更详细的 GFP 说明请参考 Understanding the Linux Virtual Memory Manager: 6.4 Get Free Page (GFP) Flags(https://www.kernel.org/doc/gorman/html/understand/understand009.html#Sec:%20GFP%20Flags)。
我们看一下 __getblk() 的函数调用链,关键的函数如下,
__getblk
->__getblk_slow
->grow_buffers
->grow_dev_page
->find_or_create_page
->add_to_page_cache_lru
->__add_to_page_cache_locked
-> mem_cgroup_cache_charge
-> ...
->__mem_cgroup_try_charge
如下代码所示,grow_dev_page() 在调用 find_or_create_page() 之前已经携带了 __GFP_NOFAIL,按理来说,后续的内存分配就不会受到 cgroup 限制了(__mem_cgroup_try_charge() )。但为什么 __getblk() 还是没有成功呢?
static int
grow_dev_page(struct block_device *bdev, sector_t block,
pgoff_t index, int size, int sizebits)
{
...
gfp_mask = mapping_gfp_mask(inode->i_mapping) & ~__GFP_FS;
gfp_mask |= __GFP_MOVABLE;
/*
* XXX: __getblk_slow() can not really deal with failure and
* will endlessly loop on improvised global reclaim. Prefer
* looping in the allocator rather than here, at least that
* code knows what it's doing.
*/
gfp_mask |= __GFP_NOFAIL;
page = find_or_create_page(inode->i_mapping, index, gfp_mask);
if (!page)
return ret;
__GFP_NOFAIL 丢失
上文提到,3.10.0-862.el7.centos 是引入该问题的版本。我们对照 3.10.0-693.el7.centos 和 3.10.0-862.el7.centos 两个版本在上述路径上的代码差异,发现后者在函数 __add_to_page_cache_locked() 中,增加了以下代码。mapping_gfp_constraint() 会将传递的 gfp_mask 与 inode->i_mapping 支持的 flags 进行按位与操作。根据 vmcore 分析,确认 inode->i_mapping 是不支持 __GFP_NOFAIL 的,因此上层传递的 __GFP_NOFAIL 丢失了!
static int __add_to_page_cache_locked(struct page *page,
struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask,
void **shadowp)
{
...
gfp_mask = mapping_gfp_constraint(mapping, gfp_mask);
error = mem_cgroup_cache_charge(page, current->mm,
gfp_mask & GFP_RECLAIM_MASK);
...
在 Linux 的主线代码历史中并没有在该位置添加过这行代码。我们倾向于认为是 RedHat 的维护者在移植以下 patch 出错了,mapping_gfp_constraint() 应该针对部分操作作为 add_to_page_cache_lru() 的参数传递,而不是在随后的 __add_to_page_cache_locked() 无条件执行。
c20cd45eb017 mm: allow GFP_{FS,IO} for page_cache_read page cache allocation
c62d25556be6 mm, fs: introduce mapping_gfp_constraint()
6afdb859b710 mm: do not ignore mapping_gfp_mask in page cache allocation paths
diff --git a/mm/filemap.c b/mm/filemap.c
index 6ef3674c0763..1bb007624b53 100644
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -1722,7 +1722,7 @@ static ssize_t do_generic_file_read(struct file *filp, loff_t *ppos,
goto out;
}
error = add_to_page_cache_lru(page, mapping, index,
- GFP_KERNEL & mapping_gfp_mask(mapping));
+ mapping_gfp_constraint(mapping, GFP_KERNEL));
if (error) {
page_cache_release(page);
if (error == -EEXIST) {
@@ -1824,7 +1824,7 @@ static int page_cache_read(struct file *file, pgoff_t offset)
return -ENOMEM;
ret = add_to_page_cache_lru(page, mapping, offset,
- GFP_KERNEL & mapping_gfp_mask(mapping));
+ mapping_gfp_constraint(mapping, GFP_KERNEL));
if (ret == 0)
ret = mapping->a_ops->readpage(file, page);
else if (ret == -EEXIST)
一个比较保险的修复方法是,在 __add_to_page_cache_locked() 中判断上层是否传入 __GFP_NOFAIL,在 mapping_gfp_constraint() 之后把 __GFP_NOFAIL 加回来。相比直接删掉 mapping_gfp_constraint(),这种改法不需要修改所有 add_to_page_cache_lru() 的 caller,尽量保持原有的逻辑。
保证 grow_dev_page() 始终使用 __GFP_NOFAIL
在主线代码中,我们发现下面三个 patch 加强了 grow_dev_page(),保证在所有场景中 grow_dev_page() 都使用 __GFP_NOFAIL。
bc48f001de12 buffer: eliminate the need to call free_more_memory() in getblk_slow()
94dc24c0c59a buffer: grow_dev_page() should use GFP_NOFAIL for all cases
640ab98fb362 buffer: have alloc_page_buffers() use __GFP_NOFAIL
commit 94dc24c0c59a224a093f110060d01c2c620f275a
Author: Jens Axboe
Date: Wed Sep 27 05:45:36 2017 -0600
buffer: grow_dev_page() should use __GFP_NOFAIL for all cases
We currently use it for find_or_create_page(), which means that it
cannot fail. Ensure we also pass in 'retry == true' to
alloc_page_buffers(), which also ensure that it cannot fail.
After this, there are no failure cases in grow_dev_page() that
occur because of a failed memory allocation.
最终修复方案
带上上述两方面修复,我们的复现脚本再也没有复现该问题。目前我们已经把该问题和可能的修复方式汇报给 Redhat(https://bugzilla.redhat.com/show_bug.cgi?id=1911392),希望后续能够得到官方确认的最终修复方式。
总结
OOM Killer 是 Linux 提供的一项基本功能,然而这个场景相对比较罕见,难以保证各个模块在内存分配时能够很好地处理。对于服务提供方,一方面,我们需要尽可能保证我们的服务不会出现内存泄漏或者 OOM,这非常困难却是值得投入的。另一方面,Linux Kernel 的 OOM 处理也饱受大家诟病,有许多开源项目帮助大家在用户态做好 OOM 监控,例如 facebookincubator/oomd(https://github.com/facebookincubator/oomd) 和 rfjakob/earlyoom(https://github.com/rfjakob/earlyoom),这样就可以规避掉 Kernel OOM Killer 潜在的问题。
对文件系统和内核感兴趣的同学也欢迎加入我们。
作者介绍
Jiewei,SmartX 研发工程师。SmartX 拥有国内最顶尖的分布式存储和超融合架构研发团队,是国内超融合领域的技术领导者。