
非零均值?激活函数也太硬核了!
1. 为什么要有激活函数
若网络中不用激活函数,那么每一层的输出都是输入的线性组合。无论神经网络有多少层,网络的输出都是输入的线性组合,这种网络就是原始的感知机()。若网络没有激活函数,则每层就相当于矩阵相乘,深层神经网络,无非是多矩阵相乘。
激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。网络使用非线性激活函数后,可以增加神经网络模型的非线性因素,网络可以更加强大,表示输入输出之间非线性的复杂的任意函数映射。
网络的输出层可能会使用线性激活函数,但隐含层一般都是使用非线性激活函数。
2. 非零均值的问题(non-zero-centered)
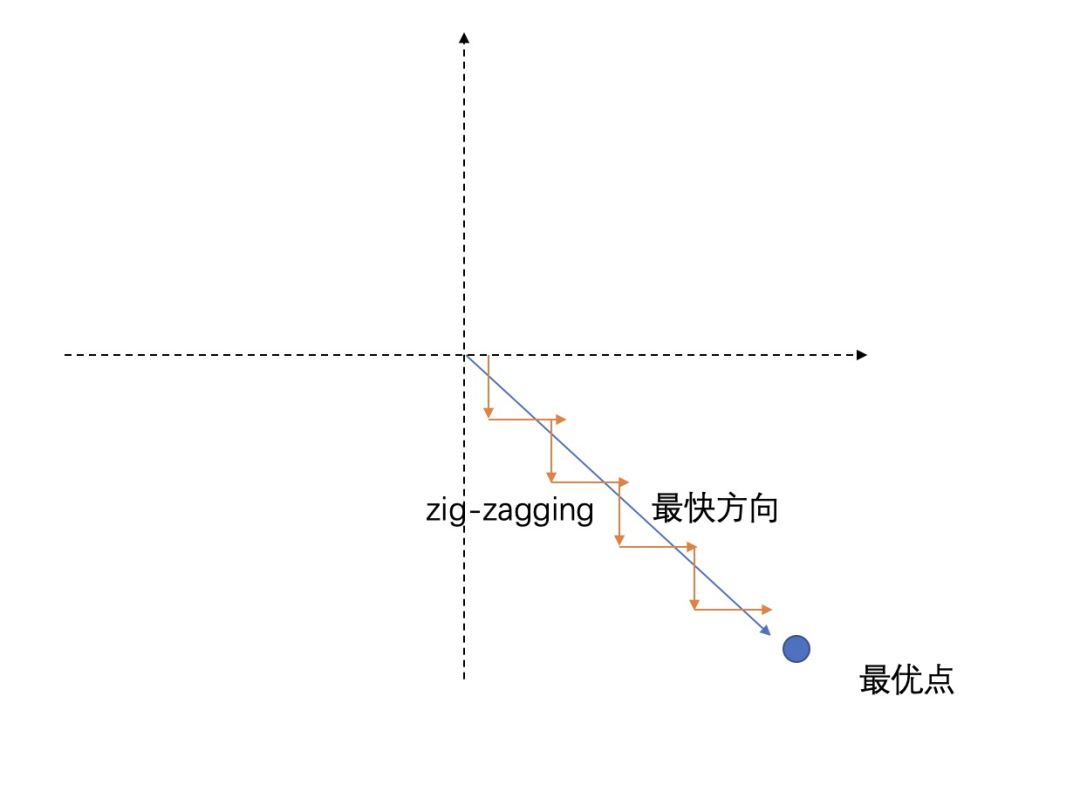
部分激活函数是非零均值的,如, 等激活函数,他会造成网络收敛很慢。我们可以简单看下表示式:,其中为函数的输出。那么,在计算损失函数后,需要进行反向传播更新该权重。这时候,对进行求导,是直接与相关的,而因为是大于的值,所以这时候的梯度方向就会完全取决于。这时候若恒正或者恒为负,那么就会出现 的问题,使得网络收敛变慢。
其中 的图像就如下面图像,相比于直接“奔向”最优点, 会更加“折腾”。
下面开始我们介绍下常用的激活函数,其中对于部分激活函数,画图都是采用Pytorch中Functional的默认参数来进行绘制的。
1. Sigmoid激活函数
sigmoid函数公式如下:
函数也叫函数,用于用于隐层神经元输出,取值范围为,它可以将一个实数映射到 的区间,可以用来做二分类或者生成 。在特征相差比较复杂或是相差不是特别大时效果比较好。
激活函数的缺点有:
激活函数计算量大,反向传播求误差梯度时,求导涉及除法; 反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练; 是非零均值的函数,收敛缓慢。 函数运算量大。如我们用(每秒浮点操作次数)来衡量模型的计算量指标。则运算量是1 。那么Sigmoid包括了减、取幂、加、除共4 .其次,指数运算,复杂度就是更高。
激活函数出现梯度消失的原因如下:
反向传播算法中,要对激活函数求导, 的导数表达式为:
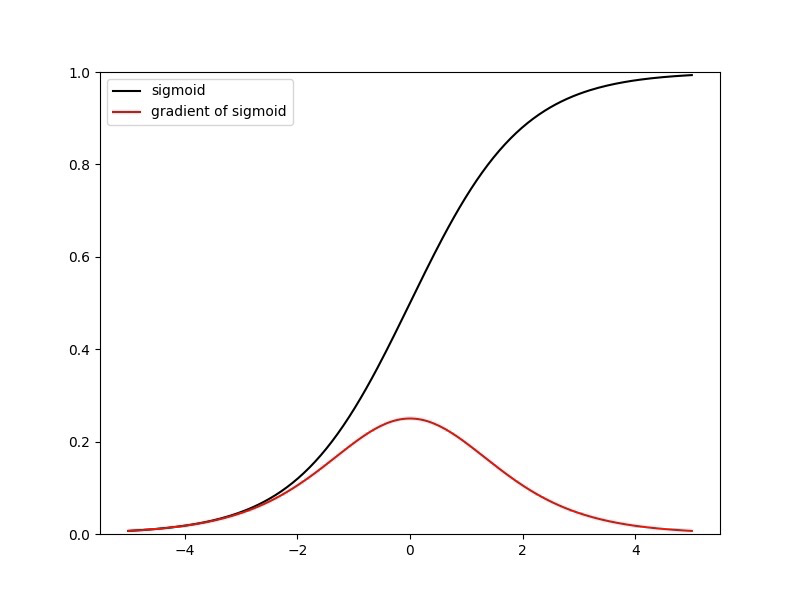
激活函数原函数及导数图形如下:由图可知,导数从0 开始很快就又趋近于0 了,易造成“梯度消失”现象。
2. TanH激活函数
激活函数的公式如下,也称为双切正切函数,取值范围为[-1,1]。
而函数的反传公式为:
函数的缺点同函数的缺点类似。当 z 很大或很小时,𝑔′(𝑧) 接近于 0 ,会导致梯度很小,权重更新非常缓慢,即梯度消失问题。从下面的图像也能看出来,靠近图像两端越平缓,梯度越小。
激活函数函数图像如图所示。
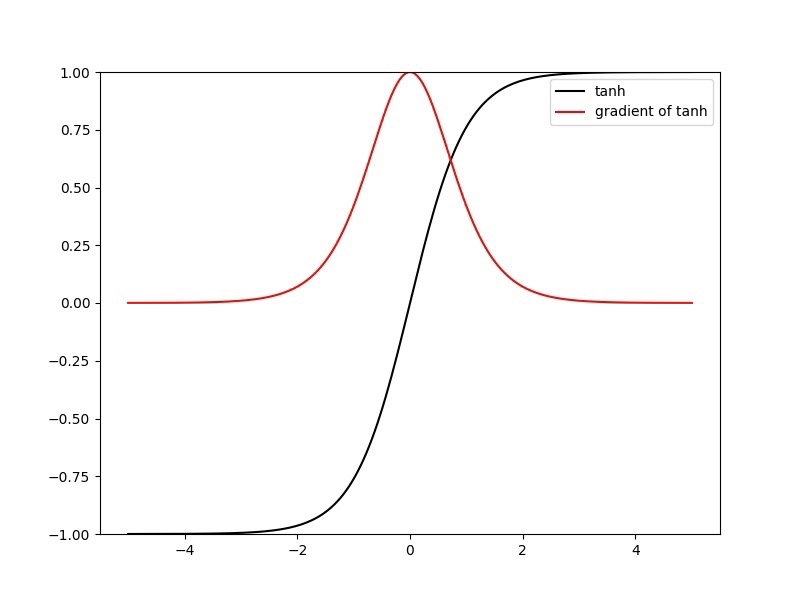
在特征相差明显时的效果会相对更好,在循环过程中会不断扩大特征效果。与 的区别是, 是 均值的,因此实际应用中 会比 更好,不过需要具体尝试。
3. ReLU激活函数
(Rectified Liner Unit)激活函数主要用于隐层神经元输出,公式为,函数图像与其求导的导数图像如图所示:
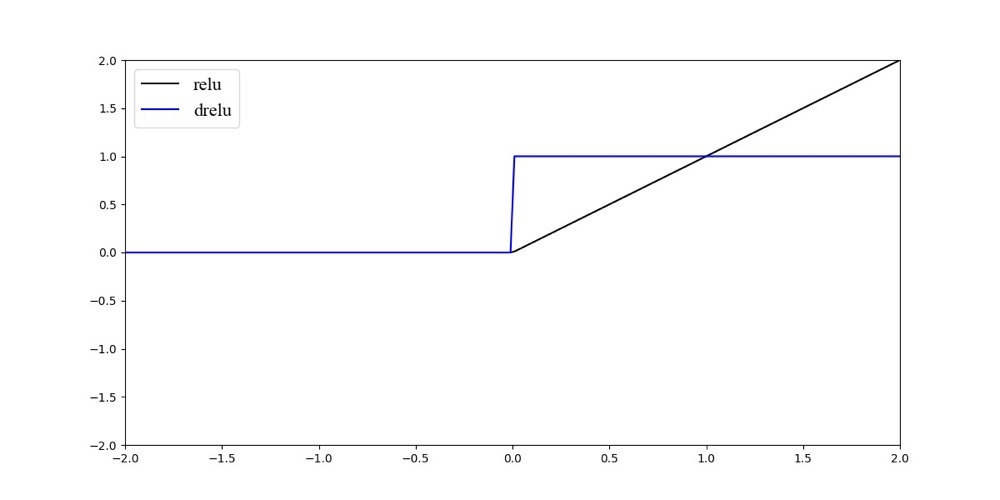
激活函数的特点是:输入信号小于时,输出都是0,输入信号大于0时,输出等于输入。
的优点是使用 得到的 的收敛速度会比使用的 快很多。
的缺点是神经网络训练的时候很“脆弱”,很容易就会出现神经元死亡。
例如,一个非常大的梯度流过一个 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了,那么这个神经元的梯度就永远都会是。(Dead ReLU Problem)。
非零均值,所以一般后会加。
4. Softmax 激活函数
多用于多分类神经网络输出,公式为:
主要用于分类最后归一化到 ,。当然也与一样,可以用在attention之中,学习到权重的矩阵。
5. Softplus激活函数
公式如下:
将与放在一起对比的话,则如图像所示:
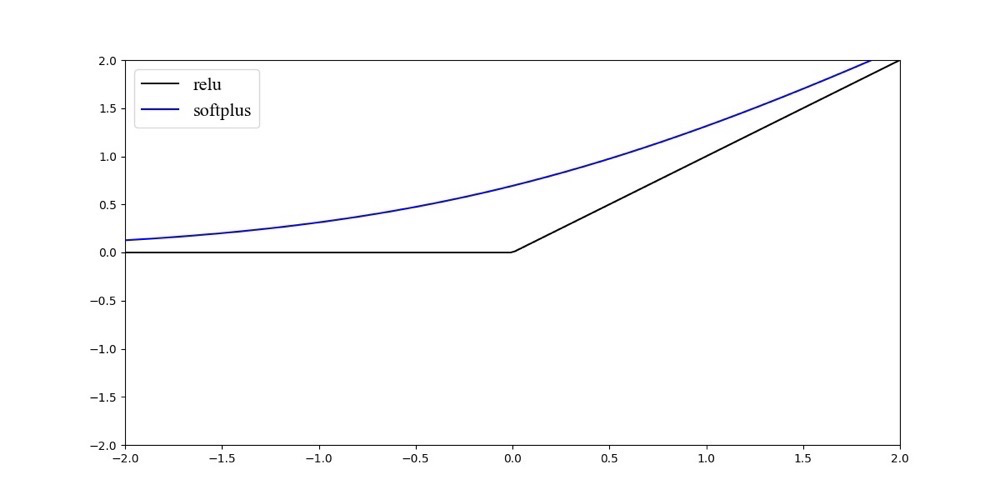
可以看到,可以看作是的平滑。其中,加了是为了保证非负性。可以看作是强制非负校正函数平滑版本。
5. Mish激活函数
函数的公式如下:
在中 激活函数代码如下:
x = x * (torch.tanh(F.softplus(x)))
函数图像如图所示:
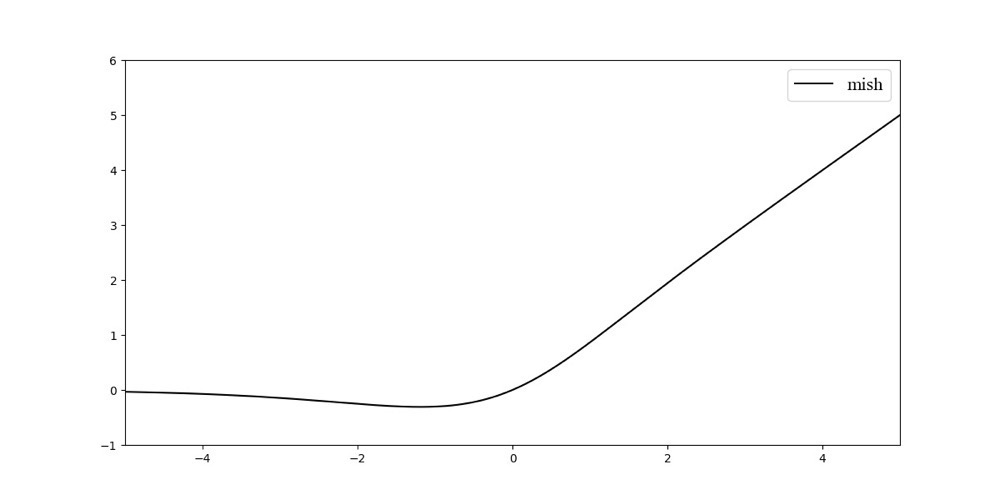
函数,以上无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许允许更好的梯度流,而不是像中那样的硬零边界。
最后,可能也是最重要的,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
不过我 之前亲自训过这个激活函数,版本的很占显存。
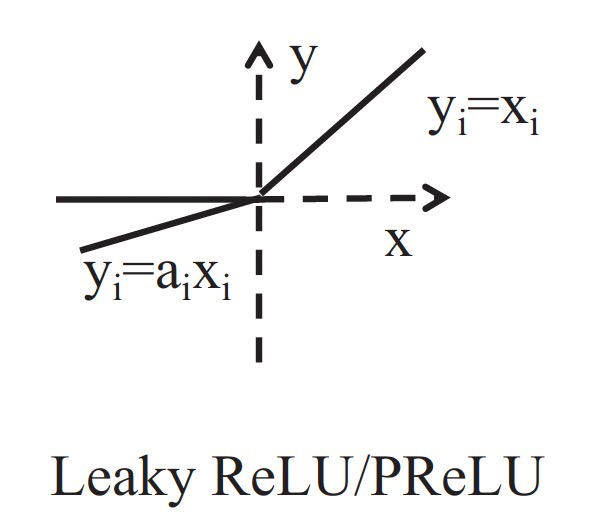
6. Leaky ReLU与PReLU
的公式如下:
是一个区间内的固定参数。与 相比 , 给所有负值赋予一个非零斜率。这样保留了一些负轴的值,使得负轴的信息不会全部丢失。
而 可以看作是 的一个变体。在中,负值部分的斜率是根据网络学习来定的,而非预先定义的。作者称,在分类(2015,Russakovsky等)上,是超越人类分类水平的关键所在。
如 与主要的特点是:(1)计算简单,有效 (2)比与收敛更快 (3) 解决了 的问题。
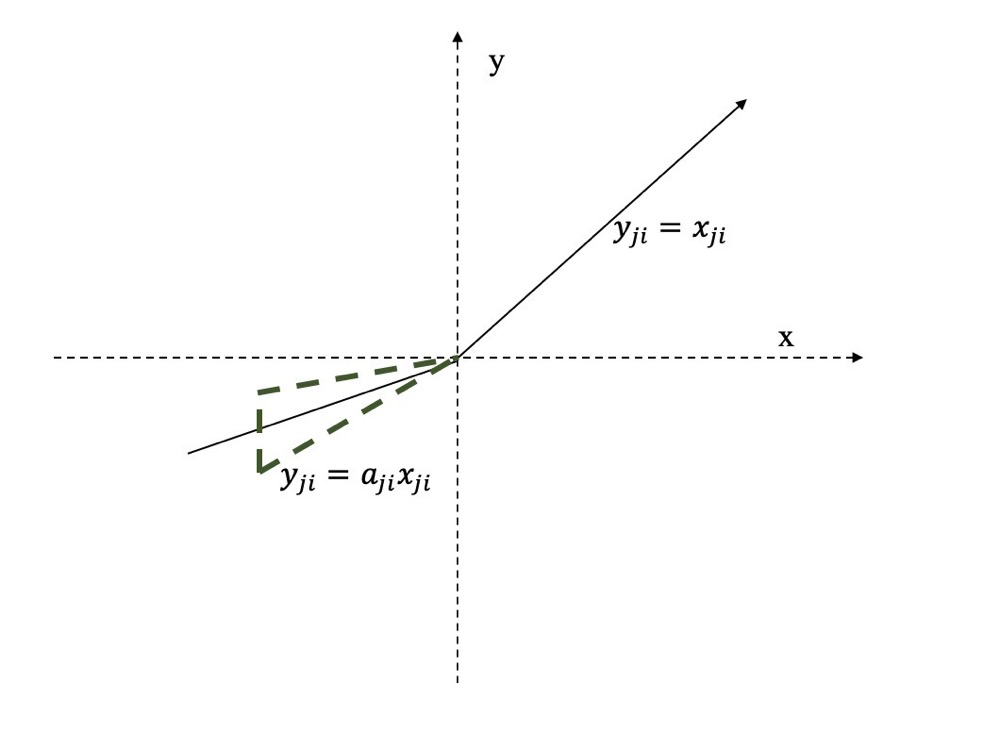
7. RReLU激活函数
(Randomized leaky rectified linear unit)也是 的一个变体。在中,是一个在一个给定的范围内随机抽取的值,这个值在测试环节就会固定下来
的亮点在于,在训练环节中,是从一个均匀的分布中随机抽取的数值。形式上来说,我们能得到以下结果:
where
该函数的图像如下图所示:
8. ELU激活函数
(Exponential Linear Unit)同样是针对的负数部分进行的改进,激活函数对小于零的情况采用类似指数计算的方式进行输出:
或者表达为:
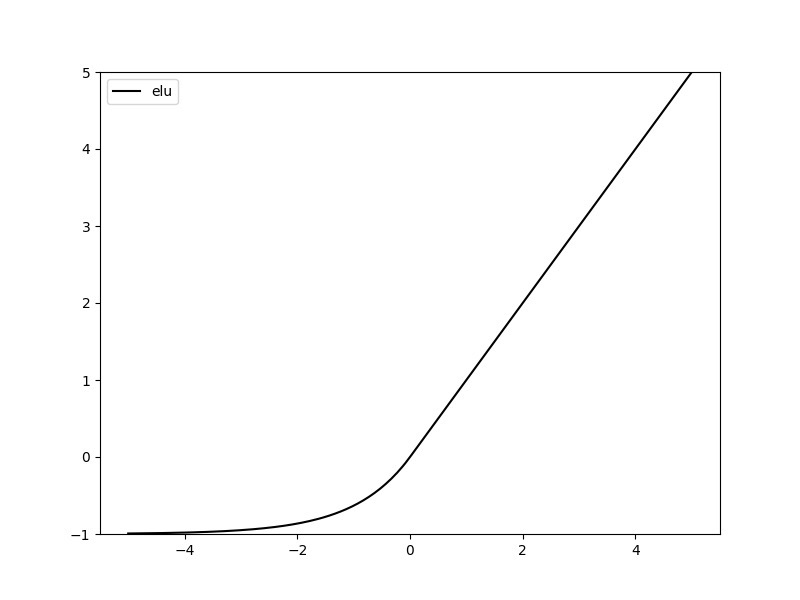
对于有这些特点:
由于其正值特性,可以像, , 一样缓解梯度消失的问题。 相比,存在负值,可以将激活单元的输出均值往推近,达到接近的效果同时减少了计算量。
9. Swish激活函数
激活函数的公式如下:
其函数图像如下:
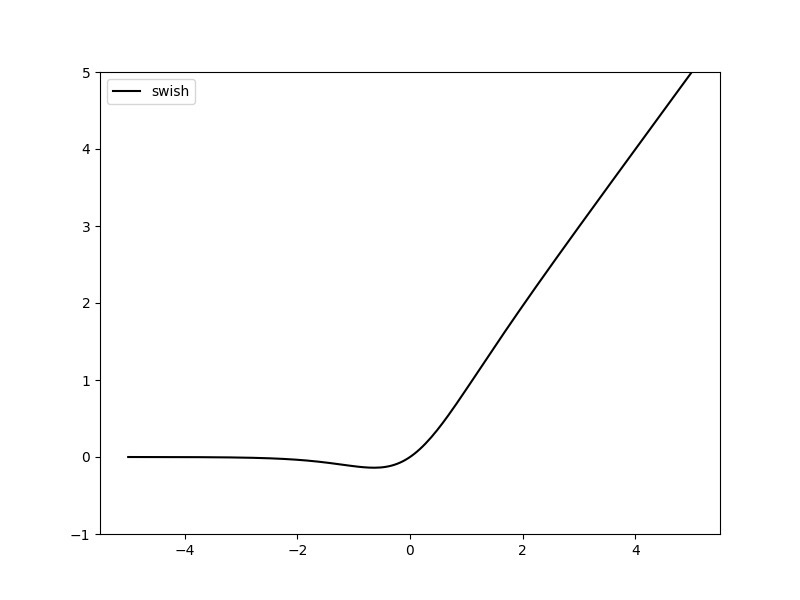
其中,是常数或可训练的参数。函数具备无上界有下界、平滑、非单调的特性。通过实验证明,对于深层模型, 的效果是优于的。
当时,激活函数成为线性函数。
当 为0或1. Swish变为ReLU: 。以函数可以看做是介于线性函数与函数之间的平滑函数.
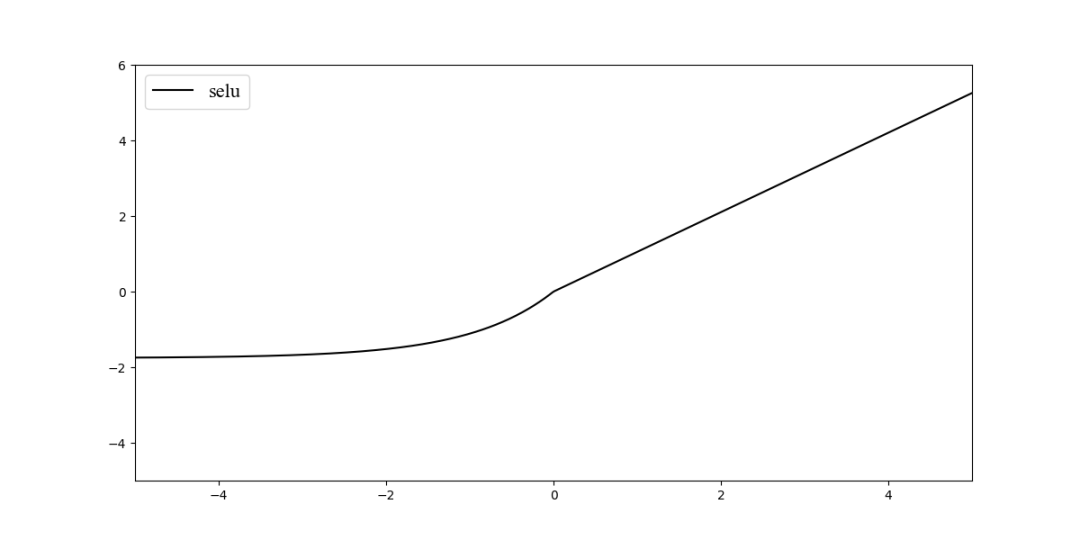
10. SELU激活函数
是给乘上系数 , 即。
文章中主要证明是当取得时,在网络权重服从标准正态分布的条件下,各层输出的分布会向标准正态分布靠拢,这种"自我标准化"的特性可以避免梯度消失于梯度爆炸,证明过程各位感兴趣的可以去看看90多页的原文。
函数图像如图所示:
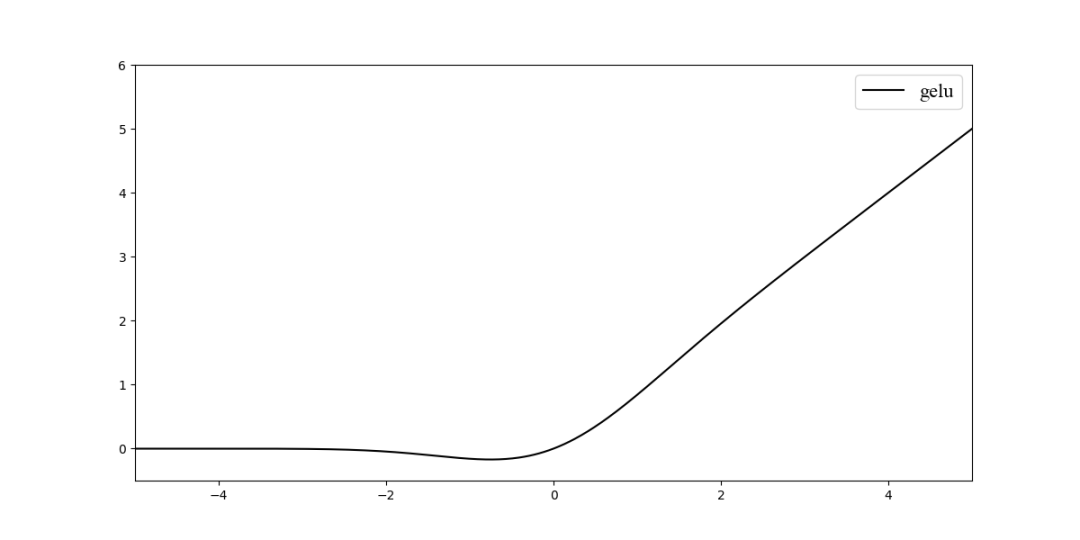
11. GELU激活函数
受启发于、等机制的影响,都意在将不重要的信息设置为0。对于输入的值,我们可以理解成是将输入的值乘以了一个0或者1。即对于每一个输入,其服从于标准正态分布,它也会乘以一个伯努利分布,其中。
(Gaussian error linear units)的表达式为。
而上式函数是无法直接计算的,因此可以使用另外的方式来进行逼近,论文得到的表达式为:。或者为。
, 中使用的激活函数,作者经过实验证明比等要好。原点可导,不会有 问题。
其函数图像如图所示:
引用
https://zhuanlan.zhihu.com/p/48776056 https://blog.csdn.net/u011984148/article/details/101444274 https://blog.csdn.net/weixin_39945445/article/details/111010529 https://blog.csdn.net/dulingtingzi/article/details/80319997 https://blog.csdn.net/qq_29831163/article/details/89887655
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!