
中国各城市首轮感染高峰期预测!(最新更新版)
作者:chenqin@知乎,经济学研究者
这两天,上海一位数据工程师(花名:chenqin),结合百度、头条、谷歌数据中台湾地区、香港特别行政区和日本的感染情况与“发烧”搜索指数,通过算法预测计算出一组各大城市感染高峰期、与疫情结束日期。
就目前疫情比较严重的城市看,建议还没有到达感染高峰城市的网友,早点做好应急准备,因为我们面对的不仅是阳了的问题。
1. 将 Google 搜索指数分为疫情期间和非疫情期间,非疫情期间的发烧指数平均数为
,将疫情期间的搜索指数做以下处理后加总,计算一个数值
其中 S 的含义是这样的:如果发烧的搜索是发烧人口的一个相对稳定的比例,且在非疫情期间发烧人口是总人口的相对稳定的比例,那么 S 就正比于疫情感染的人口占总人口的比例,我们把它叫做 “超额发烧搜索指数累计面积”
2. 下图列出了台湾地区、香港特别行政区以及日本的 “超额发烧搜索指数累计面积”,即下图橙色面积、蓝色面积和灰色面积。
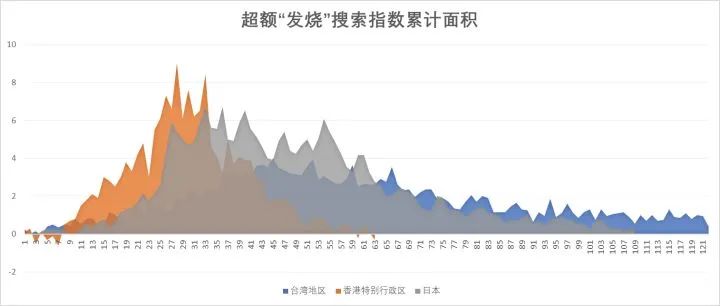
我们发现在这三个地区,当疫情达到顶峰时,这个 “超额发烧搜索指数累计面积” 的数值全部刚好达到 80。这两个地区第一波疫情结束时,香港特别行政区的面积达到了 160,台湾地区的面积达到了 200,日本的最终面积是 250。
3. 如果用百度搜索指数做类似的研究会有什么效果呢?我使用了本轮疫情进入群体感染最快、最早的石家庄、邢台和保定做了计算:
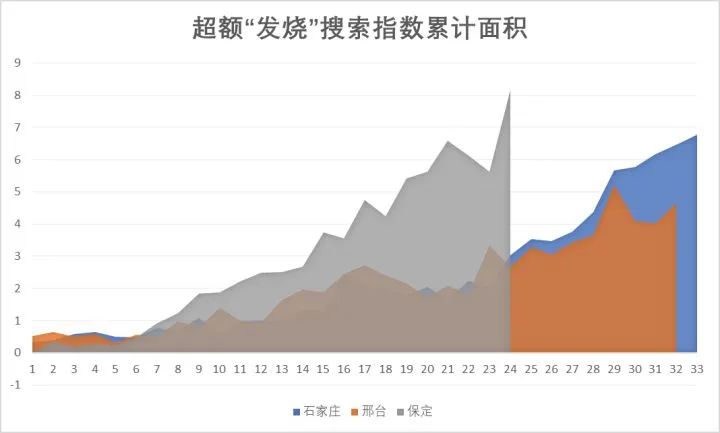
可以算出,从疫情开始后计算,石家庄的 “超额发烧搜索指数累计面积” 已经达到了 76,邢台已经达到了 67,保定也达到了 71。由此来看,百度搜索指数和 Google 指数分别算出的 “超额发烧搜索指数累计面积”,至少是在一个差不多的数量级上。
4. 考虑到保定、石家庄、邢台等地的发烧指数仍然在上升,以及百度搜索指数和 Google 指数的差异,我们比较保守地将 100 作为疫情达峰时的 “超额发烧搜索指数累计面积”,将 250 作为第一轮疫情结束时的 “超额发烧搜索指数累计面积”。那么我们通过每个城市的搜索指数累计增长,累计速度,就可以算出现在每一个有疫情的城市疫情达峰的时间,以及疫情结束的时间。
这是计算的结果,列出了所有能在明年春节前达峰的城市以及这些城市在达峰前已经感染的人口比例(截止至 12 月 20 日)。
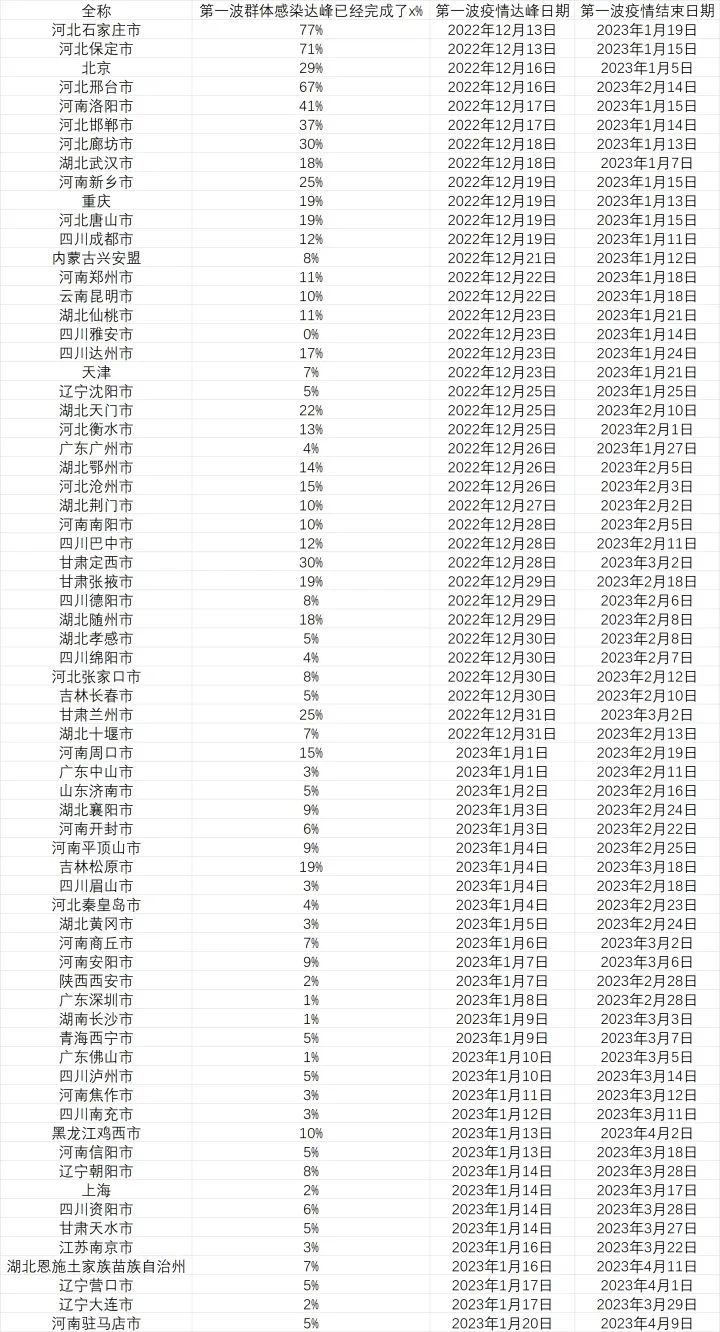
2022 年 12 月 12 日更新:
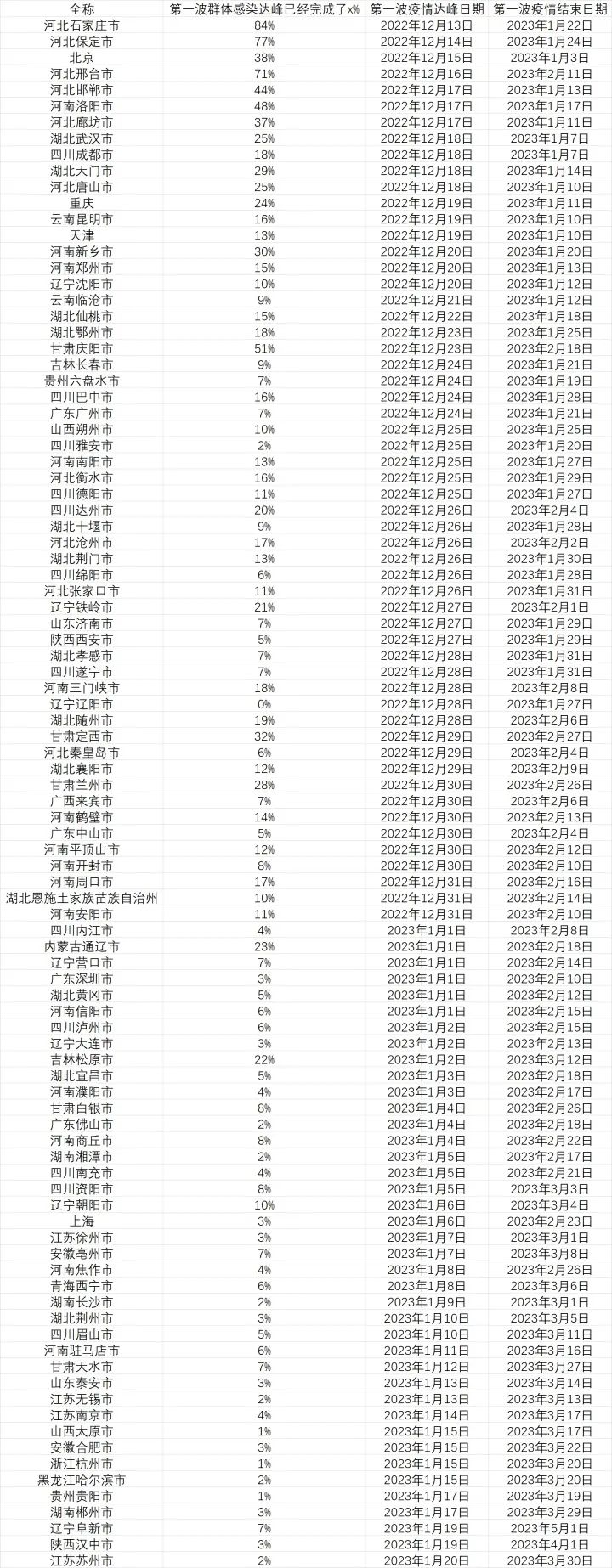
疫情分城市达峰时间表主要有三个改动,为了使得算法尽量准确:
第一是我将算法中过峰的“超额发烧搜索累计面积”修正回了80。
之前的几张表格中,保守起见,这个数值我使用了100,他会使一些城市过峰偏慢。但从这几天的数据看,石家庄、保定等地的累计超额倍数超过80的同时搜索指数也已经过峰,这说明中国内地城市居民,在非疫情-疫情的变化中,搜索行为的变化上和香港特别行政区、台湾地区的居民在同样时期的变化是非常类似的。因此一些城市的过峰时间会在表格中有所提前。
第二是加入了两个“进度条”,代表在城市在走向疫情顶峰和疫情结束的路程中感染了多少人。
“达峰进度条”说明的是在疫情达到日增顶峰前已经感染了多少人,这是城市疫情逐渐加剧,院感增加,医疗资源逐渐挤兑的一段日子,数字达到100时日增感染者就达到了顶峰。
而“结束进度条”说明的是在疫情过峰后,在这一波疫情结束前已经感染了多少人,这段时间的疫情虽然整体缓解,但感染还是会继续增加,并且大部分死亡会出现在这个阶段。在数字达到100时,城市的这一波疫情就基本结束了。
第三是加入了巨量算数指标修正了一些城市,加入了一些之前数据不足的城市,因此城市数量大幅度增加,一些城市的百度指数很低,但是抖音安装率很高,因此巨量算术的数据能够起到作用。
当然数据增加的更大原因是因为许多城市疫情正在逐步蔓延,因此进入了搜索指数的监测中。我常常收到私信和评论询问“我住在xx,但xx城市在哪里我在表格里面怎么看不到”,我想说,珍稀这样的时光吧,不出意外的话马上你就可以天天看到你住的城市了。
疫情达峰时间的推算,原本只是搜索指数的一次尝试,初衷是觉得有趣,但无心插柳,竟然能帮助许多人缓解焦虑。焦虑来自哪里?来自未知。既然和疫情共存了,那么不怕他不来,肯定得来,就怕它在计划外乱来。那么有一个数据,虽然简陋,但也比没有数据好,至少大致上是和真实趋势吻合的。
2022年12月13日:
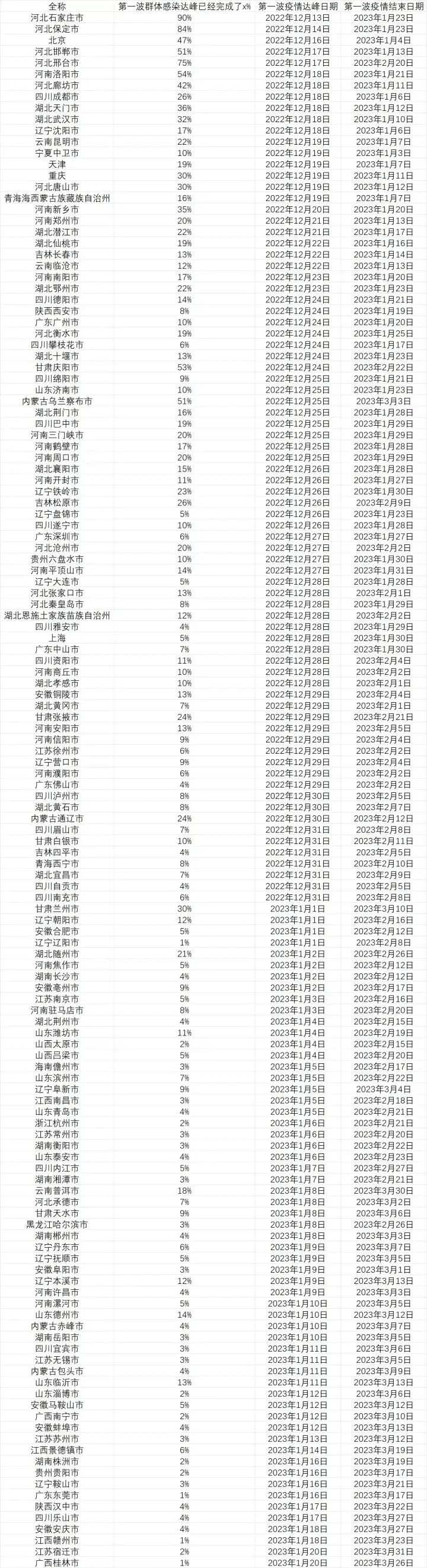
2022年12月14日:

2022年12月15日:

2022年12月16日:
这也是该模型最后一次大幅度修改,数据相对稳定。

2022年12月17日:

2022年12月18日:

12月19日更新:
许多有心人都能发现,今天的百度与巨量指数的“发烧”搜索出现了严重的数据污染。因此花了一些时间,用其他关键词做了一定修正。

12月20日:

注:因数据不足,图片大小限制,因此不得不去掉人口在50万以下的城市,以上仅供参考。
好书推荐

PyTorch是基于 Torch 库的开源机器学习库,它主要由 Meta(原 Facebook)的人工智能研究实验室开发,在自然语言处理和计算机视觉领域都具有广泛的应用。本书介绍了简单且经典的入门项目,方便快速上手,如 MNIST数字识别,读者在完成项目的过程中可以了解数据集、模型和训练等基础概念。本书还介绍了一些实用且经典的模型,如 R-CNN 模型,通过这个模型的学习,读者可以对目标检测任务有一个基本的认识,对于基本的网络结构原理有一定的了解。另外,本书对于当前比较热门的生成对抗网络和强化学习也有一定的介绍,方便读者拓宽视野,掌握前沿方向。
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|