
CVPR2021 最具创造力的那些工作成果!或许这就是计算机视觉的魅力!

极市导读
CVPR2021 最具创造力的那些工作成果! >>加入极市CV技术交流群,走在计算机视觉的最前沿
CVPR 2021 Tutorial 《Unlocking Creativity with Computer Vision: Representations for Animation, Stylization and Manipulation》直译:用计算机视觉释放创造力:动画、造型和操纵的表现。
主页:https://snap-research.github.io/representations-for-creativity/

简介和目录
什么是创造力(Creativity)!
创造力——运用想象力和独创性想法进行创作的能力——需要掌握各种技能、可用的创造性工具、大量的努力,最重要的是要有创造性的头脑。物体的风格化或编辑要求艺术家理解物体的结构和变化因素。动画还需要了解对象的刚性和非刚性运动模式。这种复杂的操作可以通过使用具有合适表征的计算机视觉系统来实现。
我们将引导参会者通过设计和学习来构建创造性工具。选择正确的表征方式并建立一个学习框架往往是释放创造力的关键。我们将研究2D和体积对象表征、图像和视频表征、内容、样式和运动表征。当标记数据可用时,可以以有监督的方式学习某些表征,否则可以采用自我监督。此外,我们还区分了显式可解释表征和隐式表征。我们的研究表明,更好的表征可以更好地理解数据,进而提高生成内容的质量,最终形成良性循环。
会议组织者:

主要内容包括下面三个主题,每个主题又细分多个分支:
一、Representations for controllable image synthesis(可控图像合成的表征方法)
二、Object representations for manipulation (用于操纵的对象表征方法)
三、Content and motion representations for video synthesis animation (用于视频合成动画的内容和运动表征)
一、Representations for controllable image synthesis
可控图像合成的表征方法包含下面三部分:
A Brief Introduction to Deep Generative Models Recent Advances in Semantic Image Synthesis Image Outpainting
1、A Brief Introduction to Deep Generative Models
汇报人:Stéphane Lathuilière 主页:http://stelat.eu/
作者简介:法国巴黎电信公司(Telecom Paris, France)多媒体团队的副教授。研究方向:回归问题的深度学习、图像和视频生成以及有限数据的学习(无监督领域自适应、自监督学习、持续学习)
摘要:本视频简要介绍了深层生成模型。在本教程中,将介绍几种用于图像和视频生成或操作的计算机视觉方法。本演示的目的不是对有关深层生成模型的文献进行全面的回顾,而是简要介绍本教程中介绍的大多数方法将采用的关键方法。

2、Recent Advances in Semantic Image Synthesis 语义图像合成研究进展
汇报人:Ming-Yu Liu 主页:http://mingyuliu.net/
作者简介:杰出的研究科学家和英伟达研究公司的经理。研究小组专注于深层生成模型及其应用。我们在视觉内容合成领域创作了多部极具影响力的研究作品,包括pix2pixHD、vid2vid、MoCoGAN、face-vid2vid、SPADE、GANcraft。
在这篇演讲中,我回顾了最近几年的语义图像合成工作。我把他们放在同一个角度,并说明了架构的变化。对训练这两个模型的两个主要目标函数进行了讨论和比较。
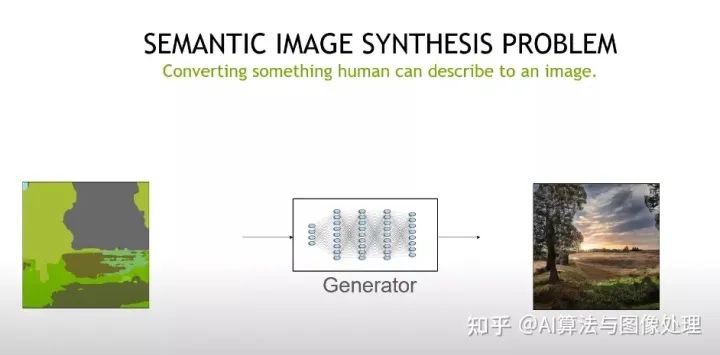
3、Image Outpainting 图像输出
汇报人:Hsin-Ying Lee 主页:http://hsinyinglee.com/
作者简介:Creative Vision team at Snap Research的研究科学家。于2020毕业于美国墨尔本大学ECES,获Ming Hsuan Yang教授的指导,于2016毕业于加利福尼亚南部大学电机工程系,获台湾大学电气工程系学士学位。
摘要:图像输出的目的是对给定的图像进行任意方向的外推。这项任务需要了解环境的结构和质地。现有的方法将任务建模为一个图像到图像的转换任务,由于强条件上下文的存在,会导致重复和单调的输出结果。在这篇演讲中,我将首先介绍如何利用GAN反转技术来实现多样化和可控的图像输出。接下来,为了更进一步,我将介绍我们解决一个更基本问题的尝试,即生成模型能否合成结构和纹理一致的无限分辨率图像。结合GAN反转技术,证明了该结构在图像输出任务中的有效性。

二、Object representations for manipulation
用于操纵的对象表征方法包含下面三个主题:
Manipulating Hair Face Stylization Volumetric Implicit Representations for Object Manipulation
1、Manipulating Hair 发型编辑
汇报人:Kyle Olszewski 主页:http://hsinyinglee.com/
作者简介:南加州大学的学生,在Hao Li教授的几何捕获实验室工作。研究方向:实时面部表情跟踪,特别是使用适合新兴平台的技术,如虚拟和增强现实。
摘要:从无约束图像中获取、绘制和操纵头发的结构和外观是近十年来计算机视觉和图形学界广泛关注的问题。随着神经渲染技术的出现,这一领域的进展大大加快,它可以在用户输入的指导下,在真实图像中实现高质量的头发合成,而不依赖于传统的头发重建技术或渲染管道。在本次演讲中,我们将讨论这一领域的一些最新工作,重点讨论它们如何解决关键问题,例如如何表示头发的形状和外观,可以使用什么类型的数据(真实的和合成的)来训练这些系统,以及它们可以启用什么类型的用户输入和编辑操作。我们展示了如何使用各种技术,从基于示例的合成到适合新手用户的发型的细粒度局部编辑,在真实的面部图像中交互式地合成和编辑各种发型的合理图像和视频。
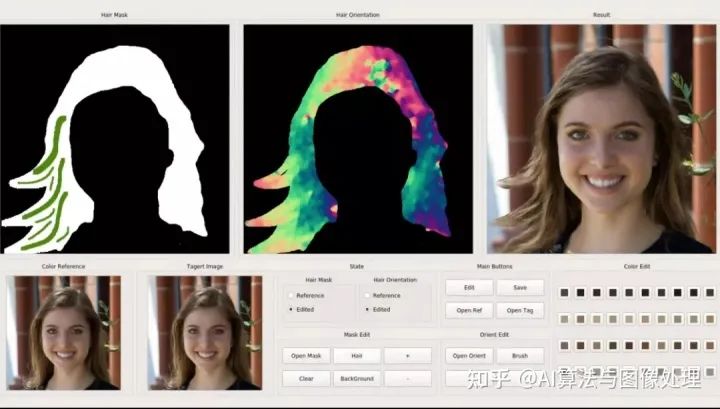
2、Face Stylization 人脸风格化
汇报人:Menglei Chai 主页:https://mlchai.com/
作者简介:Snap Research创意愿景小组的高级研究科学家。我拿到。浙江大学的图形与并行系统实验室(GAP)的博士学位,由坤舟教授监督。我从事计算机视觉和计算机图形学的研究,主要研究人类数字化、图像处理、三维重建和基于物理的动画
摘要:人脸风格化使各种视觉和图形应用成为可能。这项任务需要理解内容/风格的表示以及人脸的语义结构。虽然现有的方法能够在单张人脸图像上获得高质量的结果,但是人脸样式化可以进一步扩展,以消除更多创造性用例的阻碍。在这篇演讲中,为了将问题扩展到自动图像样式化之外,我们将讨论几个有趣的维度,例如视频样式化、几何样式化和三维可控样式化。在每一个方向上,我们都会介绍最新的代表性作品和我们的尝试,包括一个交互式视频风格化系统,它允许通过关键帧进行高保真的艺术控制,一个用于三维人脸风格化的联合外观和几何优化框架,提出了一种跨域三维引导的人脸操作方法,该方法可以利用人脸的先验信息编辑样式化的图像。

3、Volumetric Implicit Representations for Object Manipulation
汇报人:Kyle Olszewski 主页:https://kyleolsz.github.io/
摘要:近年来,图像内容的隐式表示在新视图合成(NVS)和三维重建等任务中显示出巨大的潜力。然而,在生成高质量的编辑图像的同时,使用这种表示来实现对该内容的可控的、3D感知的操作仍然是一个挑战。在这篇演讲中,我们描述了一种方法来解决这个问题使用编码器-解码器NVS框架。这个网络学习从一个图像中推断出一个物体的隐式体积表示作为它的瓶颈。尽管在训练期间没有使用3D监控,但是这种方法的空间解纠缠允许通过对体积瓶颈执行相应的3D变换来对所描绘的对象进行任意的空间操作。我们展示了各种应用,包括新颖的视图合成、三维重建和非刚性变换以及图像内容的组合。
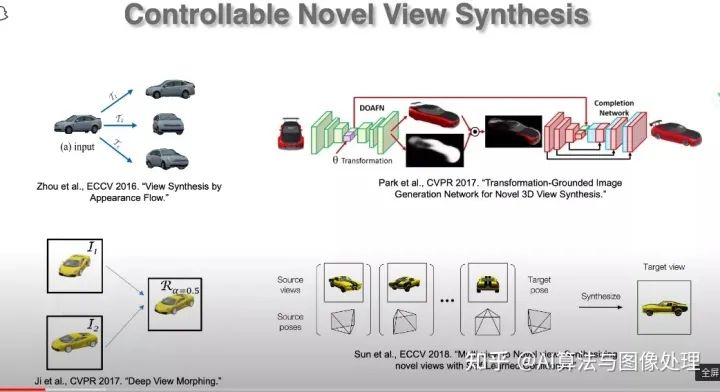
三、Content and motion representations for video synthesis animation
用于视频合成动画的内容和运动表征包含下面四个主题:
Video Synthesis and Manipulation Self-supervised Image Animation Supervised and Few-shot Animation Representations for Modeling Human Bodies
1、Video Synthesis and Manipulation 视频合成与处理
汇报人:Sergey Tulyakov 主页:http://www.stulyakov.com/
作者简介:Snap Research创新愿景团队的首席研究科学家。工作重点是通过计算机视觉和机器学习创造操纵世界的方法。这包括样式转换、真实感对象操作和动画、视频合成、预测和重定目标。
摘要:在本视频中,我们将讨论几种视频生成模型,如MoCoGAN和MoCoGAN HD,我们将了解这些方法背后的直觉,以及一些重要的实现细节。此外,我们将在视频生成领域引入一个新的领域,称为可播放视频生成,它允许对视频内容进行可控和交互式操作。
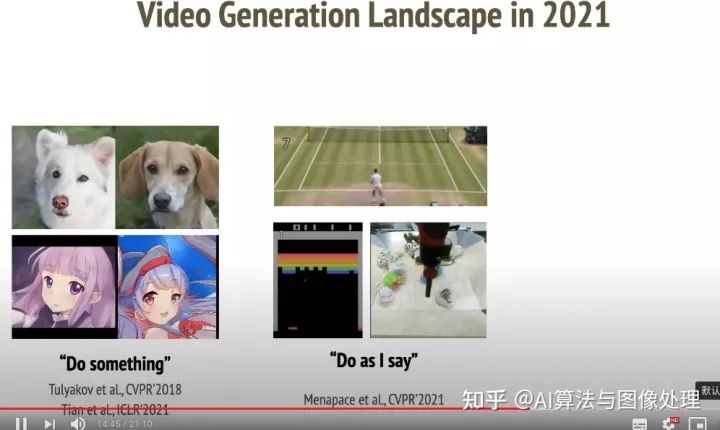
2、Self-supervised Image Animation 自监督图像动画
汇报人:Aliaksandr Siarohin 主页:http://www.stulyakov.com/
作者简介:特伦托大学的博士生,我在NICU SEBE的监督下工作,在多媒体和人类理解小组(MCOP)。研究方向包括机器学习的图像动画,视频生成,生成对抗网络和领域适应。
摘要:在这个讲座中,我们提出了一套无监督图像动画的方法。图像动画的任务是生成一个视频,其中来自源图像的对象像来自另一个驱动视频的对象一样移动。无监督动画的主要区别在于,它只需要一组训练视频,而不需要关于这些视频中对象的任何其他先验知识。

3、Supervised and Few-shot Animation 监督和少样本动画
汇报人:Jian Ren 主页:https://alanspike.github.io/
作者简介:研究科学家,在Snap公司的Creative Vision小组工作。在加入Snap公司之前,我曾在Adobe、Snap公司和Bytedance Research担任研究实习生。
摘要:**人体运动重定目标的目的是将源驱动视频中的运动信息传递给目标参考人,从而在对源驱动视频进行运动处理的同时合成包含目标人内容的真实感视频。**在这篇演讲中,我们将首先介绍专注于有监督运动传输的工作,其中需要来自目标人的训练视频,并且专门设计了一个模型来为一个目标人生成视频。然后,我们将转向使用目标人物的一个或几个图像来生成运动视频。通过少量镜头设置训练的模型可以合成任意人的视频。

4、Representations for Modeling Human Bodies 人体建模的表征方法
汇报人:Zeng Huang 主页:https://alanspike.github.io/
作者简介:Snap研究公司的研究科学家。我主要从事计算机图形学、三维视觉和深度学习。的研究工作都是围绕着虚拟人的数字化,将几何处理和深度学习结合起来,针对每个人都可以访问的尖端AR/VR应用程序。
摘要:研究人体是人类历史上一个长期的课题。自信息时代以来,人体数字化一直是计算机图形学和动画领域的一个重要研究方向。虽然高质量的人体扫描和视觉效果已经在电影行业得到了广泛的应用,但低成本和方便的人体数字化仍然是一个挑战。随着人们对这一领域的深入学习,最近有了一些令人兴奋的工作,并真正推动了这一任务的边界。在这次演讲中,我们将介绍近年来数字化全身穿着人类的研究成果。特别是,我们将回顾最近使用隐式函数表示身体几何体的尝试,以及它与动画管道和实时实现的结合。

参考论文链接
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
