
Flink重点难点:Flink Table&SQL必知必会(一)
在后台留言阴阳怪气的一些人,我跟你们说下。不管之前的小编对你态度怎么样。
在我这里就下面这样:
你要觉得能看,老实的收藏,自己回头研究去就行了,跳槽涨工资也别谢我,是你应得的。
你要觉得不能看,你跟我说声,我直接给你拉到黑名单去。
不然万一我心情好,逮住你猛喷两句,你晚上又睡不着觉了。你家里人也跟着你遭殃。
还有,公众号不是一个人在维护。
凡是进了黑名单的,你也别加我微信,不管谁拉你到黑名单里的,绝对不可能放出来。
什么是Table API和Flink SQL
Flink本身是批流统一的处理框架,所以Table API和SQL,就是批流统一的上层处理API。目前功能尚未完善,处于活跃的开发阶段。
Table API是一套内嵌在Java和Scala语言中的查询API,它允许我们以非常直观的方式,组合来自一些关系运算符的查询(比如select、filter和join)。而对于Flink SQL,就是直接可以在代码中写SQL,来实现一些查询(Query)操作。Flink的SQL支持,基于实现了SQL标准的Apache Calcite(Apache开源SQL解析工具)。
无论输入是批输入还是流式输入,在这两套API中,指定的查询都具有相同的语义,得到相同的结果。
需要引入的依赖
取决于你使用的编程语言,比如这里,我们选择 Scala API 来构建你的 Table API 和 SQL 程序:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.11.0</version>
<scope>provided</scope>
</dependency>
除此之外,如果你想在 IDE 本地运行你的程序,你需要添加下面的模块,具体用哪个取决于你使用哪个 Planner,我们这里选择使用 blink planner:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.11.0</version>
<scope>provided</scope>
</dependency>
如果你想实现自定义格式来解析 Kafka 数据,或者自定义函数,使用下面的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.11.0</version>
<scope>provided</scope>
</dependency>
flink-table-planner-blink:planner计划器,是table API最主要的部分,提供了运行时环境和生成程序执行计划的planner;
flink-table-api-scala-bridge:bridge桥接器,主要负责table API和 DataStream/DataSet API的连接支持,按照语言分java和scala。
这里的两个依赖,是IDE环境下运行需要添加的;如果是生产环境,lib目录下默认已经有了planner,就只需要有bridge就可以了。
需要注意的是:flink table本身有两个 planner 计划器,在flink 1.11之后,已经默认使用 blink planner,如果想了解 old planner,可以查阅官方文档。
两种planner(old & blink)的区别
批流统一:Blink将批处理作业,视为流式处理的特殊情况。所以,blink不支持表和DataSet之间的转换,批处理作业将不转换为DataSet应用程序,而是跟流处理一样,转换为DataStream程序来处理。
因为批流统一,Blink planner也不支持BatchTableSource,而使用有界的StreamTableSource代替。
Blink planner只支持全新的目录,不支持已弃用的ExternalCatalog。
旧planner和Blink planner的FilterableTableSource实现不兼容。旧的planner会把PlannerExpressions下推到filterableTableSource中,而blink planner则会把Expressions下推。
基于字符串的键值配置选项仅适用于Blink planner。
PlannerConfig在两个planner中的实现不同。
Blink planner会将多个sink优化在一个DAG中(仅在TableEnvironment上受支持,而在StreamTableEnvironment上不受支持)。而旧planner的优化总是将每一个sink放在一个新的DAG中,其中所有DAG彼此独立。
旧的planner不支持目录统计,而Blink planner支持。
1 基本程序结构
Table API 和 SQL 的程序结构,与流式处理的程序结构类似;也可以近似地认为有这么几步:首先创建执行环境,然后定义source、transform和sink。
具体操作流程如下:
val tableEnv = ... // 创建表环境
// 创建表
tableEnv.connect(...).createTemporaryTable("table1")
// 注册输出表
tableEnv.connect(...).createTemporaryTable("outputTable")
// 使用 Table API query 创建表
val tapiResult = tableEnv.from("table1").select(...)
// 使用 SQL query 创建表
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM table1 ...")
// 输出一张结果表到 TableSink,SQL查询的结果表也一样
TableResult tableResult = tapiResult.executeInsert("outputTable");
tableResult...
// 执行
tableEnv.execute("scala_job")
2 创建表环境
表环境(TableEnvironment)是flink中集成Table API & SQL的核心概念。它负责:
在内部的 catalog 中注册 Table
注册外部的 catalog
加载可插拔模块
执行 SQL 查询
注册自定义函数 (scalar、table 或 aggregation)
将 DataStream 或 DataSet 转换成 Table
持有对 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用
在创建TableEnv的时候,可以多传入一个EnvironmentSettings或者TableConfig参数,可以用来配置TableEnvironment的一些特性。
Table 总是与特定的 TableEnvironment 绑定。不能在同一条查询中使用不同 TableEnvironment 中的表,例如,对它们进行 join 或 union 操作。
TableEnvironment 可以通过静态方法 BatchTableEnvironment.create() 或者 StreamTableEnvironment.create() 在 StreamExecutionEnvironment 或者 ExecutionEnvironment 中创建,TableConfig 是可选项。TableConfig可用于配置TableEnvironment或定制的查询优化和转换过程(参见 查询优化)。
请确保选择与你的编程语言匹配的特定的计划器BatchTableEnvironment/StreamTableEnvironment。
如果两种计划器的 jar 包都在 classpath 中(默认行为),你应该明确地设置要在当前程序中使用的计划器。
基于blink版本的流处理环境(Blink-Streaming-Query):
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
val bsEnv = StreamExecutionEnvironment.getExecutionEnvironment
val bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build()
val bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings)
这里只提供了 blink planner 的流处理设置。有关 old planner 的批处理和流处理的设置,以及 blink planner 的批处理的设置,请查阅官方文档。
3 在Catalog中注册表
TableEnvironment 维护着一个由标识符(identifier)创建的表 catalog 的映射。标识符由三个部分组成:catalog 名称、数据库名称以及对象名称。如果 catalog 或者数据库没有指明,就会使用当前默认值。
Table 可以是虚拟的(视图 VIEWS)也可以是常规的(表 TABLES)。视图 VIEWS可以从已经存在的Table中创建,一般是 Table API 或者 SQL 的查询结果。表TABLES描述的是外部数据,例如文件、数据库表或者消息队列。
临时表(Temporary Table)和永久表(Permanent Table) 表可以是临时的,并与单个 Flink 会话(session)的生命周期相关,也可以是永久的,并且在多个 Flink 会话和群集(cluster)中可见。
永久表需要 catalog(例如 Hive Metastore)以维护表的元数据。一旦永久表被创建,它将对任何连接到 catalog 的 Flink 会话可见且持续存在,直至被明确删除。
另一方面,临时表通常保存于内存中并且仅在创建它们的 Flink 会话持续期间存在。这些表对于其它会话是不可见的。它们不与任何 catalog 或者数据库绑定但可以在一个命名空间(namespace)中创建。即使它们对应的数据库被删除,临时表也不会被删除。
创建表
虚拟表
在 SQL 的术语中,Table API 的对象对应于视图(虚拟表)。它封装了一个逻辑查询计划。它可以通过以下方法在 catalog 中创建:
// get a TableEnvironment
val tableEnv = ... // see "Create a TableEnvironment" section
// table is the result of a simple projection query
val projTable: Table = tableEnv.from("X").select(...)
// register the Table projTable as table "projectedTable"
tableEnv.createTemporaryView("projectedTable", projTable)
扩展表标识符
表总是通过三元标识符注册,包括 catalog 名、数据库名和表名。
用户可以指定一个 catalog 和数据库作为 “当前catalog” 和”当前数据库”。有了这些,那么刚刚提到的三元标识符的前两个部分就可以被省略了。如果前两部分的标识符没有指定, 那么会使用当前的 catalog 和当前数据库。用户也可以通过 Table API 或 SQL 切换当前的 catalog 和当前的数据库。
标识符遵循 SQL 标准,因此使用时需要用反引号进行转义。
// get a TableEnvironment
val tEnv: TableEnvironment = ...;
tEnv.useCatalog("custom_catalog")
tEnv.useDatabase("custom_database")
val table: Table = ...;
// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("exampleView", table)
// register the view named 'exampleView' in the catalog named 'custom_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_database.exampleView", table)
// register the view named 'example.View' in the catalog named 'custom_catalog'
// in the database named 'custom_database'
tableEnv.createTemporaryView("`example.View`", table)
// register the view named 'exampleView' in the catalog named 'other_catalog'
// in the database named 'other_database'
tableEnv.createTemporaryView("other_catalog.other_database.exampleView", table)
4 表的查询
利用外部系统的连接器connector,我们可以读写数据,并在环境的Catalog中注册表。接下来就可以对表做查询转换了。
Flink给我们提供了两种查询方式:Table API和 SQL。
Table API的调用
Table API是集成在Scala和Java语言内的查询API。与SQL不同,Table API的查询不会用字符串表示,而是在宿主语言中一步一步调用完成的。
Table API基于代表一张“表”的Table类,并提供一整套操作处理的方法API。这些方法会返回一个新的Table对象,这个对象就表示对输入表应用转换操作的结果。有些关系型转换操作,可以由多个方法调用组成,构成链式调用结构。例如table.select(…).filter(…),其中select(…)表示选择表中指定的字段,filter(…)表示筛选条件。
代码中的实现如下:
// 获取表环境
val tableEnv = ...
// 注册订单表
// 扫描注册的订单表
val orders = tableEnv.from("Orders")
// 计算来自法国的客户的总收入
val revenue = orders
.filter($"cCountry" === "FRANCE")
.groupBy($"cID", $"cName")
.select($"cID", $"cName", $"revenue".sum AS "revSum")
// 输出或者转换表
// 执行查询
注意:需要导入的隐式类型转换
org.apache.flink.table.api._
org.apache.flink.api.scala._
org.apache.flink.table.api.bridge.scala._
SQL查询
Flink的SQL集成,基于的是Apache Calcite,它实现了SQL标准。在Flink中,用常规字符串来定义SQL查询语句。SQL 查询的结果,是一个新的 Table。
代码实现如下:
// get a TableEnvironment
val tableEnv = ... // see "Create a TableEnvironment" section
// register Orders table
// compute revenue for all customers from France
val revenue = tableEnv.sqlQuery("""
|SELECT cID, cName, SUM(revenue) AS revSum
|FROM Orders
|WHERE cCountry = 'FRANCE'
|GROUP BY cID, cName
""".stripMargin)
// emit or convert Table
// execute query
如下的示例展示了如何指定一个更新查询,将查询的结果插入到已注册的表中。
// get a TableEnvironment
val tableEnv = ... // see "Create a TableEnvironment" section
// register "Orders" table
// register "RevenueFrance" output table
// compute revenue for all customers from France and emit to "RevenueFrance"
tableEnv.executeSql("""
|INSERT INTO RevenueFrance
|SELECT cID, cName, SUM(revenue) AS revSum
|FROM Orders
|WHERE cCountry = 'FRANCE'
|GROUP BY cID, cName
""".stripMargin)
5 将DataStream转换成表
Flink允许我们把Table和DataStream做转换:我们可以基于一个DataStream,先流式地读取数据源,然后map成样例类,再把它转成Table。Table的列字段(column fields),就是样例类里的字段,这样就不用再麻烦地定义schema了。
代码表达
代码中实现非常简单,直接用tableEnv.fromDataStream()就可以了。默认转换后的 Table schema 和 DataStream 中的字段定义一一对应,也可以单独指定出来。
这就允许我们更换字段的顺序、重命名,或者只选取某些字段出来,相当于做了一次map操作(或者Table API的 select操作)。
代码具体如下:
val inputStream: DataStream[String] = env.readTextFile("sensor.txt")
val dataStream: DataStream[SensorReading] = inputStream
.map(data => {
val dataArray = data.split(",")
SensorReading(dataArray(0), dataArray(1).toLong, dataArray(2).toDouble)
})
val sensorTable: Table = tableEnv.fromDataStream(dataStream)
val sensorTable2 = tableEnv.fromDataStream(dataStream, 'id, 'timestamp as 'ts)
数据类型与Table schema的对应
在上节的例子中,DataStream 中的数据类型,与表的 Schema 之间的对应关系,是按照样例类中的字段名来对应的(name-based mapping),所以还可以用as做重命名。
另外一种对应方式是,直接按照字段的位置来对应(position-based mapping),对应的过程中,就可以直接指定新的字段名了。
基于名称的对应:
val sensorTable = tableEnv
.fromDataStream(dataStream, $"timestamp" as "ts", $"id" as "myId", "temperature")
基于位置的对应:
val sensorTable = tableEnv
.fromDataStream(dataStream, $"myId", $"ts")
Flink的DataStream和 DataSet API支持多种类型。
组合类型,比如元组(内置Scala和Java元组)、POJO、Scala case类和Flink的Row类型等,允许具有多个字段的嵌套数据结构,这些字段可以在Table的表达式中访问。其他类型,则被视为原子类型。
元组类型和原子类型,一般用位置对应会好一些;如果非要用名称对应,也是可以的:
元组类型,默认的名称是 "_1 , "_2";而原子类型,默认名称是 ”f0”。
6 创建临时视图
创建临时视图的第一种方式,就是直接从DataStream转换而来。同样,可以直接对应字段转换;也可以在转换的时候,指定相应的字段。
代码如下:
tableEnv.createTemporaryView("sensorView", dataStream)
tableEnv.createTemporaryView("sensorView",
dataStream, $"id", $"temperature", $"timestamp" as "ts")
另外,当然还可以基于Table创建视图:
tableEnv.createTemporaryView("sensorView", sensorTable)
View和Table的Schema完全相同。事实上,在Table API中,可以认为View和Table是等价的。
7 输出表
更新模式(Update Mode)
在流处理过程中,表的处理并不像传统定义的那样简单。
对于流式查询(Streaming Queries),需要声明如何在(动态)表和外部连接器之间执行转换。与外部系统交换的消息类型,由更新模式(update mode)指定。
Flink Table API中的更新模式有以下三种:
追加模式(Append Mode)
在追加模式下,表(动态表)和外部连接器只交换插入(Insert)消息。
撤回模式(Retract Mode)
在撤回模式下,表和外部连接器交换的是:添加(Add)和撤回(Retract)消息。
插入(Insert)会被编码为添加消息;
删除(Delete)则编码为撤回消息;
更新(Update)则会编码为,已更新行(上一行)的撤回消息,和更新行(新行)的添加消息。
在此模式下,不能定义key,这一点跟upsert模式完全不同。
Upsert(更新插入)模式
在Upsert模式下,动态表和外部连接器交换Upsert和Delete消息。
这个模式需要一个唯一的key,通过这个key可以传递更新消息。为了正确应用消息,外部连接器需要知道这个唯一key的属性。
插入(Insert)和更新(Update)都被编码为Upsert消息;
删除(Delete)编码为Delete信息。
这种模式和Retract模式的主要区别在于,Update操作是用单个消息编码的,所以效率会更高。
8 将表转换成DataStream
表可以转换为DataStream或DataSet。这样,自定义流处理或批处理程序就可以继续在 Table API或SQL查询的结果上运行了。
将表转换为DataStream或DataSet时,需要指定生成的数据类型,即要将表的每一行转换成的数据类型。通常,最方便的转换类型就是Row。当然,因为结果的所有字段类型都是明确的,我们也经常会用元组类型来表示。
表作为流式查询的结果,是动态更新的。所以,将这种动态查询转换成的数据流,同样需要对表的更新操作进行编码,进而有不同的转换模式。
Table API中表到DataStream有两种模式:
追加模式(Append Mode)
用于表只会被插入(Insert)操作更改的场景。
撤回模式(Retract Mode)
用于任何场景。有些类似于更新模式中Retract模式,它只有Insert和Delete两类操作。
得到的数据会增加一个Boolean类型的标识位(返回的第一个字段),用它来表示到底是新增的数据(Insert),还是被删除的数据(老数据,Delete)。
代码实现如下:
val resultStream: DataStream[Row] = tableEnv
.toAppendStream[Row](resultTable)
val aggResultStream: DataStream[(Boolean, (String, Long))] = tableEnv
.toRetractStream[(String, Long)](aggResultTable)
resultStream.print("result")
aggResultStream.print("aggResult")
所以,没有经过groupby之类聚合操作,可以直接用toAppendStream来转换;而如果经过了聚合,有更新操作,一般就必须用toRetractDstream。
9 Query的解释和执行
Table API提供了一种机制来解释(Explain)计算表的逻辑和优化查询计划。这是通过TableEnvironment.explain(table)方法或TableEnvironment.explain()方法完成的。
explain方法会返回一个字符串,描述三个计划:
未优化的逻辑查询计划
优化后的逻辑查询计划
实际执行计划
我们可以在代码中查看执行计划:
val explaination: String = tableEnv.explain(resultTable)
println(explaination)
Query的解释和执行过程,老planner和blink planner大体是一致的,又有所不同。整体来讲,Query都会表示成一个逻辑查询计划,然后分两步解释:
优化查询计划
解释成 DataStream 或者 DataSet程序
而Blink版本是批流统一的,所以所有的Query,只会被解释成DataStream程序;另外在批处理环境TableEnvironment下,Blink版本要到tableEnv.execute()执行调用才开始解释。
Table API和SQL,本质上还是基于关系型表的操作方式;而关系型表、关系代数,以及SQL本身,一般是有界的,更适合批处理的场景。这就导致在进行流处理的过程中,理解会稍微复杂一些,需要引入一些特殊概念。
1 流处理和关系代数(表,及SQL)的区别
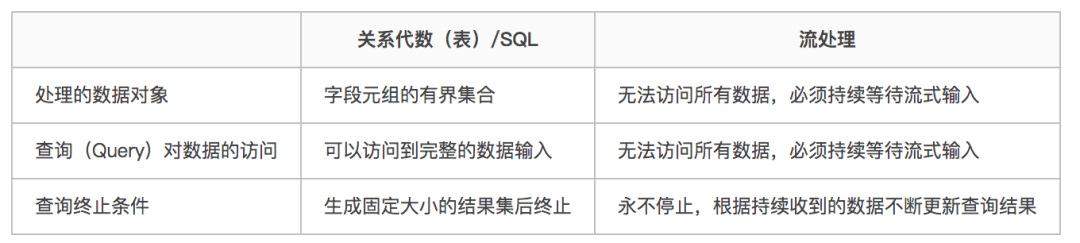
可以看到,其实关系代数(主要就是指关系型数据库中的表)和SQL,主要就是针对批处理的,这和流处理有天生的隔阂。
2 动态表
因为流处理面对的数据,是连续不断的,这和我们熟悉的关系型数据库中保存的“表”完全不同。所以,如果我们把流数据转换成Table,然后执行类似于table的select操作,结果就不是一成不变的,而是随着新数据的到来,会不停更新。
我们可以随着新数据的到来,不停地在之前的基础上更新结果。这样得到的表,在Flink Table API概念里,就叫做“动态表”(Dynamic Tables)。
动态表是Flink对流数据的Table API和SQL支持的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。动态表可以像静态的批处理表一样进行查询,查询一个动态表会产生持续查询(Continuous Query)。连续查询永远不会终止,并会生成另一个动态表。查询(Query)会不断更新其动态结果表,以反映其动态输入表上的更改。
3 流式持续查询的过程
下图显示了流、动态表和连续查询的关系:

流式持续查询的过程为:
流被转换为动态表
对动态表计算连续查询,生成新的动态表
生成的动态表被转换回流
3.1 将流转换成表(Table)
为了处理带有关系查询的流,必须先将其转换为表。
从概念上讲,流的每个数据记录,都被解释为对结果表的插入(Insert)修改。因为流式持续不断的,而且之前的输出结果无法改变。本质上,我们其实是从一个、只有插入操作的changelog(更新日志)流,来构建一个表。
为了更好地说明动态表和持续查询的概念,我们来举一个具体的例子。
比如,我们现在的输入数据,就是用户在网站上的访问行为,数据类型(Schema)如下:
{
user: VARCHAR, // 用户名
cTime: TIMESTAMP, // 访问某个URL的时间戳
url: VARCHAR // 用户访问的URL
}
下图显示了如何将访问URL事件流,或者叫点击事件流(左侧)转换为表(右侧)。
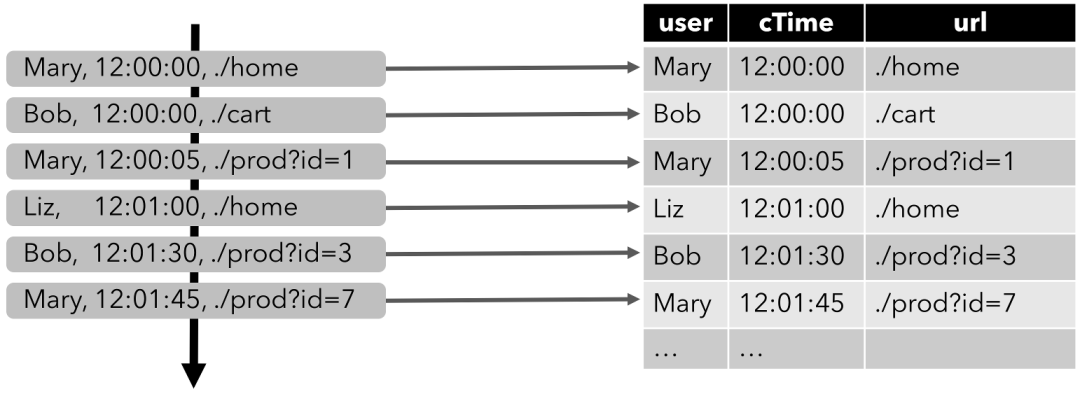
随着插入更多的访问事件流记录,生成的表将不断增长。
3.2 持续查询(Continuous Query)
持续查询,会在动态表上做计算处理,并作为结果生成新的动态表。与批处理查询不同,连续查询从不终止,并根据输入表上的更新更新其结果表。
在任何时间点,连续查询的结果在语义上,等同于在输入表的快照上,以批处理模式执行的同一查询的结果。
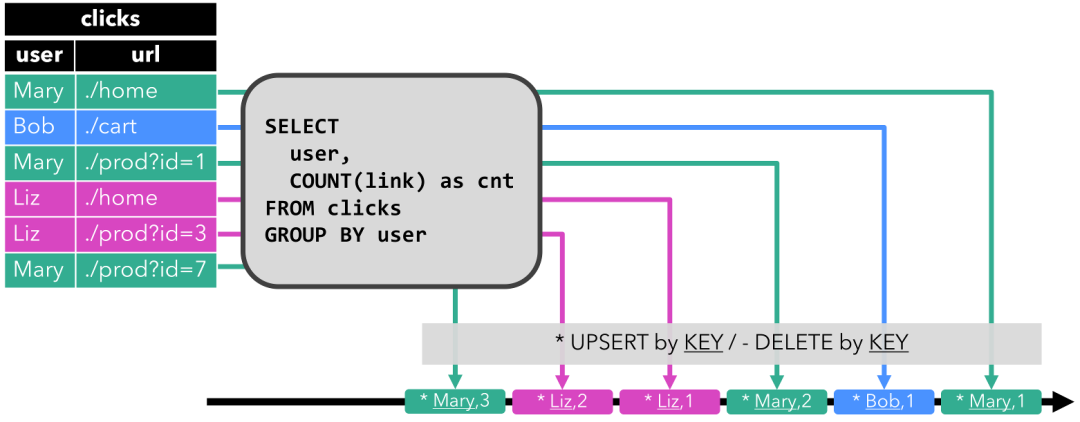
在下面的示例中,我们展示了对点击事件流中的一个持续查询。
这个Query很简单,是一个分组聚合做count统计的查询。它将用户字段上的clicks表分组,并统计访问的url数。图中显示了随着时间的推移,当clicks表被其他行更新时如何计算查询。
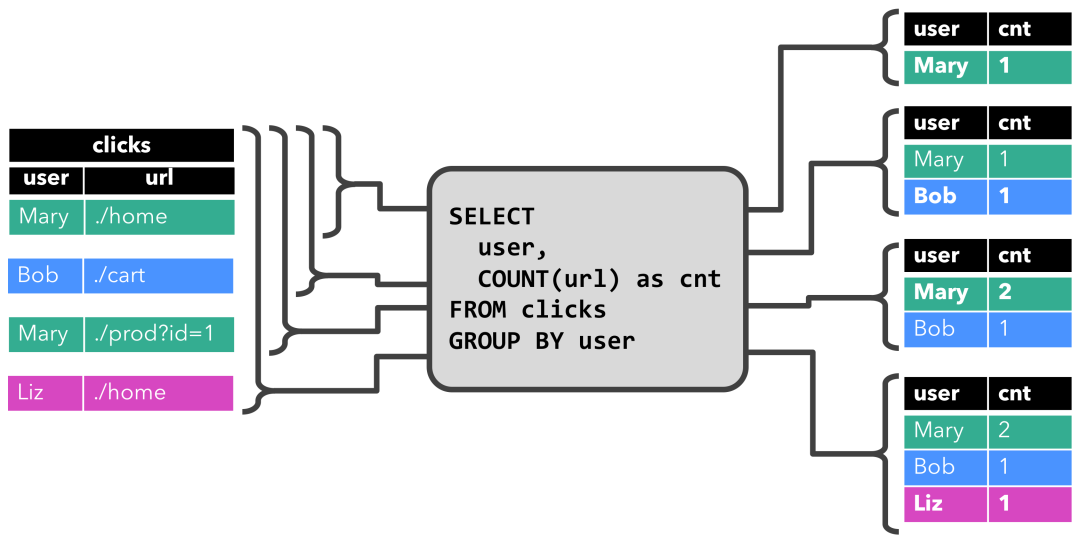
3.3 将动态表转换成流
与常规的数据库表一样,动态表可以通过插入(Insert)、更新(Update)和删除(Delete)更改,进行持续的修改。将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink的Table API和SQL支持三种方式对动态表的更改进行编码:
仅追加(Append-only)流
仅通过插入(Insert)更改,来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据,就是动态表中新增的每一行。
撤回(Retract)流
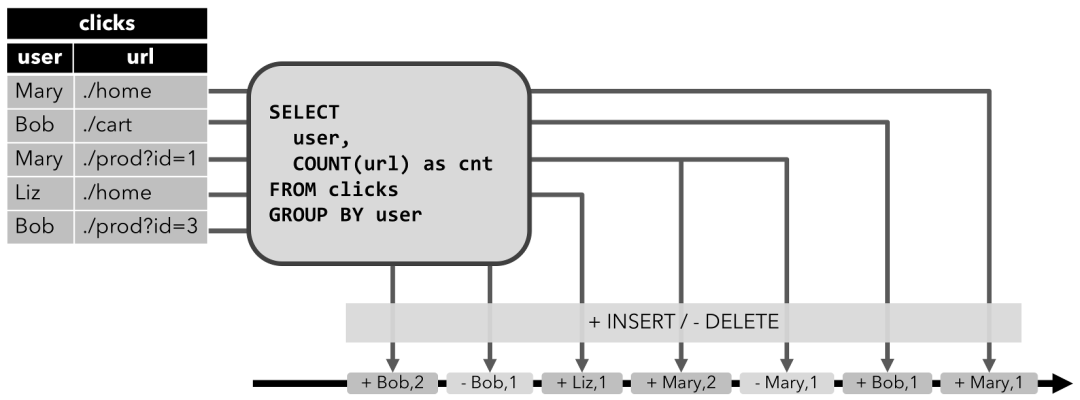
Retract流是包含两类消息的流,添加(Add)消息和撤回(Retract)消息。
动态表通过将INSERT 编码为add消息、DELETE 编码为retract消息、UPDATE编码为被更改行(前一行)的retract消息和更新后行(新行)的add消息,转换为retract流。
下图显示了将动态表转换为Retract流的过程。
Upsert(更新插入)流
Upsert流包含两种类型的消息:Upsert消息和delete消息。转换为upsert流的动态表,需要有唯一的键(key)。
通过将INSERT和UPDATE更改编码为upsert消息,将DELETE更改编码为DELETE消息,就可以将具有唯一键(Unique Key)的动态表转换为流。
下图显示了将动态表转换为upsert流的过程。
这些概念我们之前都已提到过。需要注意的是,在代码里将动态表转换为DataStream时,仅支持Append和Retract流。而向外部系统输出动态表的TableSink接口,则可以有不同的实现,比如之前我们讲到的ES,就可以有Upsert模式。
4 时间特性
基于时间的操作(比如Table API和SQL中窗口操作),需要定义相关的时间语义和时间数据来源的信息。所以,Table可以提供一个逻辑上的时间字段,用于在表处理程序中,指示时间和访问相应的时间戳。
时间属性,可以是每个表schema的一部分。一旦定义了时间属性,它就可以作为一个字段引用,并且可以在基于时间的操作中使用。
时间属性的行为类似于常规时间戳,可以访问,并且进行计算。
4.1 处理时间
处理时间语义下,允许表处理程序根据机器的本地时间生成结果。它是时间的最简单概念。它既不需要提取时间戳,也不需要生成watermark。
定义处理时间属性有三种方法:在DataStream转化时直接指定;在定义Table Schema时指定;在创建表的DDL中指定。
DataStream转化成Table时指定
由DataStream转换成表时,可以在后面指定字段名来定义Schema。在定义Schema期间,可以使用.proctime,定义处理时间字段。
注意,这个proctime属性只能通过附加逻辑字段,来扩展物理schema。因此,只能在schema定义的末尾定义它。
代码如下:
val stream = env.addSource(new SensorSource)
val sensorTable = tableEnv
.fromDataStream(stream, $"id", $"timestamp", $"temperature", $"pt".proctime())
创建表的DDL中指定
在创建表的DDL中,增加一个字段并指定成proctime,也可以指定当前的时间字段。
代码如下:
val sinkDDL: String =
"""
|create table dataTable (
| id varchar(20) not null,
| ts bigint,
| temperature double,
| pt AS PROCTIME()
|) with (
| 'connector.type' = 'filesystem',
| 'connector.path' = 'sensor.txt',
| 'format.type' = 'csv'
|)
""".stripMargin
tableEnv.sqlUpdate(sinkDDL) // 执行 DDL
注意:运行这段DDL,必须使用Blink Planner。
4.2 事件时间(Event Time)
事件时间语义,允许表处理程序根据每个记录中包含的时间生成结果。这样即使在有乱序事件或者延迟事件时,也可以获得正确的结果。
为了处理无序事件,并区分流中的准时和迟到事件;Flink需要从事件数据中,提取时间戳,并用来推进事件时间的进展(watermark)。
DataStream转化成Table时指定
在DataStream转换成Table,schema的定义期间,使用.rowtime可以定义事件时间属性。注意,必须在转换的数据流中分配时间戳和watermark。
在将数据流转换为表时,有两种定义时间属性的方法。根据指定的.rowtime字段名是否存在于数据流的架构中,timestamp字段可以:
作为新字段追加到schema
替换现有字段
在这两种情况下,定义的事件时间戳字段,都将保存DataStream中事件时间戳的值。
代码如下:
val stream = env
.addSource(new SensorSource)
.assignAscendingTimestamps(r => r.timestamp)
// 将 DataStream转换为 Table,并指定时间字段
val sensorTable = tableEnv
.fromDataStream(stream, $"id", $"timestamp".rowtime(), 'temperature)
创建表的DDL中指定
事件时间属性,是使用CREATE TABLE DDL中的WARDMARK语句定义的。watermark语句,定义现有事件时间字段上的watermark生成表达式,该表达式将事件时间字段标记为事件时间属性。
代码如下:
val sinkDDL: String =
"""
|create table dataTable (
| id varchar(20) not null,
| ts bigint,
| temperature double,
| rt AS TO_TIMESTAMP( FROM_UNIXTIME(ts) ),
| watermark for rt as rt - interval '1' second
|) with (
| 'connector.type' = 'filesystem',
| 'connector.path' = 'file:///D:\\..\\sensor.txt',
| 'format.type' = 'csv'
|)
""".stripMargin
tableEnv.sqlUpdate(sinkDDL) // 执行 DDL
这里FROM_UNIXTIME是系统内置的时间函数,用来将一个整数(秒数)转换成“YYYY-MM-DD hh:mm:ss”格式(默认,也可以作为第二个String参数传入)的日期时间字符串(date time string);然后再用TO_TIMESTAMP将其转换成Timestamp。
未完待续。

你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构&、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。