
中国各城市首轮感染高峰期再预测!(更新版)
每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
原作者:chenqin@知乎,经济学研究者
近日,我对中国台湾地区、中国香港特别行政区和日本的感染情况与 “发烧” 搜索指数进行了分析,发现一个可能可以帮助预测感染高峰期的方法。

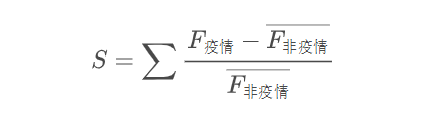

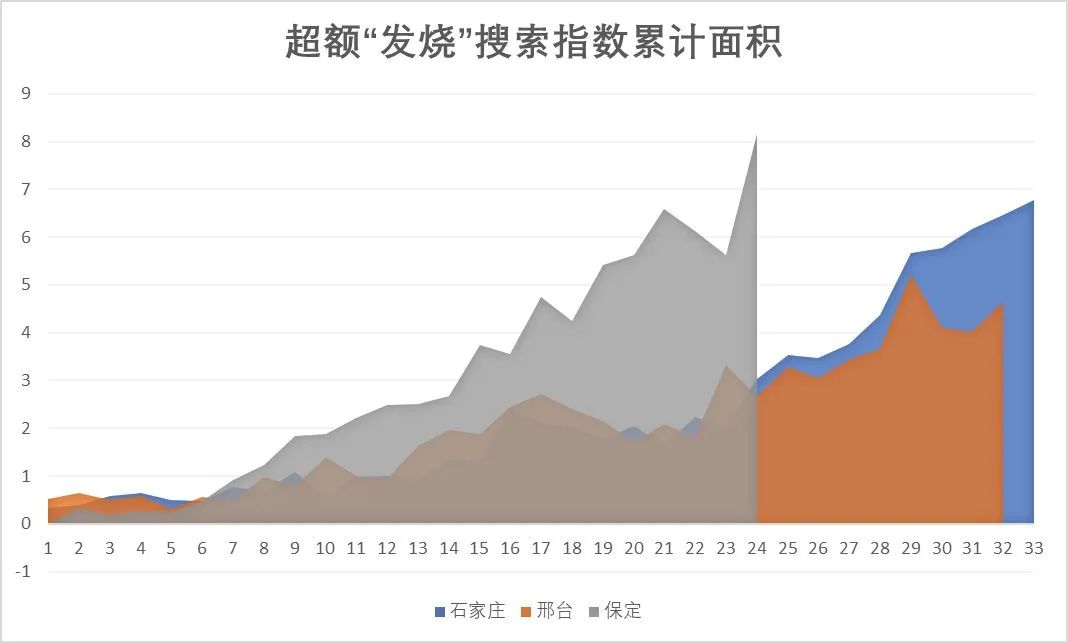

第三是加入了“结束进度条”这一变量,代表已经度过疫情顶峰的城市在第一波疫情结束前可能还要走的路程。
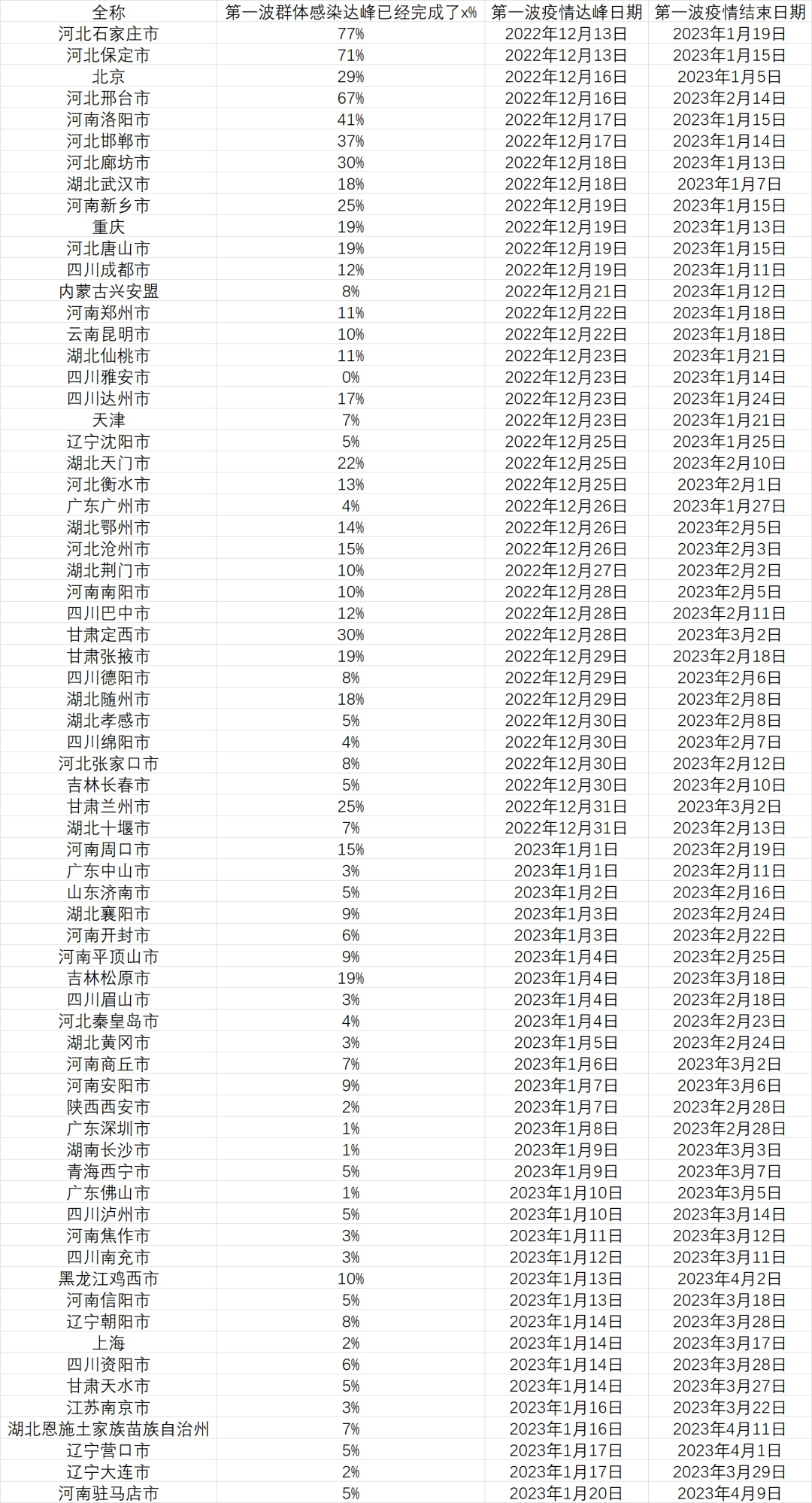
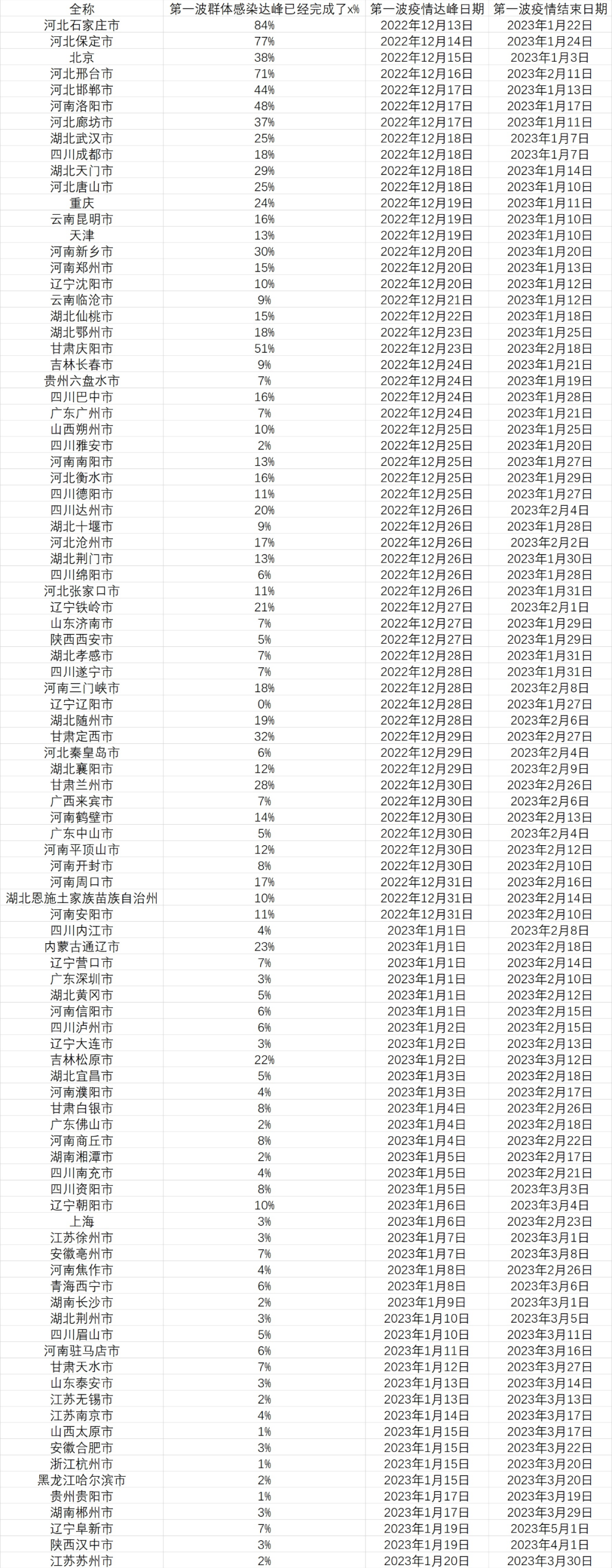
“达峰进度条”说明的是在疫情达到日增顶峰前已经感染了多少人,这是城市疫情逐渐加剧,院感增加,医疗资源逐渐挤兑的一段日子,数字达到 100 时日增感染者就达到了顶峰。
而“结束进度条”说明的是在疫情过峰后,在这一波疫情结束前已经感染了多少人,这段时间的疫情虽然整体缓解,但感染还是会继续增加,并且大部分死亡会出现在这个阶段。在数字达到 100 时,城市的这一波疫情就基本结束了。
疫情达峰时间的推算,原本只是搜索指数的一次尝试,初衷是觉得有趣,但无心插柳,竟然能帮助许多人缓解焦虑。
焦虑来自哪里?来自未知。既然和疫情共存了,那么不怕他不来,肯定得来,就怕它在计划外乱来。
那么有一个数据,虽然简陋,但也比没有数据好,至少大致上是和真实趋势吻合的。
既然如此,在卫健委有能力提供真实数据之前,我还是会希望继续更新下去,让这份粗糙的数据陪伴大家渡过第一次冲击。



数据不足,方法简陋,仅供参考。
评论