
李宏毅:让我们一起朝AI训练师迈进

于是,我找到了一份从第一代到第七代共801只宝可梦的数据集,跃跃欲试打算大展身手。实践环境用的是阿里云的DSW平台,主要好处是无需安装环境、提供免费计算资源,但用的人多就会比较慢。现在,开启宝可梦训练师的数据分析之路。
一、数据准备及读取
!wget -O pokemon_data.csv https://pai-public-data.oss-cn-beijing.aliyuncs.com/pokemon/pokemon.csvimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltdf = pd.read_csv("./pokemon_data.csv")
二、数据探索性分析
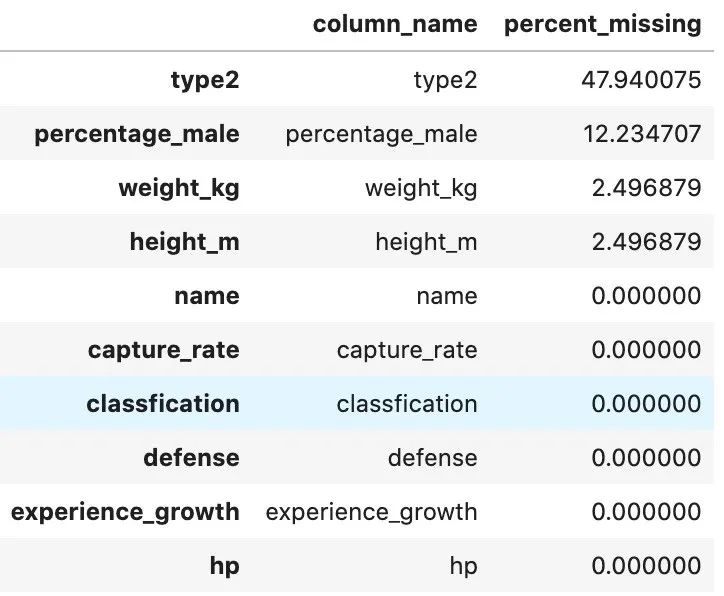
然后就迎来了我们的第一个问题:这么多特征,是否会有数据缺失呢?毕竟有些宝可梦比较神秘感,就连大木博士都不一定知道。这里我们可以通过如下代码来观察每个特征的缺失情况:
# 计算出每个特征有多少百分比是缺失的percent_missing = df.isnull().sum() *100/len(df)missing_value_df = pd.DataFrame({'column_name': df.columns,'percent_missing': percent_missing})# 查看Top10缺失的missing_value_df.sort_values(by='percent_missing', ascending=False).head(10)
然后第二个问题就是:这么多宝可梦,每代分别有几只?为了更加直观的表现出不同代的宝可梦的数量差别,这里我们可以用pandas自带的画图的功能来绘制一个柱状图:
# 查看各代口袋妖怪的数量df['generation'].value_counts().plot.bar()
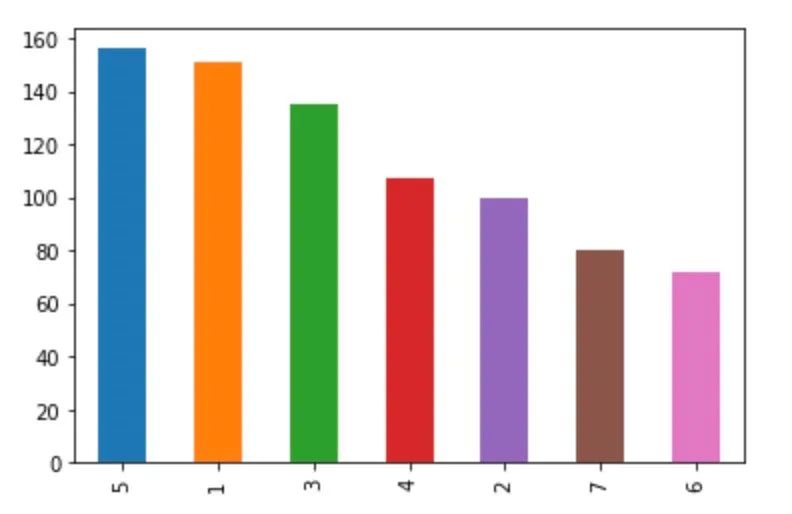
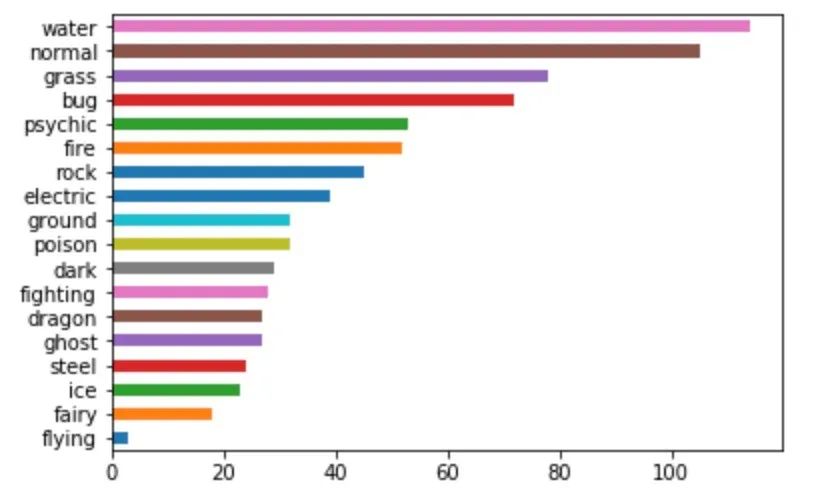
不难发现,宝可梦数量最多的是在第5代,最少的是在第6代。然后我们再来看不同的主属性的分布。这里我们可以先做一些简单的假设,比如虫属性的宝可梦种类比较多因为在剧中出现的频率相当高,而且有很多种进化。
# 查看每个系口袋妖怪的数量df['type1'].value_counts().sort_values(ascending=True).plot.barh()
看完了基础的一些分布,接下来我会想做一些简单的相关性分析。我们可以通过以下的代码生成相关性图,来了解不同特征之间的关联,这对我们了解宝可梦的特性很有帮助。
# 相关性热力图分析plt.subplots(figsize=(20,15))ax = plt.axes()ax.set_title("Correlation Heatmap")corr = df.corr()sns.heatmap(corr,xticklabels=corr.columns.values,yticklabels=corr.columns.values)

通过观察 attack 这一个特征和 height_m 是正相关的,我们可以得出:越高的宝可梦,攻击力越高。但是再看 height_m,我们会发现它和 base_happiness 是负相关的。这个时候我们可以作出另外一个结论:长得高的宝可梦可能都不太开心。
接下来我们从宝可梦在实战中的角度来分析这组数据。这里我们只关注六个基础值:血量,攻击力,防御力,特攻,特防,速度。因为在不考虑派系克制的情况下,只有这六个基础值决定了一只宝可梦的战斗力。
interested = ['hp','attack','defense','sp_attack','sp_defense','speed']sns.pairplot(df[interested])
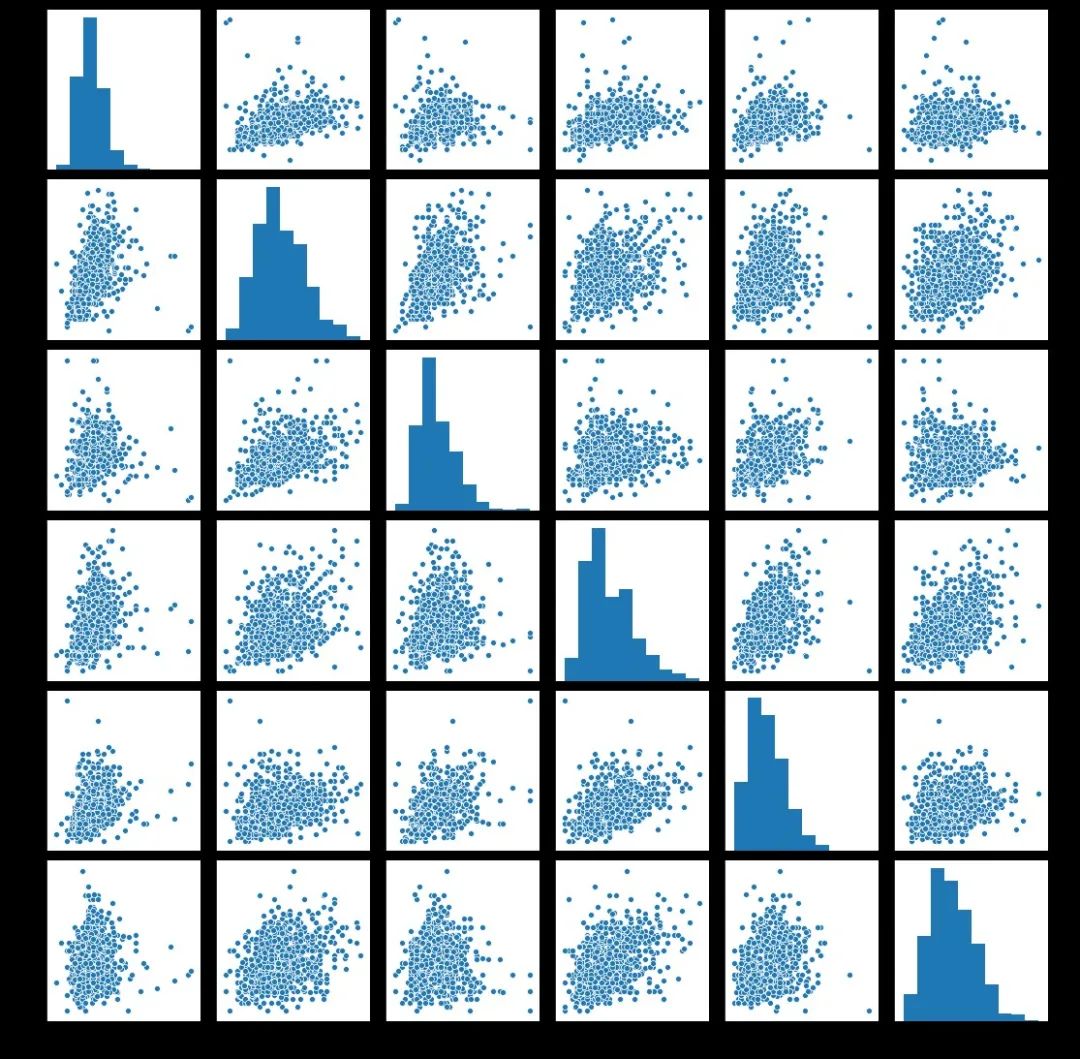
这里我们可以看到大部分都是成正比例的,一个值的提高往往会拉高另外一个值。这点我们通过相关性热力图也可以看到。
# 通过相关性分析heatmap分析五个基础属性plt.subplots(figsize=(10,8))ax = plt.axes()ax.set_title("Correlation Heatmap")corr = df[interested].corr()sns.heatmap(corr,xticklabels=corr.columns.values,yticklabels=corr.columns.values,annot=True, fmt="f",cmap="YlGnBu")
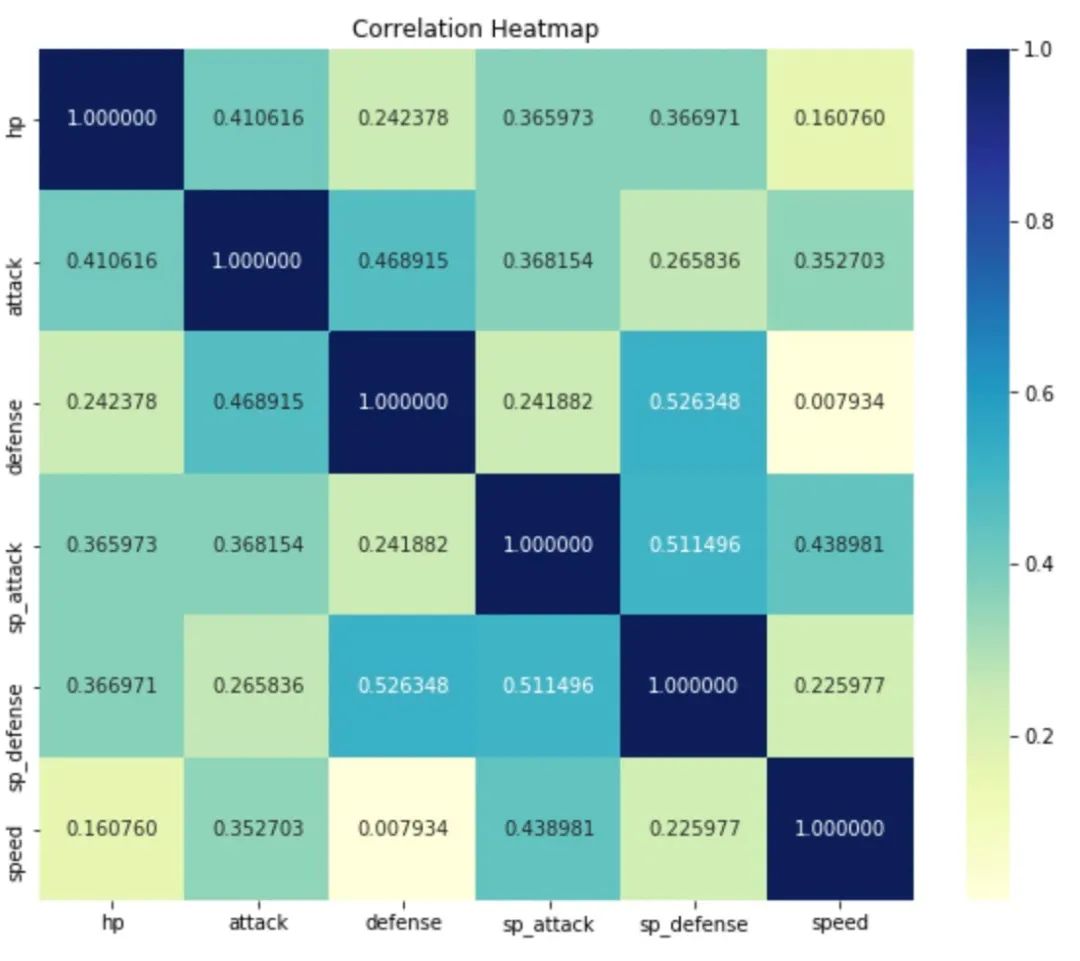
看完这些以后,我们就可以开始计算种族值然后来选取我们的平民神兽了。毕竟不是每个人都能收服代欧奇希斯,超梦,梦幻这种传说级别的宝可梦。这里我们可以通过如下方式,先做一个特征类型转化,然后再计算。
for c in interested:df[c] = df[c].astype(float)df = df.assign(total_stats = df[interested].sum(axis=1))
这样我们就完成了用total_stats这个字段来存储种族值这一特征。我们可以做个柱状图可视化来看看种族值的分布是什么样的:
# 种族值分布total_stats = df.total_statsplt.hist(total_stats,bins=35)plt.xlabel('total_stats')plt.ylabel('Frequency')
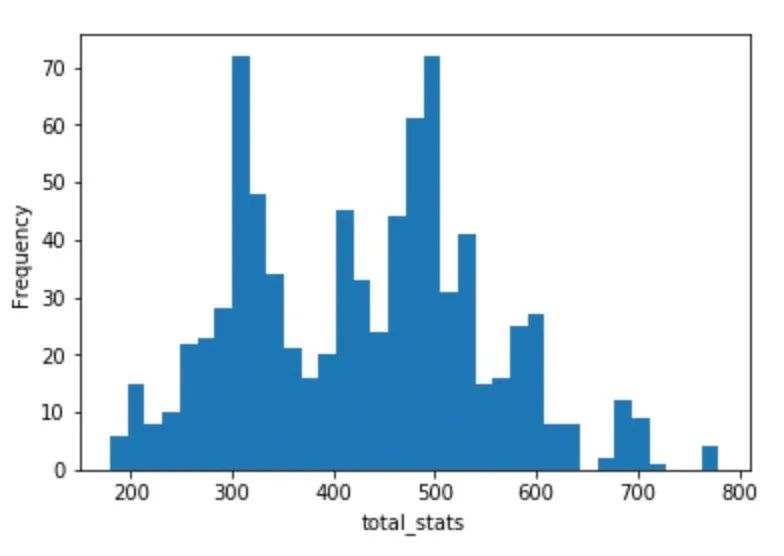
同时我们还可以根据不同的属性来看:
# 不同属性的种族值分布plt.subplots(figsize=(20,12))ax = sns.violinplot(x="type1", y="total_stats",data=df, palette="muted")
三、结论
最后我们就可以通过简单的过滤和排序来找到我们应该去捕捉的宝可梦了:
df[(df.total_stats>=570) & (df.is_legendary==0)]['name'].head(10)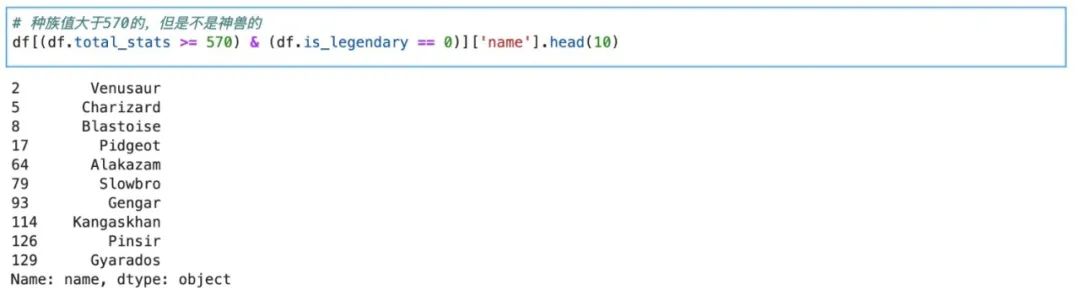
从结果上来看,平民宝可梦训练师应该考虑的Top10宝可梦应该是:妙蛙花,喷火龙,水箭龟,比雕,胡地,呆河马,耿鬼,袋兽,大甲,暴鲤龙。这样,我们就通过简单的数据分析,完成了大多数宝可梦动漫中的训练师不可能完成的任务。这么想想,升职加薪,出任CEO,赢取白富美,当上研究所所长的日子简直指日可待呀!