
并发与并行
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 南风知我不易
来源 | urlify.cn/NjuEbe
学习并发编程之初好像就一直对这个问题含混不清,在阅读《Java8实战》以及网络资源的时候对这个问题有了更进一步的认识,特此梳理一下
什么是并发、并行?
这里引用Java8实战中的一张图片来加以说明
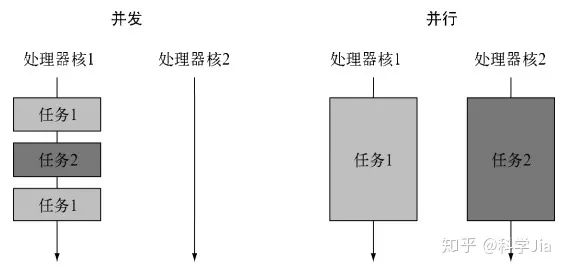
可能从上图简单来看,并发是单处理器核心多任务的交替执行,并行是多任务多处理器核心的同时执行,由于这个问题并没有被盖棺定论规范化,导致可能不同的人有不同的理解,我也并不能给出一个严格意义上准确的定义,但是我综合他人的观点给出的自己的定义如下,并行是并发的一种表现形式,并发只强调两个任务的生命周期存在交集,即对用上面的任务1开始到结束的过程中,如果任务2也开始了,那么我们就认为任务1和任务2是并发的。但是今天想梳理的并不是严格意义上的区分这两个关联紧密的概念,而是讨论这两者能够给我们的程序带来什么?
并发更加侧重于压榨单个CPU的性能,降低任务平均时延,对于一串任务(task1,task2,task3...)高并发并不能加快这些任务总体完成的时间,甚至由于线程切换还会延长任务总体完成的时间,所以它并不是以提高整体响应速率为目的的,而并行它使得多个任务(任务之间不相干,简化讨论,避免多核之间的一致性要求)可以在多个处理器核中得到真正的同时处理,而这个时候对于一系列的不相干任务来说,利用并行计算,就能大大缩短整体的响应时间
单线程并发能够提高任务的总体处理速度嘛?
答案是显然的,不能,而且由于线程切换带来的资源开销,单线程并发还会延长整个任务的处理时间?
单线程并发还有必要嘛?
有必要,而且非常有必要,首先我们假定有四个任务1,2,3,4如下,每个任务的执行耗时1个单位时间,如果按照单线程串行的执行方式,它应该是这样的

对于task1来说,它还能接收,毕竟执行1个单位时间它就拿到了它想要的结果,但是对于后面的task来说就不满意了,特别是task4来说,执行task4的耗时为1个单位时间,但是它需要等4个单位时间才能拿到结果,如果在多线程情况下,它是如何的呢?假设每个task都另起了一个线程,且不考虑操作系统任务调度耗时等等,现在的处理情况是这样的
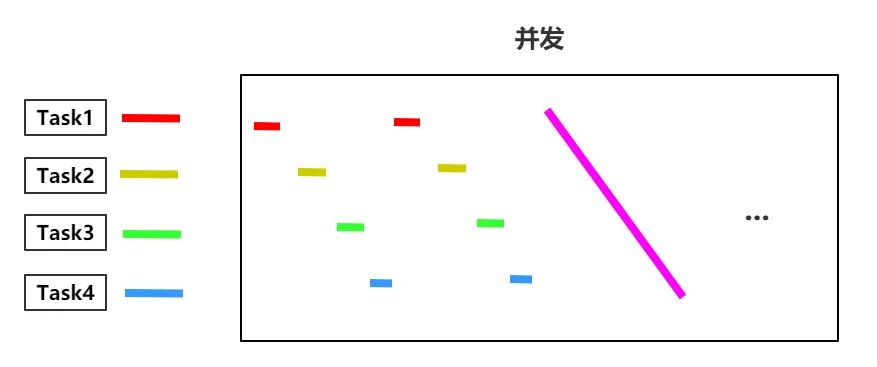
假如理想状况下,每个任务被切割得足够小,那么最终每个任务几乎是同时开始同时结束,那么每个task的用时就是总耗时的平均值也就是2.5,这下task4总算开心了,它不用等那么久了。
但是实际问题中,不可能把任务无限切分,操作系统的线程调度也是耗时操作,那么上面的结论就不一定那么可靠了,甚至可能每个时间都超过3了,那还不如串行呢,至少task1和task2爽了,那为什么还需要并发呢?
因为实际状况下,每个任务的执行速度也不可能完全相等,每个任务执行的速度有快有慢,我们现在假设task1执行用时需要1000个单位时间,如果在串行情况下,task1后面的所有任务都会被task1所拖累,需要等待的时间为1000加,而此时的并发执行策略中,虽然由于系统调度等等开销,task2,3,4仍然可以以一个与之前速度相差无几的时间响应,task1带来的恶劣影响也单单只影响到了自己。我们上面的策略也就类似于tomcat对于请求的处理策略,针对每个请求都另起一个线程(processor)来处理。
tomcat都这么厉害了,自己的代码中还有必要多线程嘛?
有必要,通常一个大任务是由多个小任务组合而成,如果按照CPU密集型和I/O密集型来划分任务类型的话,对于CPU密集型任务来说,无论我们再怎么多线程疯狂操作也好,在单核处理器中,最终都还是依靠单核来做运算,多线程的线程切换开销无疑延长了整个任务的处理时间,但是在I/O密集型任务情况下(包括磁盘IO,网络IO),假设你发起了10个不同的RPC调用,无疑多线程的方式能够让你同时发起多个请求,多个请求同时等待响应,否则你就只能按照串行的方式,每个请求都需要等一个时延,然后再处理下一个请求,这样的等待无疑延长了总体响应时间,降低CPU利用率。其实这样的并发就包含了并行,因为你发起的远程调用是远方的多个处理器去帮你处理的,我们所做的只不过是利用并发在一个请求傻等着的过程中又发起了另一个请求罢了
并行
并行的好处是显而易见的,多个处理器干活肯定是快于一个人干活的,对于上面讨论的情况,如果在多核心的处理器下,并发之后可能整个处理过程就是并行的,小的任务可以在多个处理器核心中同时运行,在这里也不太过多讨论并发安全的问题,主要讨论如何高效并行
在tomcat中想要并行很简单,你并发就好,如果你有多个处理器核心它自然会并行执行,可能并不太需要我们对整个处理过程进行并行处理,关注更多的是不同请求之间的并行,但是在一些场景下,可能就需要我们关注整个任务本身的并行,这时候并行就不那么容易,假设你要计算1-1000000000的和,你当然可以选择并发执行,自己分割每个处理器计算多少到多少的和,然后自行汇总结果,就像下面的代码一样
public class ConcurrentVsParallel {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//串行
long sum=0;
long time1=System.currentTimeMillis();
for (long i = 1; i <= 10000000000L; i++) {
sum+=i;
}
System.out.println("串行计算结果为:"+sum);
System.out.println("串行耗时:"+(System.currentTimeMillis()-time1));
long time2= System.currentTimeMillis();
long res = concurrentCal(10000000000L);
System.out.println("计算结果为:"+res);
System.out.println("并行耗时为:"+(System.currentTimeMillis()-time2));
}
public static long concurrentCal(final long n) throws ExecutionException, InterruptedException {
//4等分来处理
ExecutorService executor = Executors.newFixedThreadPool(4);
long quarter=n/4;
long allSum=0;
Future[] parts = new Future[4];
for (int i = 0; i < 4L; i++) {
final int temp=i;
Future partSum = executor.submit(() -> {
long sum = 0;
for (long j = temp * quarter + 1; j <= (temp + 1) * quarter; j++) {
sum += j;
}
return sum;
});
parts[i]=partSum;
}
for (int i = 0; i < parts.length; i++) {
allSum+=(long)parts[i].get();
}
return allSum;
}
}
输出结果如下:
串行计算结果为:-5340232216128654848
串行耗时:4617
计算结果为:-5340232216128654848
并行耗时为:1847
上述的代码能够实现我们既定的目标,但是存在着可读性和可拓展性的问题,性能也存在着问题,如果需要对(2-n)求和呢,很简单,给我们的代码加入一个start即可,但是如果需要对(2-n)中所有的偶数求和呢?岂不是又需要改代码,更加严重的问题是任务规模的划分是定下来的,导致任务划分的粒度有的时候并不够,当然你也可以再添加一个参数设置任务规模的划分,但是上述这些操作都会导致代码的膨胀和难以维护,利用java8的Stream可以做如下简单实现
long time3=System.currentTimeMillis();
long res = LongStream.rangeClosed(1, 10000000000L).parallel().sum();
System.out.println("stream计算结果为:"+res);
System.out.println("stream耗时为:"+(System.currentTimeMillis()-time3));
结果如下:
串行计算结果为:-5340232216128654848
串行耗时:4631
stream计算结果为:-5340232216128654848
stream耗时为:3605
虽然这里的耗时可能比不过我们直接手动划分,并发的方式去进行计算,但是这里的代码可读性以及可拓展性是非常好的,如果你想过滤掉所有的奇数,加一个filter就好。诚然这个结果也受限于我仅仅只有四核的垃圾笔记本,无论如何,通过Stream的方式,Java的并行计算也变得简单!
粉丝福利:Java从入门到入土学习路线图
???

?长按上方微信二维码 2 秒
感谢点赞支持下哈 